 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePost Selection Inference with Incomplete Maximum Mean Discrepancy Estimator
Feb 17, 2018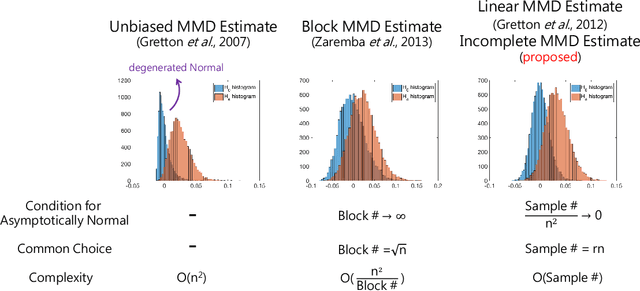

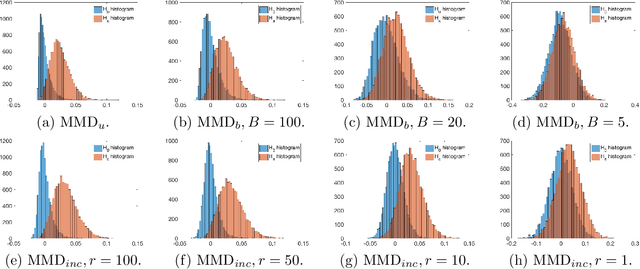
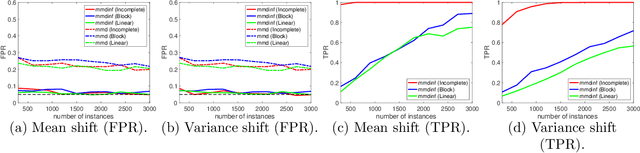
Measuring divergence between two distributions is essential in machine learning and statistics and has various applications including binary classification, change point detection, and two-sample test. Furthermore, in the era of big data, designing divergence measure that is interpretable and can handle high-dimensional and complex data becomes extremely important. In the paper, we propose a post selection inference (PSI) framework for divergence measure, which can select a set of statistically significant features that discriminate two distributions. Specifically, we employ an additive variant of maximum mean discrepancy (MMD) for features and introduce a general hypothesis test for PSI. A novel MMD estimator using the incomplete U-statistics, which has an asymptotically Normal distribution (under mild assumptions) and gives high detection power in PSI, is also proposed and analyzed theoretically. Through synthetic and real-world feature selection experiments, we show that the proposed framework can successfully detect statistically significant features. Last, we propose a sample selection framework for analyzing different members in the Generative Adversarial Networks (GANs) family.
"Dependency Bottleneck" in Auto-encoding Architectures: an Empirical Study
Feb 15, 2018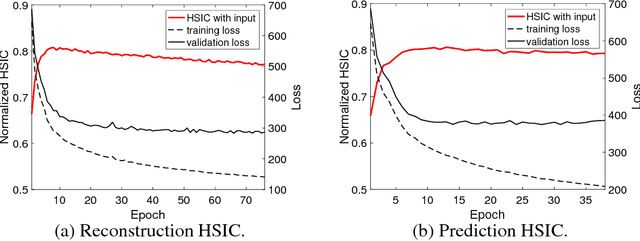
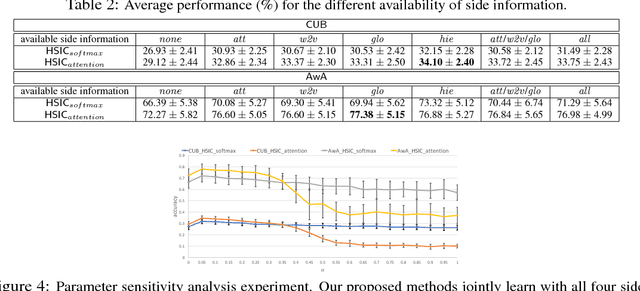
Recent works investigated the generalization properties in deep neural networks (DNNs) by studying the Information Bottleneck in DNNs. However, the mea- surement of the mutual information (MI) is often inaccurate due to the density estimation. To address this issue, we propose to measure the dependency instead of MI between layers in DNNs. Specifically, we propose to use Hilbert-Schmidt Independence Criterion (HSIC) as the dependency measure, which can measure the dependence of two random variables without estimating probability densities. Moreover, HSIC is a special case of the Squared-loss Mutual Information (SMI). In the experiment, we empirically evaluate the generalization property using HSIC in both the reconstruction and prediction auto-encoding (AE) architectures.
Discovering Order in Unordered Datasets: Generative Markov Networks
Feb 15, 2018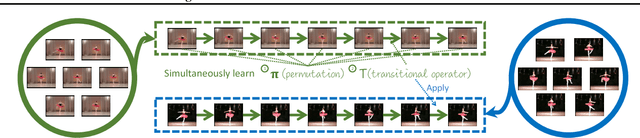
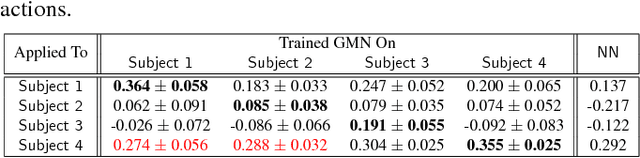

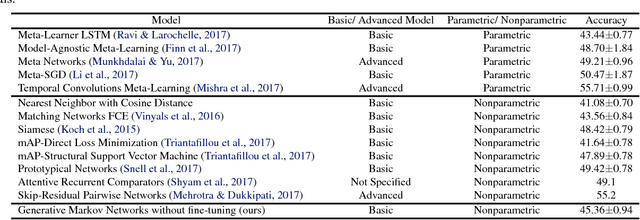
The assumption that data samples are independently identically distributed is the backbone of many learning algorithms. Nevertheless, datasets often exhibit rich structures in practice, and we argue that there exist some unknown orders within the data instances. Aiming to find such orders, we introduce a novel Generative Markov Network (GMN) which we use to extract the order of data instances automatically. Specifically, we assume that the instances are sampled from a Markov chain. Our goal is to learn the transitional operator of the chain as well as the generation order by maximizing the generation probability under all possible data permutations. One of our key ideas is to use neural networks as a soft lookup table for approximating the possibly huge, but discrete transition matrix. This strategy allows us to amortize the space complexity with a single model and make the transitional operator generalizable to unseen instances. To ensure the learned Markov chain is ergodic, we propose a greedy batch-wise permutation scheme that allows fast training. Empirically, we evaluate the learned Markov chain by showing that GMNs are able to discover orders among data instances and also perform comparably well to state-of-the-art methods on the one-shot recognition benchmark task.
On Characterizing the Capacity of Neural Networks using Algebraic Topology
Feb 13, 2018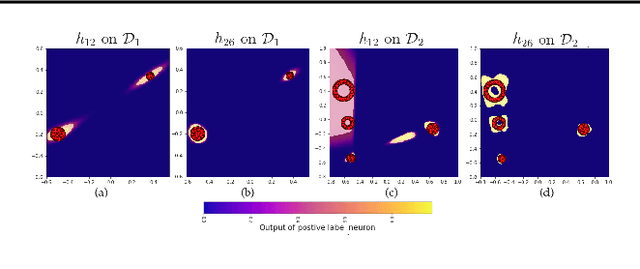
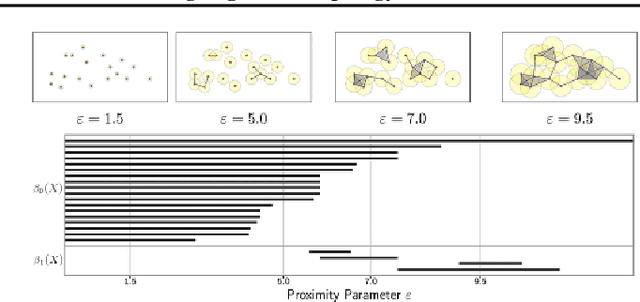
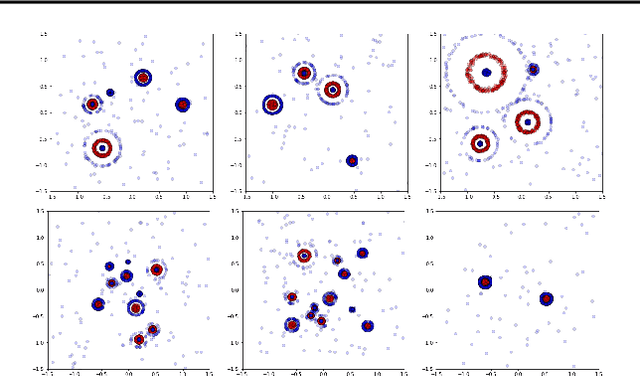
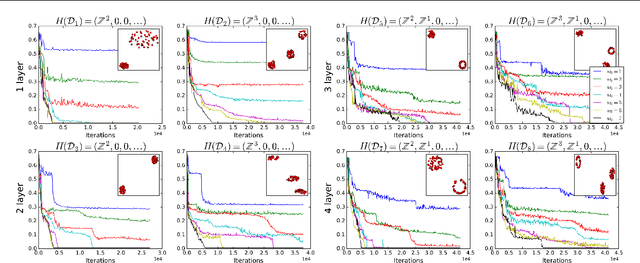
The learnability of different neural architectures can be characterized directly by computable measures of data complexity. In this paper, we reframe the problem of architecture selection as understanding how data determines the most expressive and generalizable architectures suited to that data, beyond inductive bias. After suggesting algebraic topology as a measure for data complexity, we show that the power of a network to express the topological complexity of a dataset in its decision region is a strictly limiting factor in its ability to generalize. We then provide the first empirical characterization of the topological capacity of neural networks. Our empirical analysis shows that at every level of dataset complexity, neural networks exhibit topological phase transitions. This observation allowed us to connect existing theory to empirically driven conjectures on the choice of architectures for fully-connected neural networks.
Active Neural Localization
Jan 24, 2018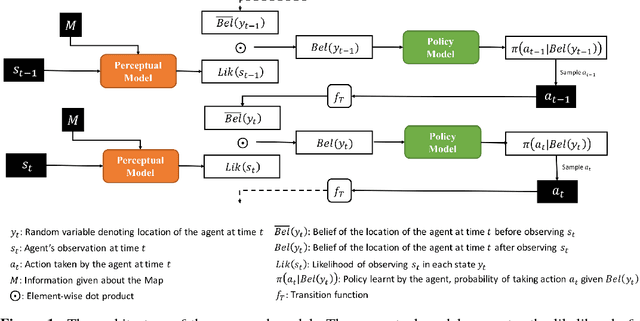
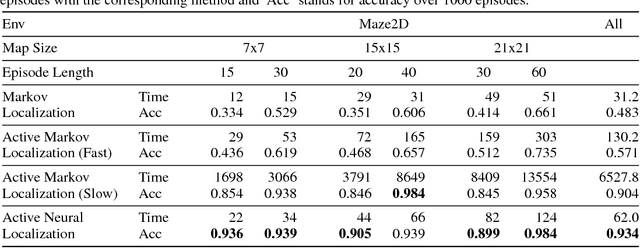
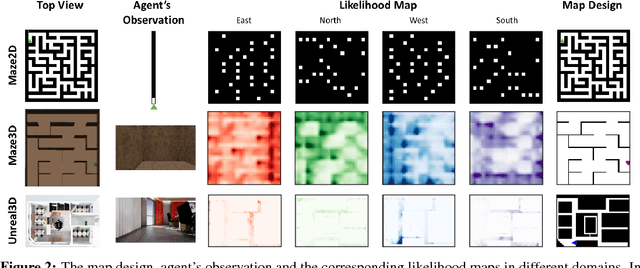
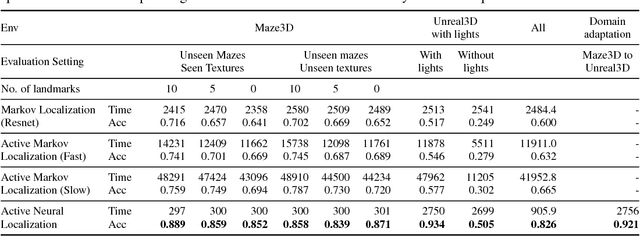
Localization is the problem of estimating the location of an autonomous agent from an observation and a map of the environment. Traditional methods of localization, which filter the belief based on the observations, are sub-optimal in the number of steps required, as they do not decide the actions taken by the agent. We propose "Active Neural Localizer", a fully differentiable neural network that learns to localize accurately and efficiently. The proposed model incorporates ideas of traditional filtering-based localization methods, by using a structured belief of the state with multiplicative interactions to propagate belief, and combines it with a policy model to localize accurately while minimizing the number of steps required for localization. Active Neural Localizer is trained end-to-end with reinforcement learning. We use a variety of simulation environments for our experiments which include random 2D mazes, random mazes in the Doom game engine and a photo-realistic environment in the Unreal game engine. The results on the 2D environments show the effectiveness of the learned policy in an idealistic setting while results on the 3D environments demonstrate the model's capability of learning the policy and perceptual model jointly from raw-pixel based RGB observations. We also show that a model trained on random textures in the Doom environment generalizes well to a photo-realistic office space environment in the Unreal engine.
Improving One-Shot Learning through Fusing Side Information
Jan 23, 2018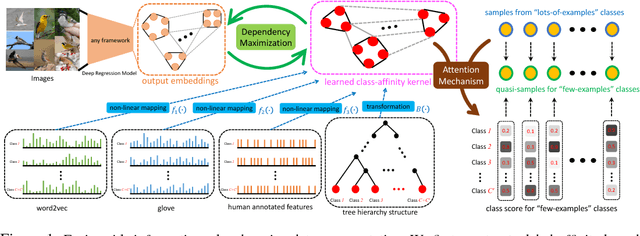

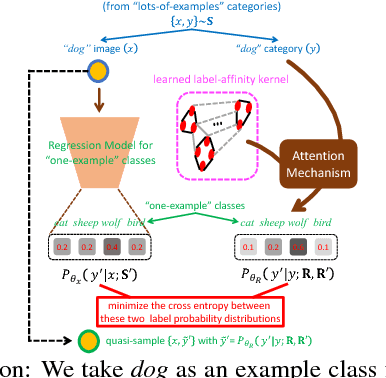
Deep Neural Networks (DNNs) often struggle with one-shot learning where we have only one or a few labeled training examples per category. In this paper, we argue that by using side information, we may compensate the missing information across classes. We introduce two statistical approaches for fusing side information into data representation learning to improve one-shot learning. First, we propose to enforce the statistical dependency between data representations and multiple types of side information. Second, we introduce an attention mechanism to efficiently treat examples belonging to the 'lots-of-examples' classes as quasi-samples (additional training samples) for 'one-example' classes. We empirically show that our learning architecture improves over traditional softmax regression networks as well as state-of-the-art attentional regression networks on one-shot recognition tasks.
Gated-Attention Architectures for Task-Oriented Language Grounding
Jan 09, 2018
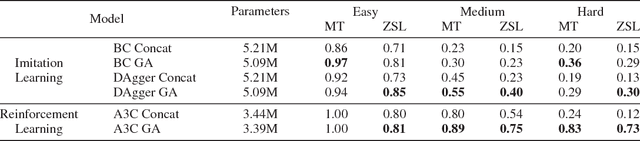
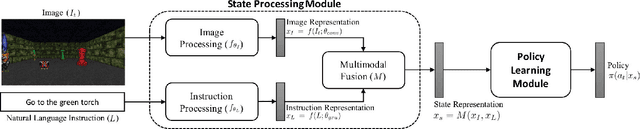
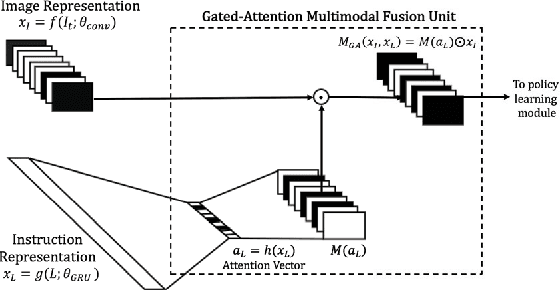
To perform tasks specified by natural language instructions, autonomous agents need to extract semantically meaningful representations of language and map it to visual elements and actions in the environment. This problem is called task-oriented language grounding. We propose an end-to-end trainable neural architecture for task-oriented language grounding in 3D environments which assumes no prior linguistic or perceptual knowledge and requires only raw pixels from the environment and the natural language instruction as input. The proposed model combines the image and text representations using a Gated-Attention mechanism and learns a policy to execute the natural language instruction using standard reinforcement and imitation learning methods. We show the effectiveness of the proposed model on unseen instructions as well as unseen maps, both quantitatively and qualitatively. We also introduce a novel environment based on a 3D game engine to simulate the challenges of task-oriented language grounding over a rich set of instructions and environment states.
Knowledge-based Word Sense Disambiguation using Topic Models
Jan 05, 2018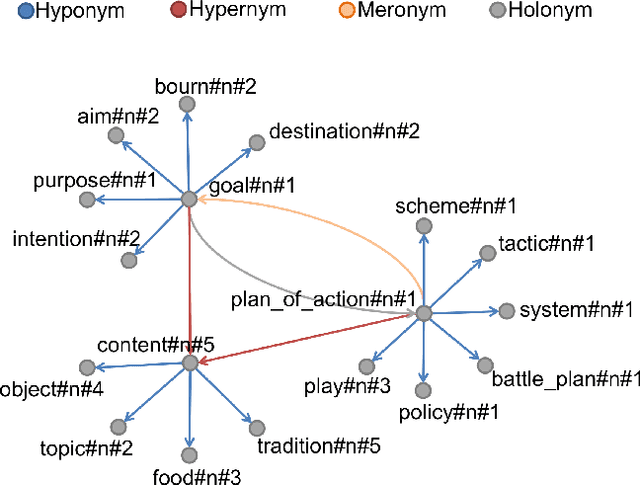
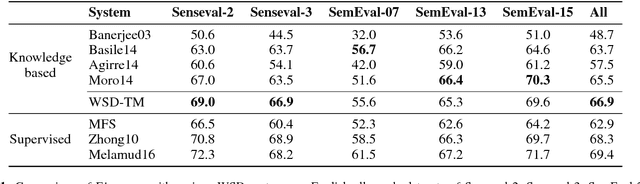
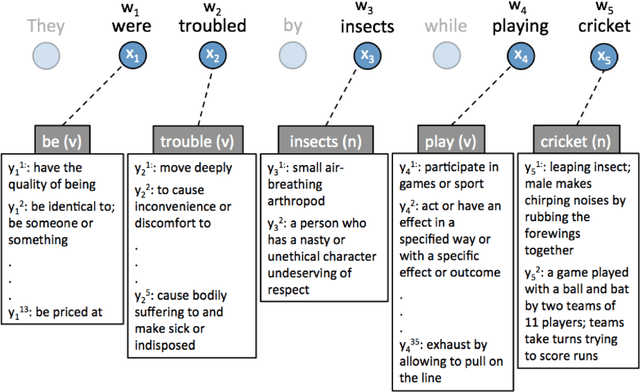
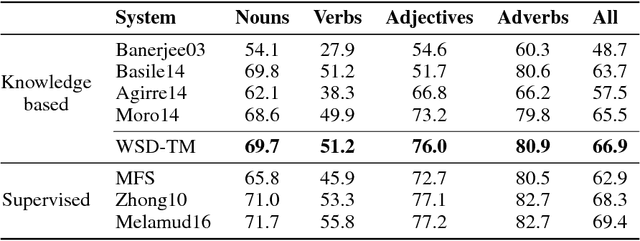
Word Sense Disambiguation is an open problem in Natural Language Processing which is particularly challenging and useful in the unsupervised setting where all the words in any given text need to be disambiguated without using any labeled data. Typically WSD systems use the sentence or a small window of words around the target word as the context for disambiguation because their computational complexity scales exponentially with the size of the context. In this paper, we leverage the formalism of topic model to design a WSD system that scales linearly with the number of words in the context. As a result, our system is able to utilize the whole document as the context for a word to be disambiguated. The proposed method is a variant of Latent Dirichlet Allocation in which the topic proportions for a document are replaced by synset proportions. We further utilize the information in the WordNet by assigning a non-uniform prior to synset distribution over words and a logistic-normal prior for document distribution over synsets. We evaluate the proposed method on Senseval-2, Senseval-3, SemEval-2007, SemEval-2013 and SemEval-2015 English All-Word WSD datasets and show that it outperforms the state-of-the-art unsupervised knowledge-based WSD system by a significant margin.
Good Semi-supervised Learning that Requires a Bad GAN
Nov 03, 2017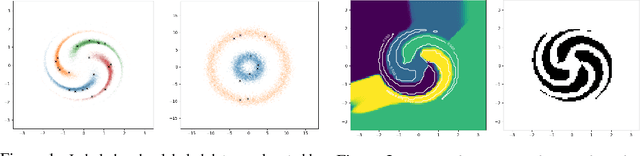
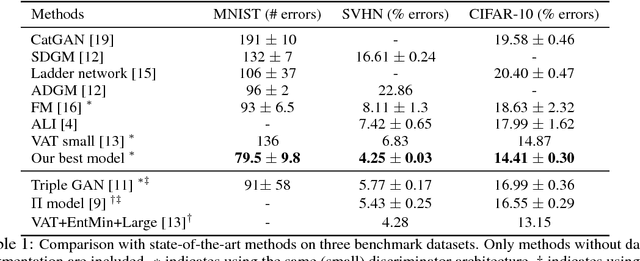
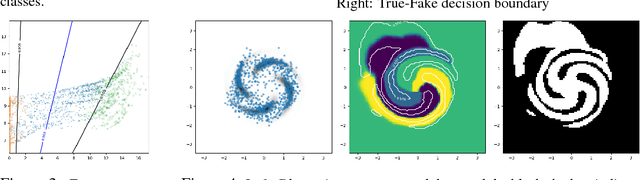
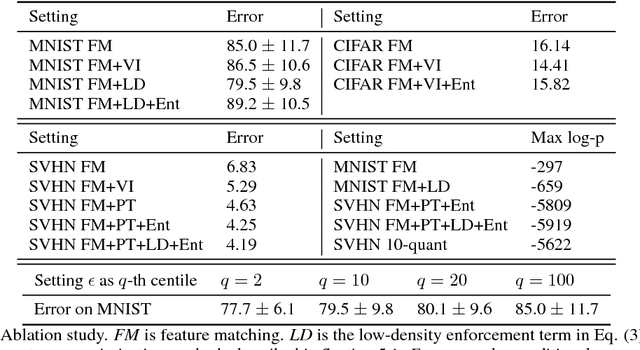
Semi-supervised learning methods based on generative adversarial networks (GANs) obtained strong empirical results, but it is not clear 1) how the discriminator benefits from joint training with a generator, and 2) why good semi-supervised classification performance and a good generator cannot be obtained at the same time. Theoretically, we show that given the discriminator objective, good semisupervised learning indeed requires a bad generator, and propose the definition of a preferred generator. Empirically, we derive a novel formulation based on our analysis that substantially improves over feature matching GANs, obtaining state-of-the-art results on multiple benchmark datasets.
Words or Characters? Fine-grained Gating for Reading Comprehension
Sep 11, 2017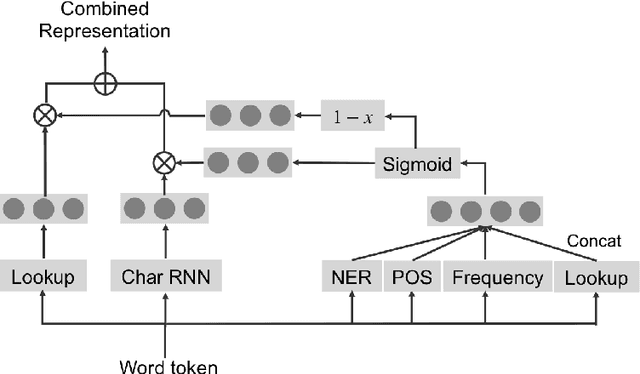
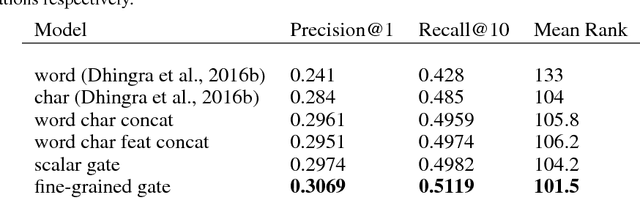
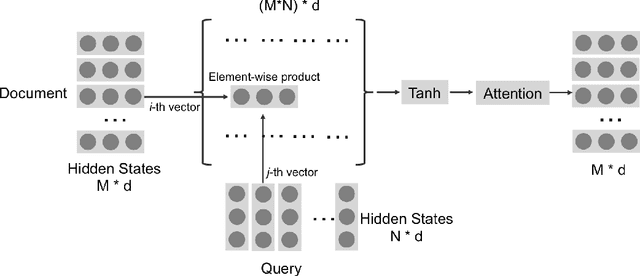
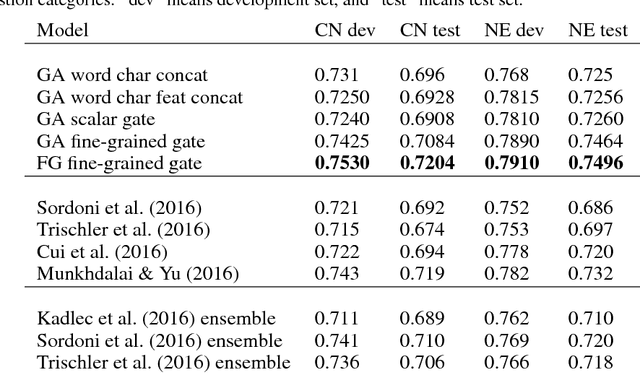
Previous work combines word-level and character-level representations using concatenation or scalar weighting, which is suboptimal for high-level tasks like reading comprehension. We present a fine-grained gating mechanism to dynamically combine word-level and character-level representations based on properties of the words. We also extend the idea of fine-grained gating to modeling the interaction between questions and paragraphs for reading comprehension. Experiments show that our approach can improve the performance on reading comprehension tasks, achieving new state-of-the-art results on the Children's Book Test dataset. To demonstrate the generality of our gating mechanism, we also show improved results on a social media tag prediction task.