 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLASP: Closed-loop Asynchronous Spatial Perception for Open-vocabulary Desktop Object Grasping
Apr 13, 2026Robot grasping of desktop object is widely used in intelligent manufacturing, logistics, and agriculture.Although vision-language models (VLMs) show strong potential for robotic manipulation, their deployment in low-level grasping faces key challenges: scarce high-quality multimodal demonstrations, spatial hallucination caused by weak geometric grounding, and the fragility of open-loop execution in dynamic environments. To address these challenges, we propose Closed-Loop Asynchronous Spatial Perception(CLASP), a novel asynchronous closed-loop framework that integrates multimodal perception, logical reasoning, and state-reflective feedback. First, we design a Dual-Pathway Hierarchical Perception module that decouples high-level semantic intent from geometric grounding. The design guides the output of the inference model and the definite action tuples, reducing spatial illusions. Second, an Asynchronous Closed-Loop Evaluator is implemented to compare pre- and post-execution states, providing text-based diagnostic feedback to establish a robust error-correction loop and improving the vulnerability of traditional open-loop execution in dynamic environments. Finally, we design a scalable multi-modal data engine that automatically synthesizes high-quality spatial annotations and reasoning templates from real and synthetic scenes without human teleoperation. Extensive experiments demonstrate that our approach significantly outperforms existing baselines, achieving an 87.0% overall success rate. Notably, the proposed framework exhibits remarkable generalization across diverse objects, bridging the sim-to-real gap and providing exceptional robustness in geometrically challenging categories and cluttered scenarios.
Local Aggressive Adversarial Attacks on 3D Point Cloud
May 19, 2021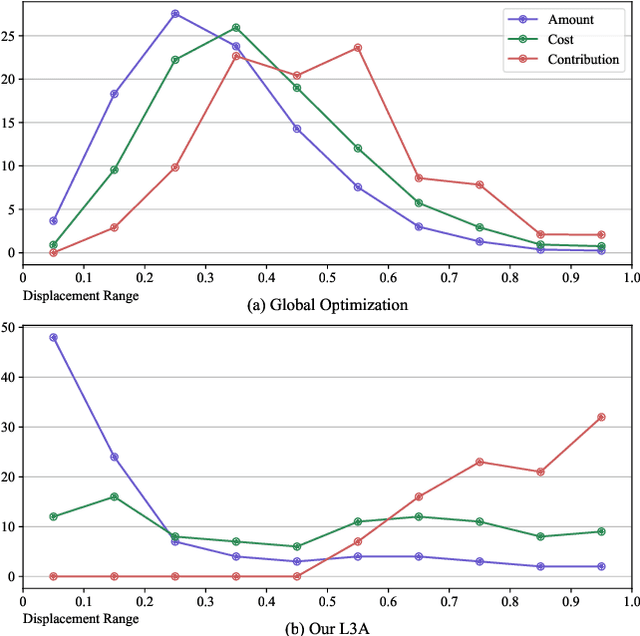
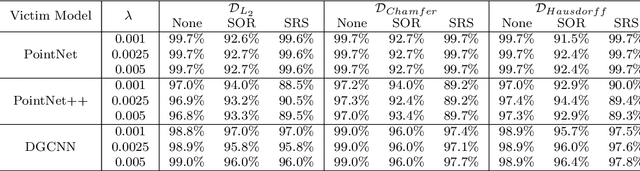
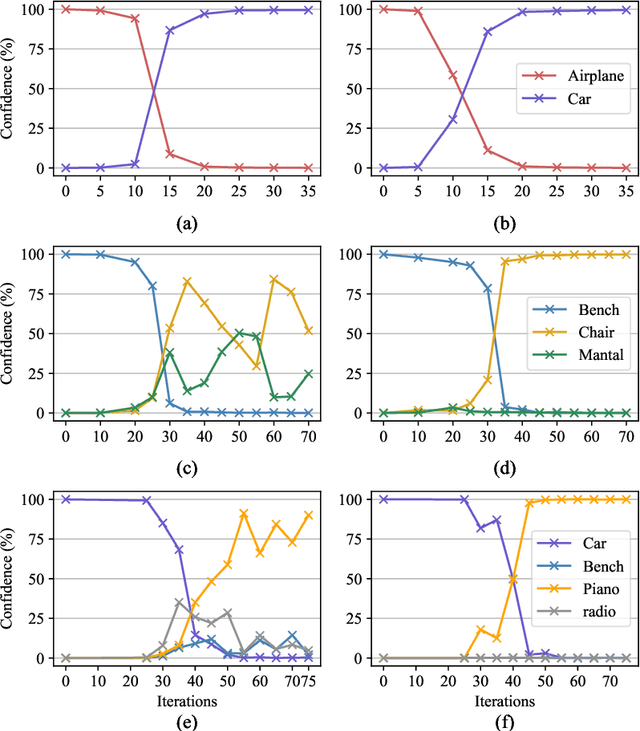
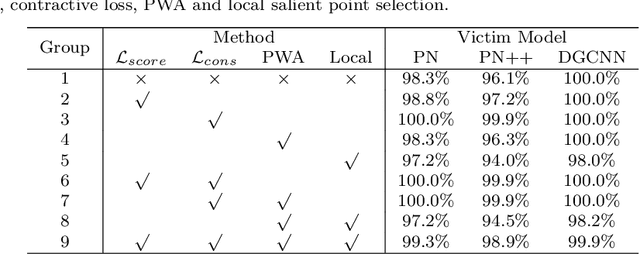
Deep neural networks are found to be prone to adversarial examples which could deliberately fool the model to make mistakes. Recently, a few of works expand this task from 2D image to 3D point cloud by using global point cloud optimization. However, the perturbations of global point are not effective for misleading the victim model. First, not all points are important in optimization toward misleading. Abundant points account considerable distortion budget but contribute trivially to attack. Second, the multi-label optimization is suboptimal for adversarial attack, since it consumes extra energy in finding multi-label victim model collapse and causes instance transformation to be dissimilar to any particular instance. Third, the independent adversarial and perceptibility losses, caring misclassification and dissimilarity separately, treat the updating of each point equally without a focus. Therefore, once perceptibility loss approaches its budget threshold, all points would be stock in the surface of hypersphere and attack would be locked in local optimality. Therefore, we propose a local aggressive adversarial attacks (L3A) to solve above issues. Technically, we select a bunch of salient points, the high-score subset of point cloud according to gradient, to perturb. Then a flow of aggressive optimization strategies are developed to reinforce the unperceptive generation of adversarial examples toward misleading victim models. Extensive experiments on PointNet, PointNet++ and DGCNN demonstrate the state-of-the-art performance of our method against existing adversarial attack methods.