 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferential Privacy in Two-Layer Networks: How DP-SGD Harms Fairness and Robustness
Mar 05, 2026Differentially private learning is essential for training models on sensitive data, but empirical studies consistently show that it can degrade performance, introduce fairness issues like disparate impact, and reduce adversarial robustness. The theoretical underpinnings of these phenomena in modern, non-convex neural networks remain largely unexplored. This paper introduces a unified feature-centric framework to analyze the feature learning dynamics of differentially private stochastic gradient descent (DP-SGD) in two-layer ReLU convolutional neural networks. Our analysis establishes test loss bounds governed by a crucial metric: the feature-to-noise ratio (FNR). We demonstrate that the noise required for privacy leads to suboptimal feature learning, and specifically show that: 1) imbalanced FNRs across classes and subpopulations cause disparate impact; 2) even in the same class, noise has a greater negative impact on semantically long-tailed data; and 3) noise injection exacerbates vulnerability to adversarial attacks. Furthermore, our analysis reveals that the popular paradigm of public pre-training and private fine-tuning does not guarantee improvement, particularly under significant feature distribution shifts between datasets. Experiments on synthetic and real-world data corroborate our theoretical findings.
Feature Resemblance: On the Theoretical Understanding of Analogical Reasoning in Transformers
Mar 05, 2026Understanding reasoning in large language models is complicated by evaluations that conflate multiple reasoning types. We isolate analogical reasoning (inferring shared properties between entities based on known similarities) and analyze its emergence in transformers. We theoretically prove three key results: (1) Joint training on similarity and attribution premises enables analogical reasoning through aligned representations; (2) Sequential training succeeds only when similarity structure is learned before specific attributes, revealing a necessary curriculum; (3) Two-hop reasoning ($a \to b, b \to c \implies a \to c$) reduces to analogical reasoning with identity bridges ($b = b$), which must appear explicitly in training data. These results reveal a unified mechanism: transformers encode entities with similar properties into similar representations, enabling property transfer through feature alignment. Experiments with architectures up to 1.5B parameters validate our theory and demonstrate how representational geometry shapes inductive reasoning capabilities.
Tackling Privacy Heterogeneity in Differentially Private Federated Learning
Feb 26, 2026Differentially private federated learning (DP-FL) enables clients to collaboratively train machine learning models while preserving the privacy of their local data. However, most existing DP-FL approaches assume that all clients share a uniform privacy budget, an assumption that does not hold in real-world scenarios where privacy requirements vary widely. This privacy heterogeneity poses a significant challenge: conventional client selection strategies, which typically rely on data quantity, cannot distinguish between clients providing high-quality updates and those introducing substantial noise due to strict privacy constraints. To address this gap, we present the first systematic study of privacy-aware client selection in DP-FL. We establish a theoretical foundation by deriving a convergence analysis that quantifies the impact of privacy heterogeneity on training error. Building on this analysis, we propose a privacy-aware client selection strategy, formulated as a convex optimization problem, that adaptively adjusts selection probabilities to minimize training error. Extensive experiments on benchmark datasets demonstrate that our approach achieves up to a 10% improvement in test accuracy on CIFAR-10 compared to existing baselines under heterogeneous privacy budgets. These results highlight the importance of incorporating privacy heterogeneity into client selection for practical and effective federated learning.
JSAM: Privacy Straggler-Resilient Joint Client Selection and Incentive Mechanism Design in Differentially Private Federated Learning
Feb 25, 2026Differentially private federated learning faces a fundamental tension: privacy protection mechanisms that safeguard client data simultaneously create quantifiable privacy costs that discourage participation, undermining the collaborative training process. Existing incentive mechanisms rely on unbiased client selection, forcing servers to compensate even the most privacy-sensitive clients ("privacy stragglers"), leading to systemic inefficiency and suboptimal resource allocation. We introduce JSAM (Joint client Selection and privacy compensAtion Mechanism), a Bayesian-optimal framework that simultaneously optimizes client selection probabilities and privacy compensation to maximize training effectiveness under budget constraints. Our approach transforms a complex 2N-dimensional optimization problem into an efficient three-dimensional formulation through novel theoretical characterization of optimal selection strategies. We prove that servers should preferentially select privacy-tolerant clients while excluding high-sensitivity participants, and uncover the counter-intuitive insight that clients with minimal privacy sensitivity may incur the highest cumulative costs due to frequent participation. Extensive evaluations on MNIST and CIFAR-10 demonstrate that JSAM achieves up to 15% improvement in test accuracy compared to existing unbiased selection mechanisms while maintaining cost efficiency across varying data heterogeneity levels.
Kolmogorov-Arnold Representation for Symplectic Learning: Advancing Hamiltonian Neural Networks
Aug 26, 2025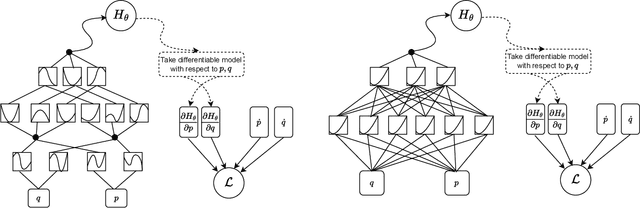
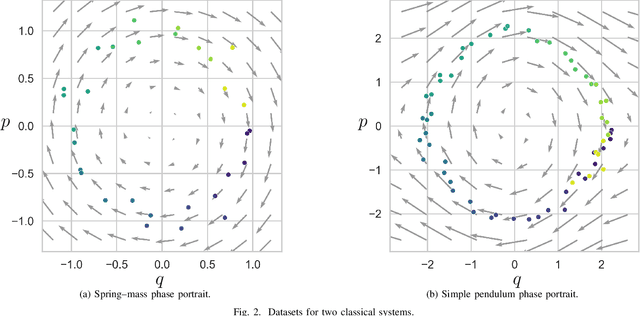
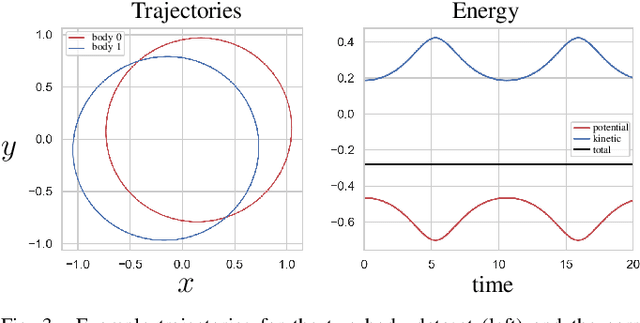
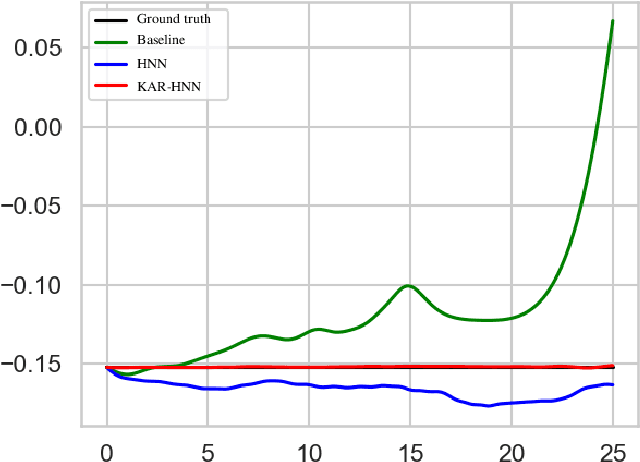
We propose a Kolmogorov-Arnold Representation-based Hamiltonian Neural Network (KAR-HNN) that replaces the Multilayer Perceptrons (MLPs) with univariate transformations. While Hamiltonian Neural Networks (HNNs) ensure energy conservation by learning Hamiltonian functions directly from data, existing implementations, often relying on MLPs, cause hypersensitivity to the hyperparameters while exploring complex energy landscapes. Our approach exploits the localized function approximations to better capture high-frequency and multi-scale dynamics, reducing energy drift and improving long-term predictive stability. The networks preserve the symplectic form of Hamiltonian systems, and thus maintain interpretability and physical consistency. After assessing KAR-HNN on four benchmark problems including spring-mass, simple pendulum, two- and three-body problem, we foresee its effectiveness for accurate and stable modeling of realistic physical processes often at high dimensions and with few known parameters.
An Iterative Framework for Generative Backmapping of Coarse Grained Proteins
May 23, 2025



The techniques of data-driven backmapping from coarse-grained (CG) to fine-grained (FG) representation often struggle with accuracy, unstable training, and physical realism, especially when applied to complex systems such as proteins. In this work, we introduce a novel iterative framework by using conditional Variational Autoencoders and graph-based neural networks, specifically designed to tackle the challenges associated with such large-scale biomolecules. Our method enables stepwise refinement from CG beads to full atomistic details. We outline the theory of iterative generative backmapping and demonstrate via numerical experiments the advantages of multistep schemes by applying them to proteins of vastly different structures with very coarse representations. This multistep approach not only improves the accuracy of reconstructions but also makes the training process more computationally efficient for proteins with ultra-CG representations.
Rethinking Benign Overfitting in Two-Layer Neural Networks
Feb 17, 2025



Recent theoretical studies (Kou et al., 2023; Cao et al., 2022) have revealed a sharp phase transition from benign to harmful overfitting when the noise-to-feature ratio exceeds a threshold-a situation common in long-tailed data distributions where atypical data is prevalent. However, harmful overfitting rarely happens in overparameterized neural networks. Further experimental results suggested that memorization is necessary for achieving near-optimal generalization error in long-tailed data distributions (Feldman & Zhang, 2020). We argue that this discrepancy between theoretical predictions and empirical observations arises because previous feature-noise data models overlook the heterogeneous nature of noise across different data classes. In this paper, we refine the feature-noise data model by incorporating class-dependent heterogeneous noise and re-examine the overfitting phenomenon in neural networks. Through a comprehensive analysis of the training dynamics, we establish test loss bounds for the refined model. Our findings reveal that neural networks can leverage "data noise", previously deemed harmful, to learn implicit features that improve the classification accuracy for long-tailed data. Experimental validation on both synthetic and real-world datasets supports our theoretical results.
Safe Hybrid-Action Reinforcement Learning-Based Decision and Control for Discretionary Lane Change
Mar 01, 2024



Autonomous lane-change, a key feature of advanced driver-assistance systems, can enhance traffic efficiency and reduce the incidence of accidents. However, safe driving of autonomous vehicles remains challenging in complex environments. How to perform safe and appropriate lane change is a popular topic of research in the field of autonomous driving. Currently, few papers consider the safety of reinforcement learning in autonomous lane-change scenarios. We introduce safe hybrid-action reinforcement learning into discretionary lane change for the first time and propose Parameterized Soft Actor-Critic with PID Lagrangian (PASAC-PIDLag) algorithm. Furthermore, we conduct a comparative analysis of the Parameterized Soft Actor-Critic (PASAC), which is an unsafe version of PASAC-PIDLag. Both algorithms are employed to train the lane-change strategy of autonomous vehicles to output discrete lane-change decision and longitudinal vehicle acceleration. Our simulation results indicate that at a traffic density of 15 vehicles per kilometer (15 veh/km), the PASAC-PIDLag algorithm exhibits superior safety with a collision rate of 0%, outperforming the PASAC algorithm, which has a collision rate of 1%. The outcomes of the generalization assessments reveal that at low traffic density levels, both the PASAC-PIDLag and PASAC algorithms are proficient in attaining a 0% collision rate. Under conditions of high traffic flow density, the PASAC-PIDLag algorithm surpasses PASAC in terms of both safety and optimality.