 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNISP: Pruning Networks using Neuron Importance Score Propagation
Mar 21, 2018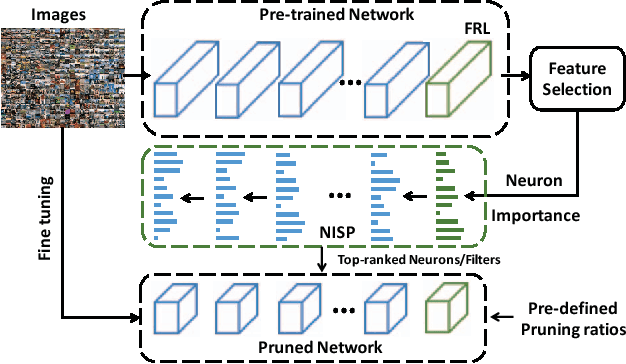
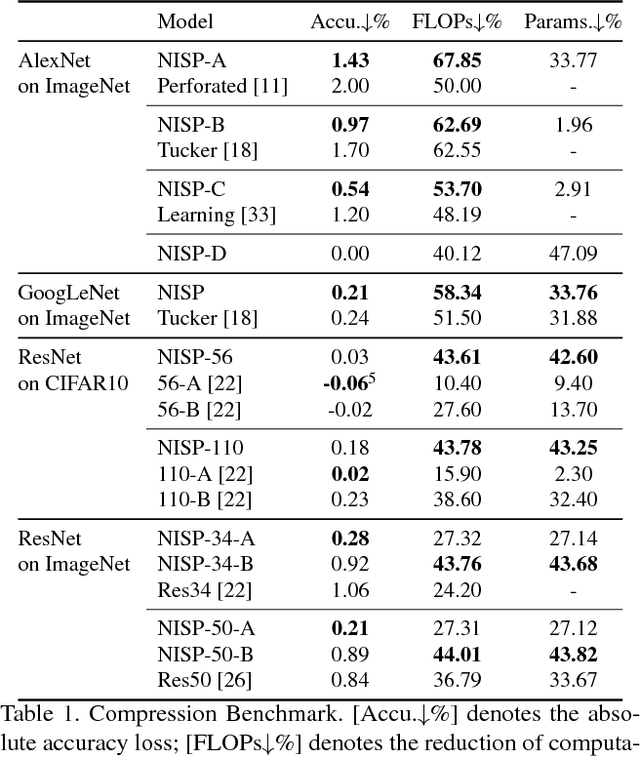
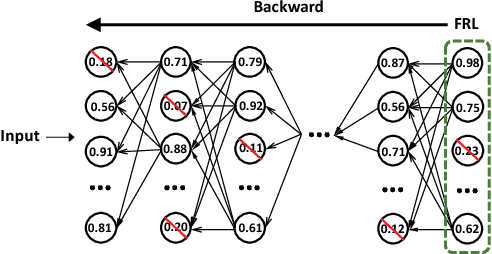
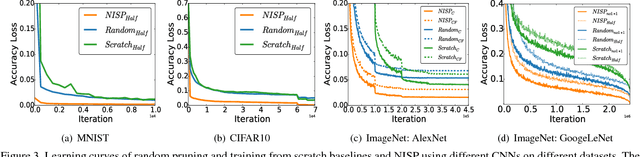
To reduce the significant redundancy in deep Convolutional Neural Networks (CNNs), most existing methods prune neurons by only considering statistics of an individual layer or two consecutive layers (e.g., prune one layer to minimize the reconstruction error of the next layer), ignoring the effect of error propagation in deep networks. In contrast, we argue that it is essential to prune neurons in the entire neuron network jointly based on a unified goal: minimizing the reconstruction error of important responses in the "final response layer" (FRL), which is the second-to-last layer before classification, for a pruned network to retrain its predictive power. Specifically, we apply feature ranking techniques to measure the importance of each neuron in the FRL, and formulate network pruning as a binary integer optimization problem and derive a closed-form solution to it for pruning neurons in earlier layers. Based on our theoretical analysis, we propose the Neuron Importance Score Propagation (NISP) algorithm to propagate the importance scores of final responses to every neuron in the network. The CNN is pruned by removing neurons with least importance, and then fine-tuned to retain its predictive power. NISP is evaluated on several datasets with multiple CNN models and demonstrated to achieve significant acceleration and compression with negligible accuracy loss.
ReMotENet: Efficient Relevant Motion Event Detection for Large-scale Home Surveillance Videos
Jan 06, 2018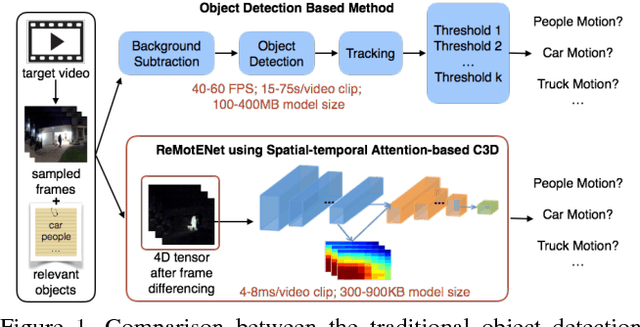
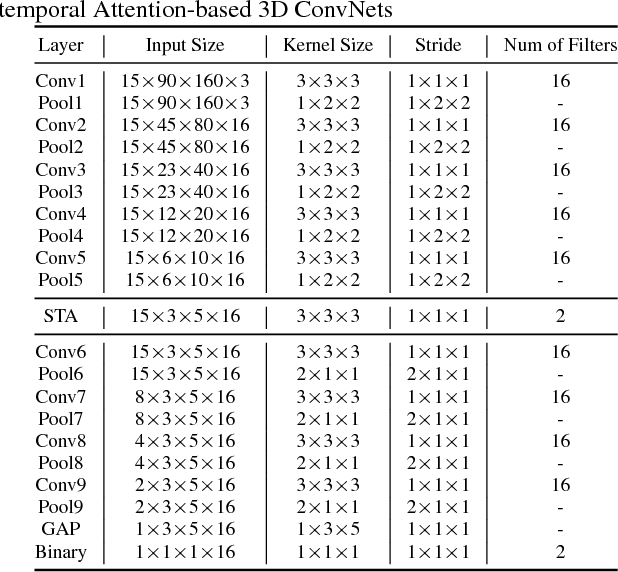
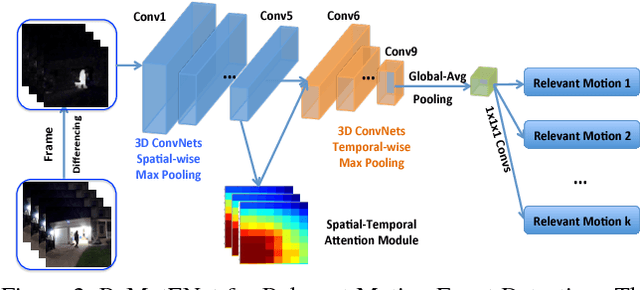
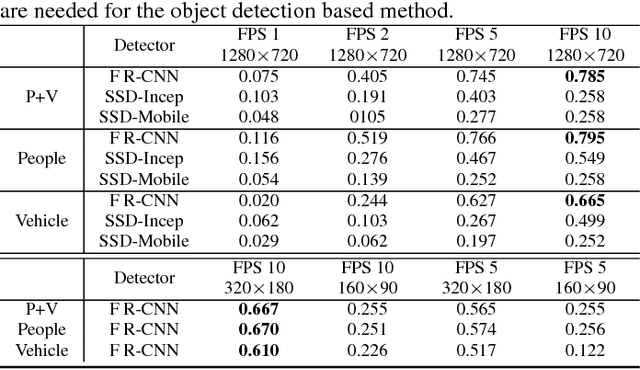
This paper addresses the problem of detecting relevant motion caused by objects of interest (e.g., person and vehicles) in large scale home surveillance videos. The traditional method usually consists of two separate steps, i.e., detecting moving objects with background subtraction running on the camera, and filtering out nuisance motion events (e.g., trees, cloud, shadow, rain/snow, flag) with deep learning based object detection and tracking running on cloud. The method is extremely slow and therefore not cost effective, and does not fully leverage the spatial-temporal redundancies with a pre-trained off-the-shelf object detector. To dramatically speedup relevant motion event detection and improve its performance, we propose a novel network for relevant motion event detection, ReMotENet, which is a unified, end-to-end data-driven method using spatial-temporal attention-based 3D ConvNets to jointly model the appearance and motion of objects-of-interest in a video. ReMotENet parses an entire video clip in one forward pass of a neural network to achieve significant speedup. Meanwhile, it exploits the properties of home surveillance videos, e.g., relevant motion is sparse both spatially and temporally, and enhances 3D ConvNets with a spatial-temporal attention model and reference-frame subtraction to encourage the network to focus on the relevant moving objects. Experiments demonstrate that our method can achieve comparable or event better performance than the object detection based method but with three to four orders of magnitude speedup (up to 20k times) on GPU devices. Our network is efficient, compact and light-weight. It can detect relevant motion on a 15s surveillance video clip within 4-8 milliseconds on a GPU and a fraction of second (0.17-0.39) on a CPU with a model size of less than 1MB.
Visual Relationship Detection with Internal and External Linguistic Knowledge Distillation
Aug 03, 2017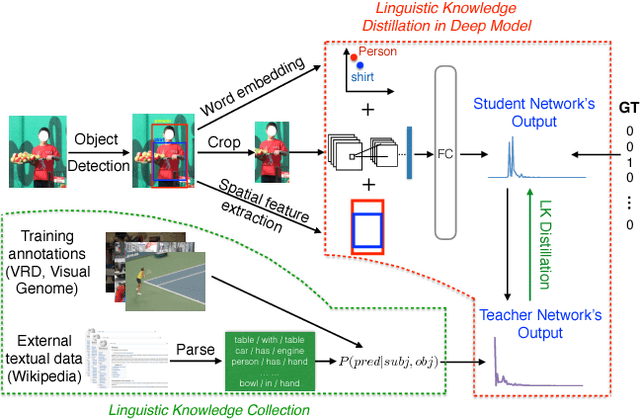
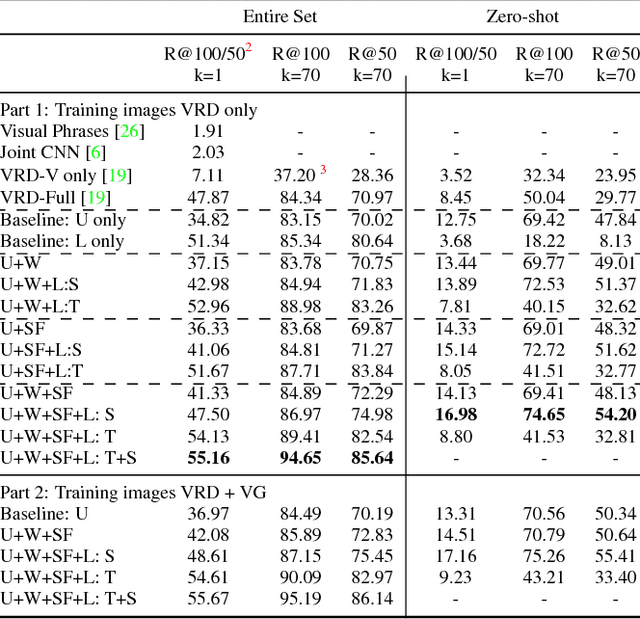

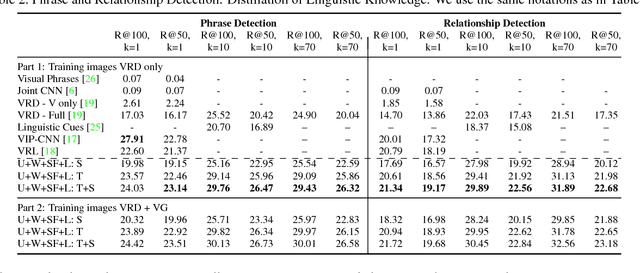
Understanding visual relationships involves identifying the subject, the object, and a predicate relating them. We leverage the strong correlations between the predicate and the (subj,obj) pair (both semantically and spatially) to predict the predicates conditioned on the subjects and the objects. Modeling the three entities jointly more accurately reflects their relationships, but complicates learning since the semantic space of visual relationships is huge and the training data is limited, especially for the long-tail relationships that have few instances. To overcome this, we use knowledge of linguistic statistics to regularize visual model learning. We obtain linguistic knowledge by mining from both training annotations (internal knowledge) and publicly available text, e.g., Wikipedia (external knowledge), computing the conditional probability distribution of a predicate given a (subj,obj) pair. Then, we distill the knowledge into a deep model to achieve better generalization. Our experimental results on the Visual Relationship Detection (VRD) and Visual Genome datasets suggest that with this linguistic knowledge distillation, our model outperforms the state-of-the-art methods significantly, especially when predicting unseen relationships (e.g., recall improved from 8.45% to 19.17% on VRD zero-shot testing set).
Generating Holistic 3D Scene Abstractions for Text-based Image Retrieval
Apr 11, 2017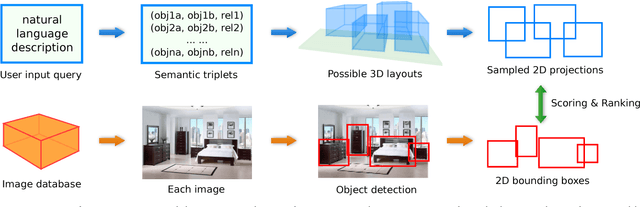

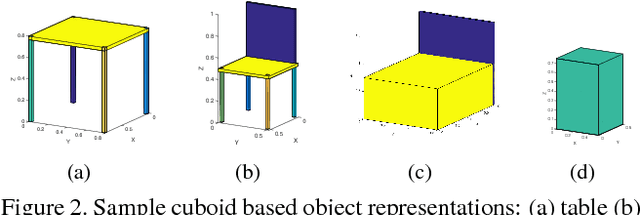
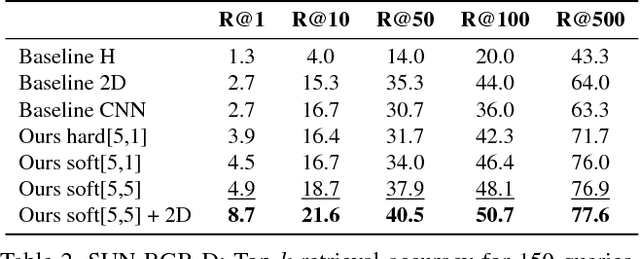
Spatial relationships between objects provide important information for text-based image retrieval. As users are more likely to describe a scene from a real world perspective, using 3D spatial relationships rather than 2D relationships that assume a particular viewing direction, one of the main challenges is to infer the 3D structure that bridges images with users' text descriptions. However, direct inference of 3D structure from images requires learning from large scale annotated data. Since interactions between objects can be reduced to a limited set of atomic spatial relations in 3D, we study the possibility of inferring 3D structure from a text description rather than an image, applying physical relation models to synthesize holistic 3D abstract object layouts satisfying the spatial constraints present in a textual description. We present a generic framework for retrieving images from a textual description of a scene by matching images with these generated abstract object layouts. Images are ranked by matching object detection outputs (bounding boxes) to 2D layout candidates (also represented by bounding boxes) which are obtained by projecting the 3D scenes with sampled camera directions. We validate our approach using public indoor scene datasets and show that our method outperforms baselines built upon object occurrence histograms and learned 2D pairwise relations.
The Role of Context Selection in Object Detection
Sep 09, 2016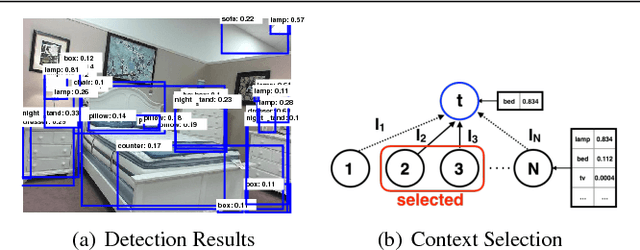
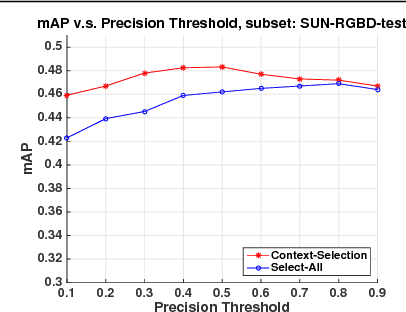


We investigate the reasons why context in object detection has limited utility by isolating and evaluating the predictive power of different context cues under ideal conditions in which context provided by an oracle. Based on this study, we propose a region-based context re-scoring method with dynamic context selection to remove noise and emphasize informative context. We introduce latent indicator variables to select (or ignore) potential contextual regions, and learn the selection strategy with latent-SVM. We conduct experiments to evaluate the performance of the proposed context selection method on the SUN RGB-D dataset. The method achieves a significant improvement in terms of mean average precision (mAP), compared with both appearance based detectors and a conventional context model without the selection scheme.