 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusing Blame: Task-Dependent Credit Assignment in Biologically Plausible Dual-Stream Networks
Jun 30, 2026Biological neural circuits obey Dale's principle: each neuron's synapses are uniformly excitatory or inhibitory. Artificial networks that respect this constraint must coordinate separate excitatory and inhibitory populations, fundamentally changing how credit is assigned during learning. Several biologically plausible learning rules avoid backpropagation's weight transport requirement, but it has been difficult to achieve strong performance under Dale's principle beyond MNIST. Error Diffusion (ED) was originally proposed in a dual-stream excitatory/inhibitory architecture, where learning is driven by routing global error signals to all layers without transporting transposed forward weights or relying on random feedback matrices. Whether such a rule can scale under Dale's principle across both supervised classification and reinforcement learning remains unknown. Here, we introduce modulo error routing to extend Error Diffusion beyond binary classification, and show that a dual-stream excitatory/inhibitory architecture trained with this method achieves 96.7% on MNIST and establishes a 61.7% baseline on CIFAR-10, demonstrating that representation learning is possible even when strictly enforcing Dale's principle. For the classification setting, we introduce three domain-specific innovations: layer-specific sigmoid widths, batch-centered class error signals, and asymmetric initialization, and ablation analysis reveals that their relative importance reverses between MNIST and CIFAR-10, exposing task-dependent credit-assignment bottlenecks invisible to single-benchmark evaluation. In reinforcement learning, we integrate ED with Proximal Policy Optimization (PPO) and evaluate it on continuous-control tasks in Google Brax and on Craftax, an open-ended exploration task. We show that ED-PPO achieves competitive performance relative to Direct Feedback Alignment, a backpropagation-free baseline.
Doc-to-LoRA: Learning to Instantly Internalize Contexts
Feb 13, 2026Long input sequences are central to in-context learning, document understanding, and multi-step reasoning of Large Language Models (LLMs). However, the quadratic attention cost of Transformers makes inference memory-intensive and slow. While context distillation (CD) can transfer information into model parameters, per-prompt distillation is impractical due to training costs and latency. To address these limitations, we propose Doc-to-LoRA (D2L), a lightweight hypernetwork that meta-learns to perform approximate CD within a single forward pass. Given an unseen prompt, D2L generates a LoRA adapter for a target LLM, enabling subsequent queries to be answered without re-consuming the original context, reducing latency and KV-cache memory consumption during inference of the target LLM. On a long-context needle-in-a-haystack task, D2L successfully learns to map contexts into adapters that store the needle information, achieving near-perfect zero-shot accuracy at sequence lengths exceeding the target LLM's native context window by more than 4x. On real-world QA datasets with limited compute, D2L outperforms standard CD while significantly reducing peak memory consumption and update latency. We envision that D2L can facilitate rapid adaptation of LLMs, opening up the possibility of frequent knowledge updates and personalized chat behavior.
Text-to-LoRA: Instant Transformer Adaption
Jun 06, 2025While Foundation Models provide a general tool for rapid content creation, they regularly require task-specific adaptation. Traditionally, this exercise involves careful curation of datasets and repeated fine-tuning of the underlying model. Fine-tuning techniques enable practitioners to adapt foundation models for many new applications but require expensive and lengthy training while being notably sensitive to hyper-parameter choices. To overcome these limitations, we introduce Text-to-LoRA (T2L), a model capable of adapting Large Language Models on the fly solely based on a natural language description of the target task. T2L is a hypernetwork trained to construct LoRAs in a single inexpensive forward pass. After training T2L on a suite of 9 pre-trained LoRA adapters (GSM8K, Arc, etc.), we show that the ad-hoc reconstructed LoRA instances match the performance of task-specific adapters across the corresponding test sets. Furthermore, T2L can compress hundreds of LoRA instances and zero-shot generalize to entirely unseen tasks. This approach provides a significant step towards democratizing the specialization of foundation models and enables language-based adaptation with minimal compute requirements. Our code is available at https://github.com/SakanaAI/text-to-lora
From Grunts to Grammar: Emergent Language from Cooperative Foraging
May 19, 2025Early cavemen relied on gestures, vocalizations, and simple signals to coordinate, plan, avoid predators, and share resources. Today, humans collaborate using complex languages to achieve remarkable results. What drives this evolution in communication? How does language emerge, adapt, and become vital for teamwork? Understanding the origins of language remains a challenge. A leading hypothesis in linguistics and anthropology posits that language evolved to meet the ecological and social demands of early human cooperation. Language did not arise in isolation, but through shared survival goals. Inspired by this view, we investigate the emergence of language in multi-agent Foraging Games. These environments are designed to reflect the cognitive and ecological constraints believed to have influenced the evolution of communication. Agents operate in a shared grid world with only partial knowledge about other agents and the environment, and must coordinate to complete games like picking up high-value targets or executing temporally ordered actions. Using end-to-end deep reinforcement learning, agents learn both actions and communication strategies from scratch. We find that agents develop communication protocols with hallmark features of natural language: arbitrariness, interchangeability, displacement, cultural transmission, and compositionality. We quantify each property and analyze how different factors, such as population size and temporal dependencies, shape specific aspects of the emergent language. Our framework serves as a platform for studying how language can evolve from partial observability, temporal reasoning, and cooperative goals in embodied multi-agent settings. We will release all data, code, and models publicly.
Open RL Benchmark: Comprehensive Tracked Experiments for Reinforcement Learning
Feb 05, 2024



In many Reinforcement Learning (RL) papers, learning curves are useful indicators to measure the effectiveness of RL algorithms. However, the complete raw data of the learning curves are rarely available. As a result, it is usually necessary to reproduce the experiments from scratch, which can be time-consuming and error-prone. We present Open RL Benchmark, a set of fully tracked RL experiments, including not only the usual data such as episodic return, but also all algorithm-specific and system metrics. Open RL Benchmark is community-driven: anyone can download, use, and contribute to the data. At the time of writing, more than 25,000 runs have been tracked, for a cumulative duration of more than 8 years. Open RL Benchmark covers a wide range of RL libraries and reference implementations. Special care is taken to ensure that each experiment is precisely reproducible by providing not only the full parameters, but also the versions of the dependencies used to generate it. In addition, Open RL Benchmark comes with a command-line interface (CLI) for easy fetching and generating figures to present the results. In this document, we include two case studies to demonstrate the usefulness of Open RL Benchmark in practice. To the best of our knowledge, Open RL Benchmark is the first RL benchmark of its kind, and the authors hope that it will improve and facilitate the work of researchers in the field.
Cleanba: A Reproducible and Efficient Distributed Reinforcement Learning Platform
Sep 29, 2023



Distributed Deep Reinforcement Learning (DRL) aims to leverage more computational resources to train autonomous agents with less training time. Despite recent progress in the field, reproducibility issues have not been sufficiently explored. This paper first shows that the typical actor-learner framework can have reproducibility issues even if hyperparameters are controlled. We then introduce Cleanba, a new open-source platform for distributed DRL that proposes a highly reproducible architecture. Cleanba implements highly optimized distributed variants of PPO and IMPALA. Our Atari experiments show that these variants can obtain equivalent or higher scores than strong IMPALA baselines in moolib and torchbeast and PPO baseline in CleanRL. However, Cleanba variants present 1) shorter training time and 2) more reproducible learning curves in different hardware settings. Cleanba's source code is available at \url{https://github.com/vwxyzjn/cleanba}
Learning to Cooperate with Unseen Agent via Meta-Reinforcement Learning
Nov 05, 2021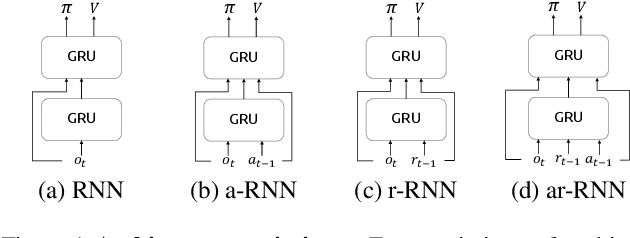
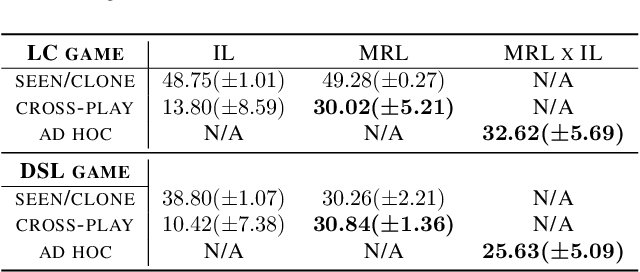
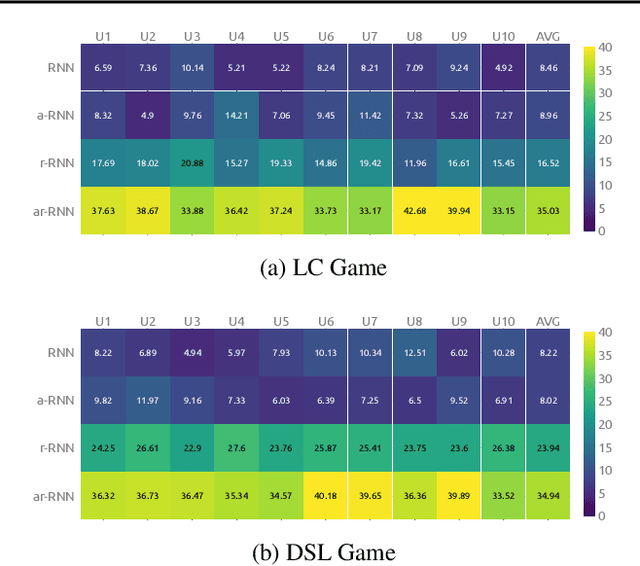
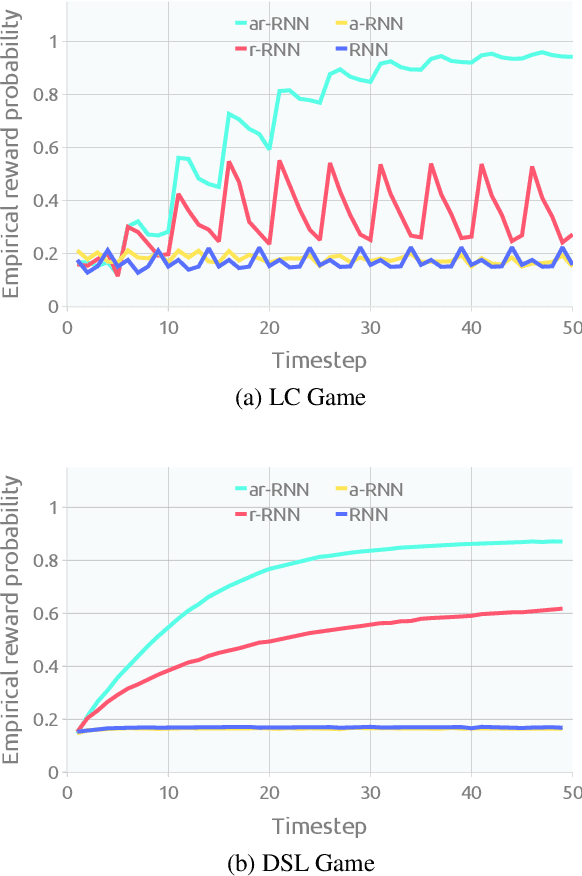
Ad hoc teamwork problem describes situations where an agent has to cooperate with previously unseen agents to achieve a common goal. For an agent to be successful in these scenarios, it has to have a suitable cooperative skill. One could implement cooperative skills into an agent by using domain knowledge to design the agent's behavior. However, in complex domains, domain knowledge might not be available. Therefore, it is worthwhile to explore how to directly learn cooperative skills from data. In this work, we apply meta-reinforcement learning (meta-RL) formulation in the context of the ad hoc teamwork problem. Our empirical results show that such a method could produce robust cooperative agents in two cooperative environments with different cooperative circumstances: social compliance and language interpretation. (This is a full paper of the extended abstract version.)
An Explicit Local and Global Representation Disentanglement Framework with Applications in Deep Clustering and Unsupervised Object Detection
Feb 24, 2020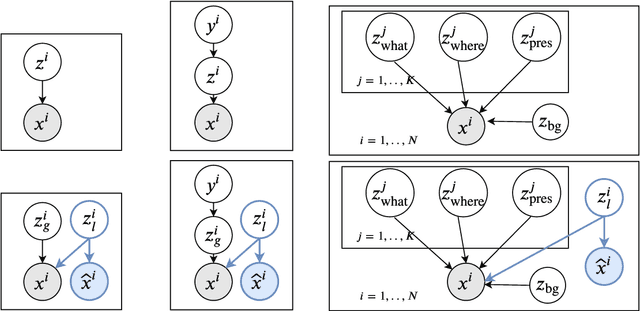

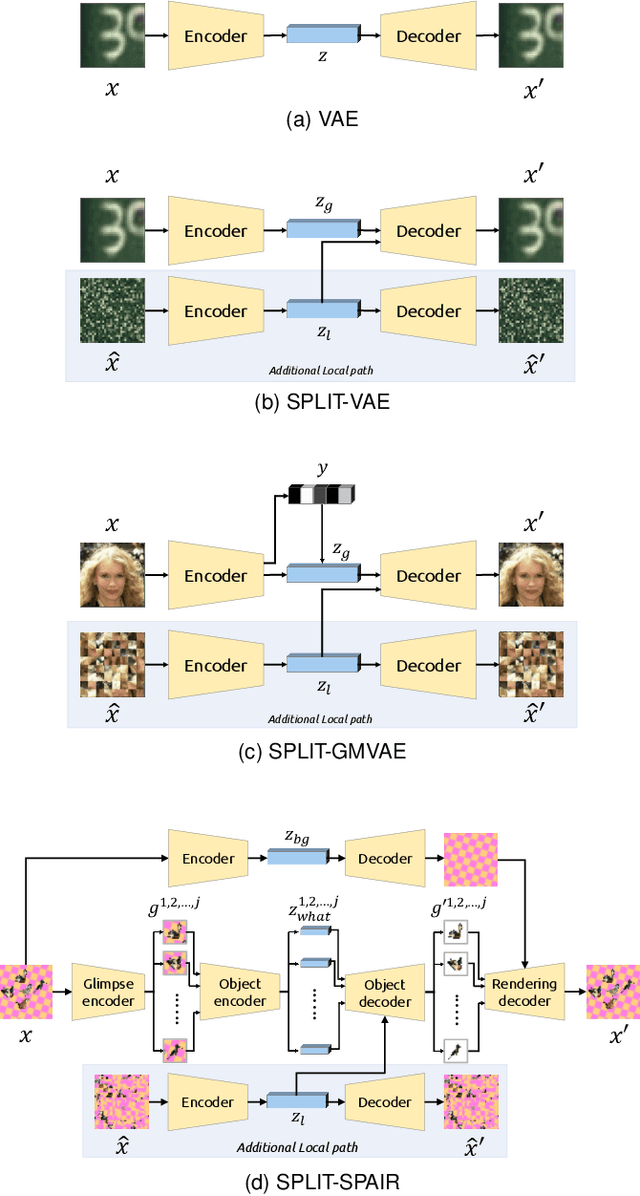
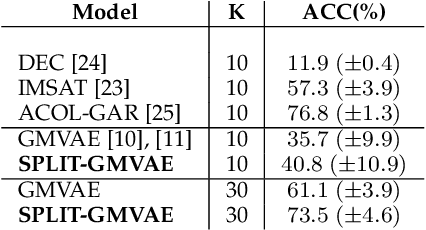
Visual data can be understood at different levels of granularity, where global features correspond to semantic-level information and local features correspond to texture patterns. In this work, we propose a framework, called SPLIT, which allows us to disentangle local and global information into two separate sets of latent variables within the variational autoencoder (VAE) framework. Our framework adds generative assumption to the VAE by requiring a subset of the latent variables to generate an auxiliary set of observable data. This additional generative assumption primes the latent variables to local information and encourages the other latent variables to represent global information. We examine three different flavours of VAEs with different generative assumptions. We show that the framework can effectively disentangle local and global information within these models leads to improved representation, with better clustering and unsupervised object detection benchmarks. Finally, we establish connections between SPLIT and recent research in cognitive neuroscience regarding the disentanglement in human visual perception. The code for our experiments is at https://github.com/51616/split-vae .