 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContact-Aided Invariant Extended Kalman Filtering for Robot State Estimation
Apr 19, 2019
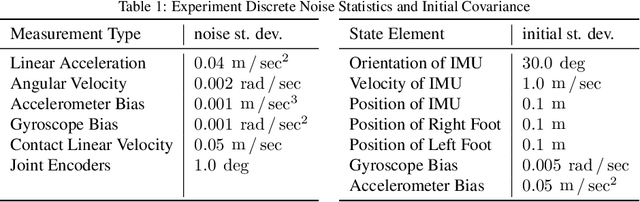
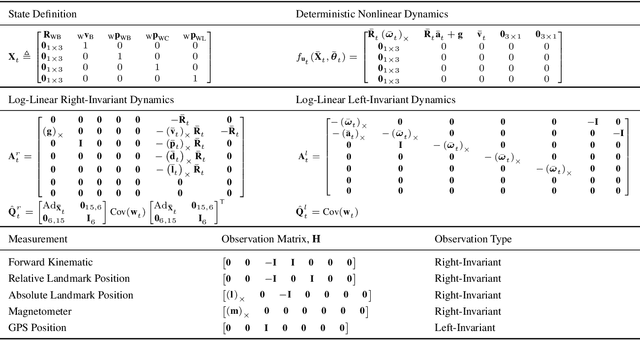
Legged robots require knowledge of pose and velocity in order to maintain stability and execute walking paths. Current solutions either rely on vision data, which is susceptible to environmental and lighting conditions, or fusion of kinematic and contact data with measurements from an inertial measurement unit (IMU). In this work, we develop a contact-aided invariant extended Kalman filter (InEKF) using the theory of Lie groups and invariant observer design. This filter combines contact-inertial dynamics with forward kinematic corrections to estimate pose and velocity along with all current contact points. We show that the error dynamics follows a log-linear autonomous differential equation with several important consequences: (a) the observable state variables can be rendered convergent with a domain of attraction that is independent of the system's trajectory; (b) unlike the standard EKF, neither the linearized error dynamics nor the linearized observation model depend on the current state estimate, which (c) leads to improved convergence properties and (d) a local observability matrix that is consistent with the underlying nonlinear system. Furthermore, we demonstrate how to include IMU biases, add/remove contacts, and formulate both world-centric and robo-centric versions. We compare the convergence of the proposed InEKF with the commonly used quaternion-based EKF though both simulations and experiments on a Cassie-series bipedal robot. Filter accuracy is analyzed using motion capture, while a LiDAR mapping experiment provides a practical use case. Overall, the developed contact-aided InEKF provides better performance in comparison with the quaternion-based EKF as a result of exploiting symmetries present in system.
Hybrid Contact Preintegration for Visual-Inertial-Contact State Estimation Using Factor Graphs
Oct 02, 2018
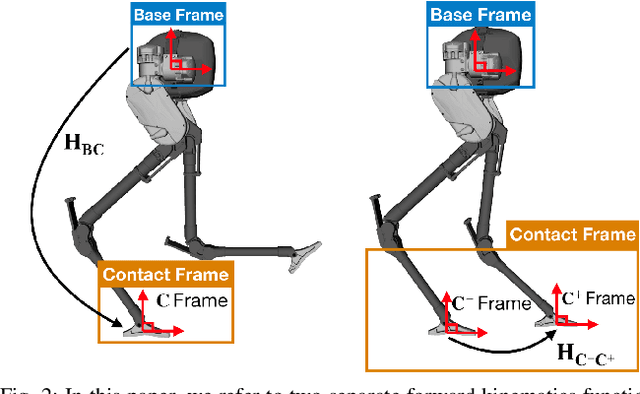
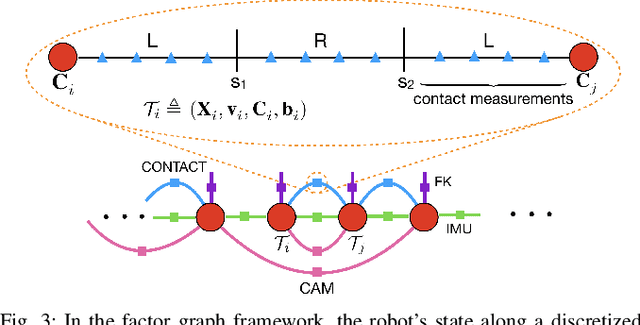
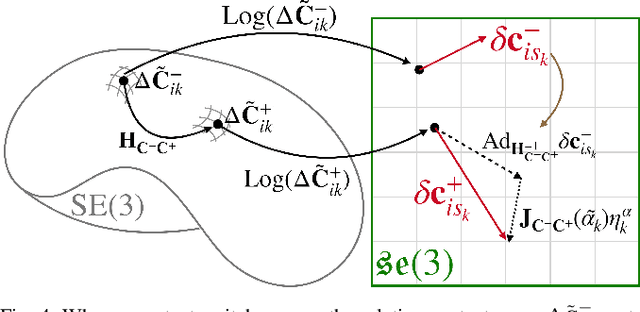
The factor graph framework is a convenient modeling technique for robotic state estimation where states are represented as nodes, and measurements are modeled as factors. When designing a sensor fusion framework for legged robots, one often has access to visual, inertial, joint encoder, and contact sensors. While visual-inertial odometry has been studied extensively in this framework, the addition of a preintegrated contact factor for legged robots has been only recently proposed. This allowed for integration of encoder and contact measurements into existing factor graphs, however, new nodes had to be added to the graph every time contact was made or broken. In this work, to cope with the problem of switching contact frames, we propose a hybrid contact preintegration theory that allows contact information to be integrated through an arbitrary number of contact switches. The proposed hybrid modeling approach reduces the number of required variables in the nonlinear optimization problem by only requiring new states to be added alongside camera or selected keyframes. This method is evaluated using real experimental data collected from a Cassie-series robot where the trajectory of the robot produced by a motion capture system is used as a proxy for ground truth. The evaluation shows that inclusion of the proposed preintegrated hybrid contact factor alongside visual-inertial navigation systems improves estimation accuracy as well as robustness to vision failure, while its generalization makes it more accessible for legged platforms.
Guaranteed Globally Optimal Planar Pose Graph and Landmark SLAM via Sparse-Bounded Sums-of-Squares Programming
Sep 20, 2018



Autonomous navigation requires an accurate model or map of the environment. While dramatic progress in the prior two decades has enabled large-scale simultaneous localization and mapping (SLAM), the majority of existing methods rely on non-linear optimization techniques to find the maximum likelihood estimate (MLE) of the robot trajectory and surrounding environment. These methods are prone to local minima and are thus sensitive to initialization. Several recent papers have developed optimization algorithms for the Pose-Graph SLAM problem that can certify the optimality of a computed solution. Though this does not guarantee a priori that this approach generates an optimal solution, a recent extension has shown that when the noise lies within a critical threshold that the solution to the optimization algorithm is guaranteed to be optimal. To address the limitations of existing approaches, this paper illustrates that the Pose-Graph SLAM and Landmark SLAM can be formulated as polynomial optimization programs that are sum-of-squares (SOS) convex. This paper then describes how the Pose-Graph and Landmark SLAM problems can be solved to a global minimum without initialization regardless of noise level using the sparse bounded degree sum-of-squares (Sparse-BSOS) optimization method. Finally, the superior performance of the proposed approach when compared to existing SLAM methods is illustrated on graphs with several hundred nodes.
Contact-Aided Invariant Extended Kalman Filtering for Legged Robot State Estimation
May 26, 2018
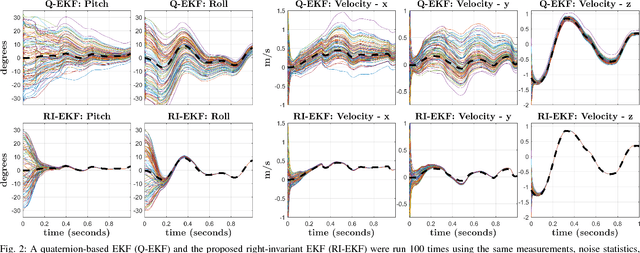
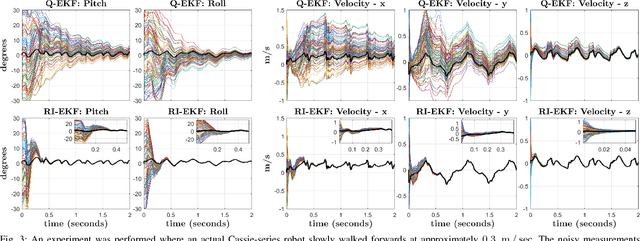
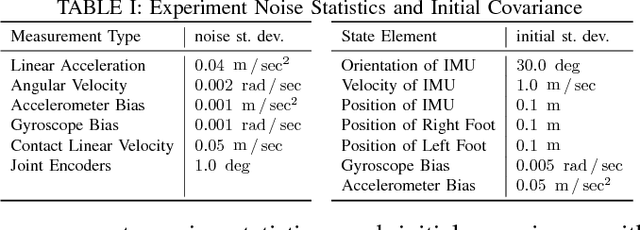
This paper derives a contact-aided inertial navigation observer for a 3D bipedal robot using the theory of invariant observer design. Aided inertial navigation is fundamentally a nonlinear observer design problem; thus, current solutions are based on approximations of the system dynamics, such as an Extended Kalman Filter (EKF), which uses a system's Jacobian linearization along the current best estimate of its trajectory. On the basis of the theory of invariant observer design by Barrau and Bonnabel, and in particular, the Invariant EKF (InEKF), we show that the error dynamics of the point contact-inertial system follows a log-linear autonomous differential equation; hence, the observable state variables can be rendered convergent with a domain of attraction that is independent of the system's trajectory. Due to the log-linear form of the error dynamics, it is not necessary to perform a nonlinear observability analysis to show that when using an Inertial Measurement Unit (IMU) and contact sensors, the absolute position of the robot and a rotation about the gravity vector (yaw) are unobservable. We further augment the state of the developed InEKF with IMU biases, as the online estimation of these parameters has a crucial impact on system performance. We evaluate the convergence of the proposed system with the commonly used quaternion-based EKF observer using a Monte-Carlo simulation. In addition, our experimental evaluation using a Cassie-series bipedal robot shows that the contact-aided InEKF provides better performance in comparison with the quaternion-based EKF as a result of exploiting symmetries present in the system dynamics.
Legged Robot State-Estimation Through Combined Forward Kinematic and Preintegrated Contact Factors
Feb 25, 2018
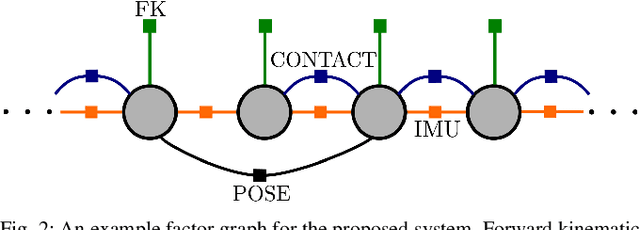
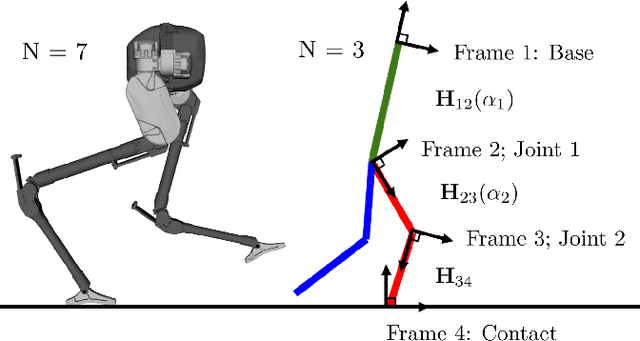
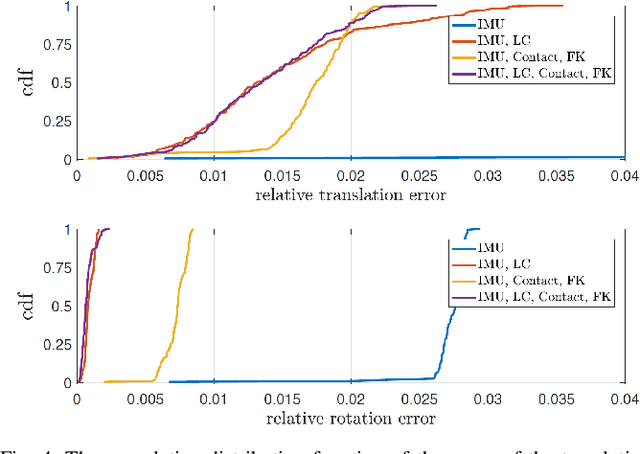
State-of-the-art robotic perception systems have achieved sufficiently good performance using Inertial Measurement Units (IMUs), cameras, and nonlinear optimization techniques, that they are now being deployed as technologies. However, many of these methods rely significantly on vision and often fail when visual tracking is lost due to lighting or scarcity of features. This paper presents a state-estimation technique for legged robots that takes into account the robot's kinematic model as well as its contact with the environment. We introduce forward kinematic factors and preintegrated contact factors into a factor graph framework that can be incrementally solved in real-time. The forward kinematic factor relates the robot's base pose to a contact frame through noisy encoder measurements. The preintegrated contact factor provides odometry measurements of this contact frame while accounting for possible foot slippage. Together, the two developed factors constrain the graph optimization problem allowing the robot's trajectory to be estimated. The paper evaluates the method using simulated and real sensory IMU and kinematic data from experiments with a Cassie-series robot designed by Agility Robotics. These preliminary experiments show that using the proposed method in addition to IMU decreases drift and improves localization accuracy, suggesting that its use can enable successful recovery from a loss of visual tracking.
WaterGAN: Unsupervised Generative Network to Enable Real-time Color Correction of Monocular Underwater Images
Oct 26, 2017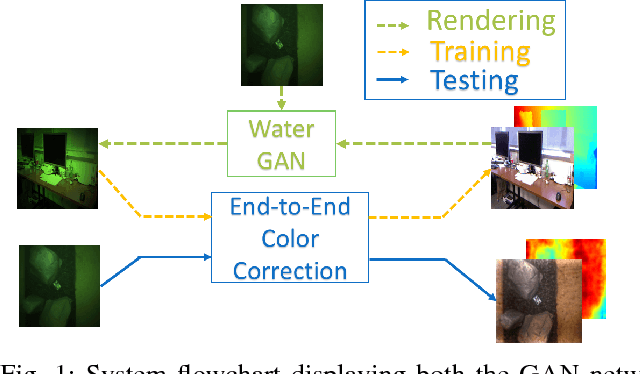
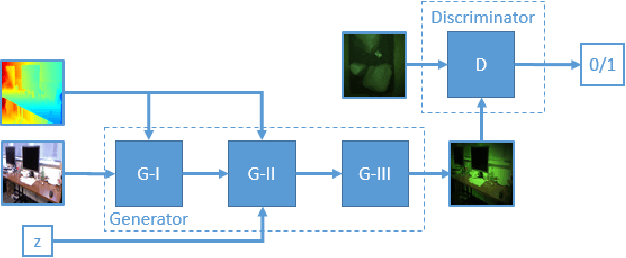
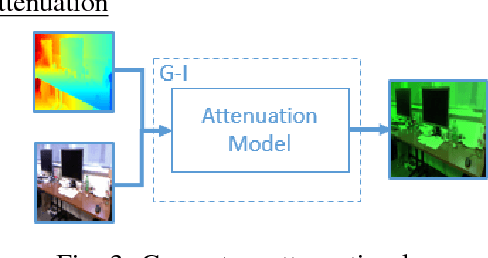
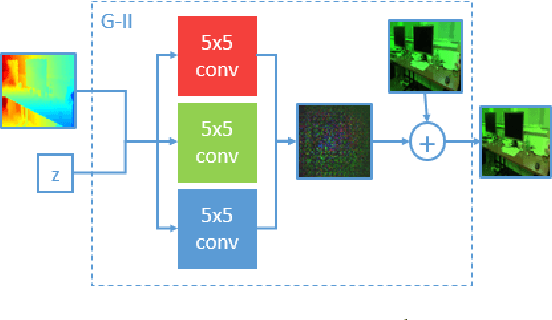
This paper reports on WaterGAN, a generative adversarial network (GAN) for generating realistic underwater images from in-air image and depth pairings in an unsupervised pipeline used for color correction of monocular underwater images. Cameras onboard autonomous and remotely operated vehicles can capture high resolution images to map the seafloor, however, underwater image formation is subject to the complex process of light propagation through the water column. The raw images retrieved are characteristically different than images taken in air due to effects such as absorption and scattering, which cause attenuation of light at different rates for different wavelengths. While this physical process is well described theoretically, the model depends on many parameters intrinsic to the water column as well as the objects in the scene. These factors make recovery of these parameters difficult without simplifying assumptions or field calibration, hence, restoration of underwater images is a non-trivial problem. Deep learning has demonstrated great success in modeling complex nonlinear systems but requires a large amount of training data, which is difficult to compile in deep sea environments. Using WaterGAN, we generate a large training dataset of paired imagery, both raw underwater and true color in-air, as well as depth data. This data serves as input to a novel end-to-end network for color correction of monocular underwater images. Due to the depth-dependent water column effects inherent to underwater environments, we show that our end-to-end network implicitly learns a coarse depth estimate of the underwater scene from monocular underwater images. Our proposed pipeline is validated with testing on real data collected from both a pure water tank and from underwater surveys in field testing. Source code is made publicly available with sample datasets and pretrained models.
* 8 pages, 16 figures, published by RA-letter 2018. Source code available at: https://github.com/kskin/WaterGAN
Sparse Bayesian Inference for Dense Semantic Mapping
Sep 22, 2017
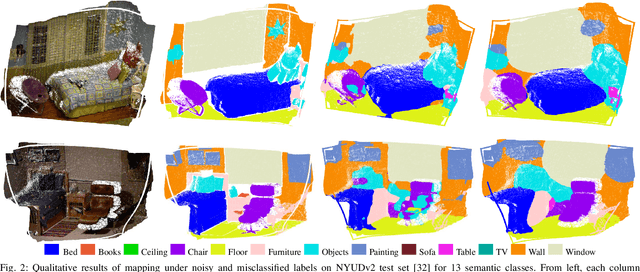
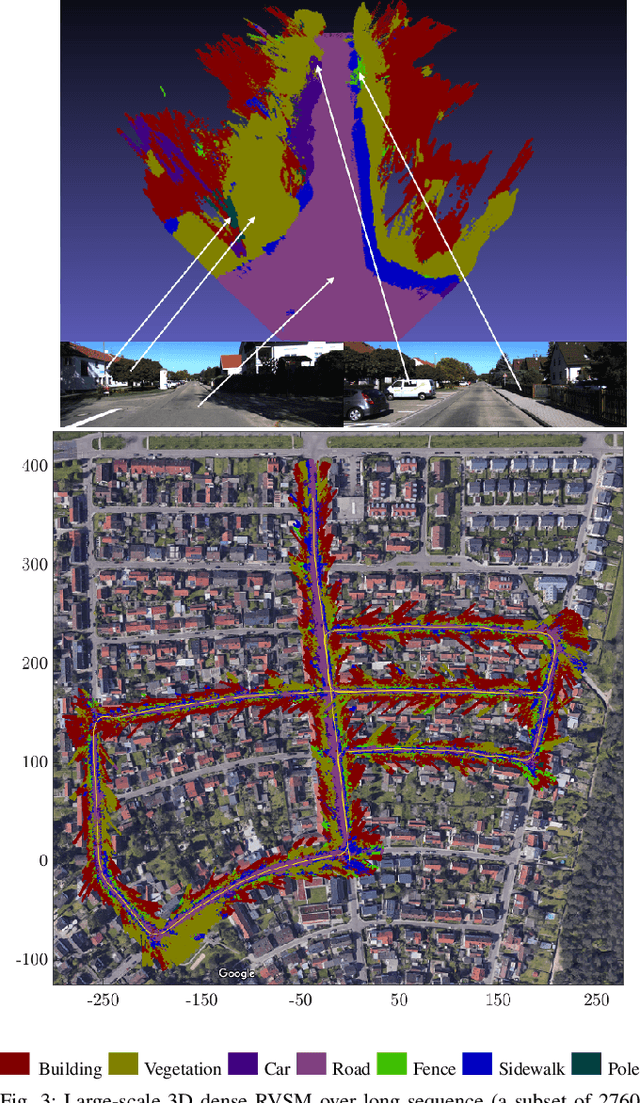
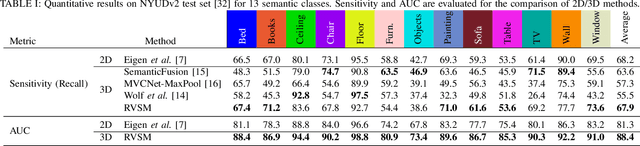
Despite impressive advances in simultaneous localization and mapping, dense robotic mapping remains challenging due to its inherent nature of being a high-dimensional inference problem. In this paper, we propose a dense semantic robotic mapping technique that exploits sparse Bayesian models, in particular, the relevance vector machine, for high-dimensional sequential inference. The technique is based on the principle of automatic relevance determination and produces sparse models that use a small subset of the original dense training set as the dominant basis. The resulting map posterior is continuous, and queries can be made efficiently at any resolution. Moreover, the technique has probabilistic outputs per semantic class through Bayesian inference. We evaluate the proposed relevance vector semantic map using publicly available benchmark datasets, NYU Depth V2 and KITTI; and the results show promising improvements over the state-of-the-art techniques.
Gaussian Processes Semantic Map Representation
Jul 05, 2017
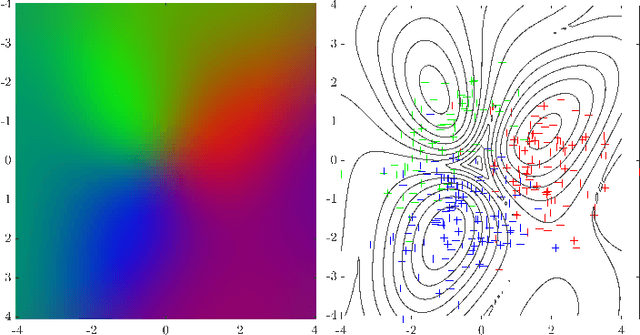


In this paper, we develop a high-dimensional map building technique that incorporates raw pixelated semantic measurements into the map representation. The proposed technique uses Gaussian Processes (GPs) multi-class classification for map inference and is the natural extension of GP occupancy maps from binary to multi-class form. The technique exploits the continuous property of GPs and, as a result, the map can be inferred with any resolution. In addition, the proposed GP Semantic Map (GPSM) learns the structural and semantic correlation from measurements rather than resorting to assumptions, and can flexibly learn the spatial correlation as well as any additional non-spatial correlation between map points. We extend the OctoMap to Semantic OctoMap representation and compare with the GPSM mapping performance using NYU Depth V2 dataset. Evaluations of the proposed technique on multiple partially labeled RGBD scans and labels from noisy image segmentation show that the GP semantic map can handle sparse measurements, missing labels in the point cloud, as well as noise corrupted labels.