 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePyTorchVideo: A Deep Learning Library for Video Understanding
Nov 18, 2021
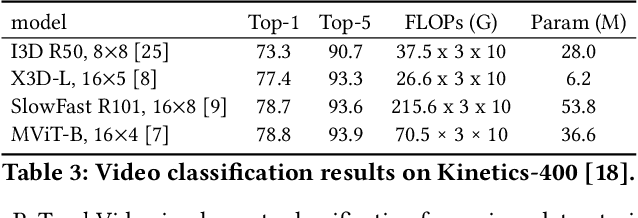

We introduce PyTorchVideo, an open-source deep-learning library that provides a rich set of modular, efficient, and reproducible components for a variety of video understanding tasks, including classification, detection, self-supervised learning, and low-level processing. The library covers a full stack of video understanding tools including multimodal data loading, transformations, and models that reproduce state-of-the-art performance. PyTorchVideo further supports hardware acceleration that enables real-time inference on mobile devices. The library is based on PyTorch and can be used by any training framework; for example, PyTorchLightning, PySlowFast, or Classy Vision. PyTorchVideo is available at https://pytorchvideo.org/
Early Convolutions Help Transformers See Better
Jul 12, 2021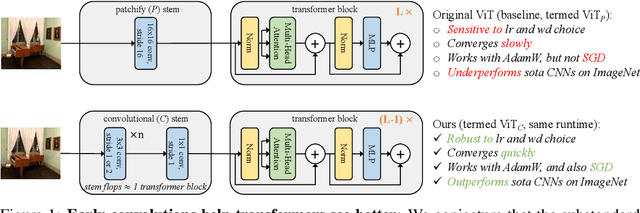

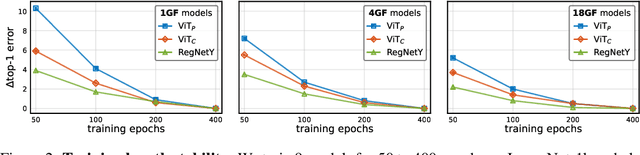
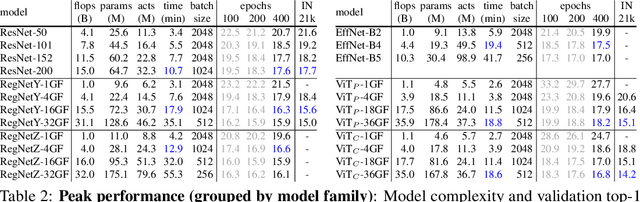
Vision transformer (ViT) models exhibit substandard optimizability. In particular, they are sensitive to the choice of optimizer (AdamW vs. SGD), optimizer hyperparameters, and training schedule length. In comparison, modern convolutional neural networks are far easier to optimize. Why is this the case? In this work, we conjecture that the issue lies with the patchify stem of ViT models, which is implemented by a stride-p pxp convolution (p=16 by default) applied to the input image. This large-kernel plus large-stride convolution runs counter to typical design choices of convolutional layers in neural networks. To test whether this atypical design choice causes an issue, we analyze the optimization behavior of ViT models with their original patchify stem versus a simple counterpart where we replace the ViT stem by a small number of stacked stride-two 3x3 convolutions. While the vast majority of computation in the two ViT designs is identical, we find that this small change in early visual processing results in markedly different training behavior in terms of the sensitivity to optimization settings as well as the final model accuracy. Using a convolutional stem in ViT dramatically increases optimization stability and also improves peak performance (by ~1-2% top-1 accuracy on ImageNet-1k), while maintaining flops and runtime. The improvement can be observed across the wide spectrum of model complexities (from 1G to 36G flops) and dataset scales (from ImageNet-1k to ImageNet-21k). These findings lead us to recommend using a standard, lightweight convolutional stem for ViT models as a more robust architectural choice compared to the original ViT model design.
A Large-Scale Study on Unsupervised Spatiotemporal Representation Learning
Apr 29, 2021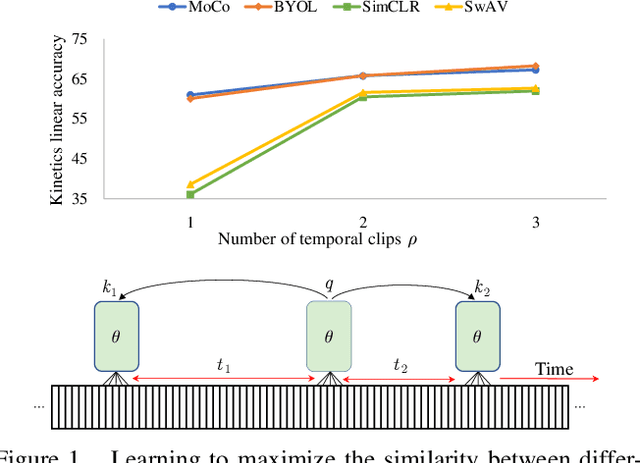

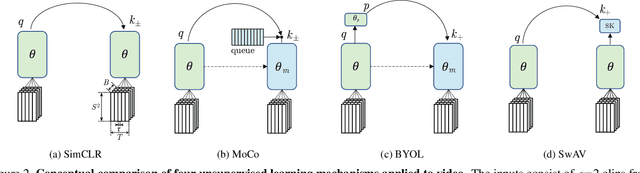
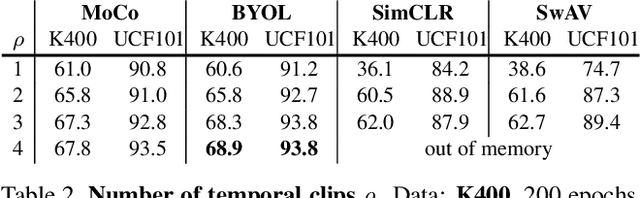
We present a large-scale study on unsupervised spatiotemporal representation learning from videos. With a unified perspective on four recent image-based frameworks, we study a simple objective that can easily generalize all these methods to space-time. Our objective encourages temporally-persistent features in the same video, and in spite of its simplicity, it works surprisingly well across: (i) different unsupervised frameworks, (ii) pre-training datasets, (iii) downstream datasets, and (iv) backbone architectures. We draw a series of intriguing observations from this study, e.g., we discover that encouraging long-spanned persistency can be effective even if the timespan is 60 seconds. In addition to state-of-the-art results in multiple benchmarks, we report a few promising cases in which unsupervised pre-training can outperform its supervised counterpart. Code is made available at https://github.com/facebookresearch/SlowFast
Boundary IoU: Improving Object-Centric Image Segmentation Evaluation
Mar 30, 2021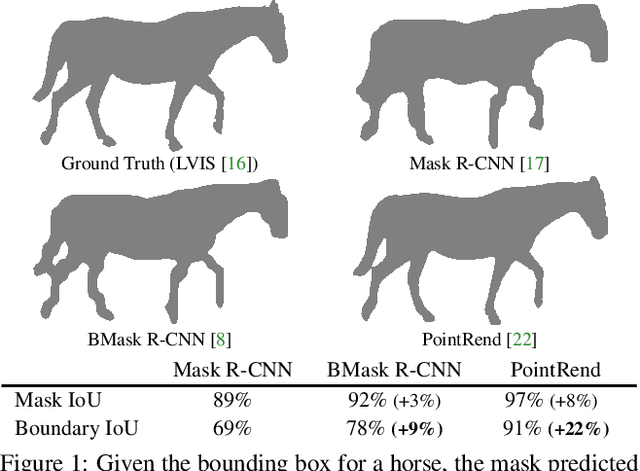
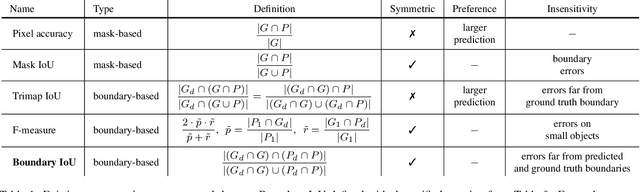

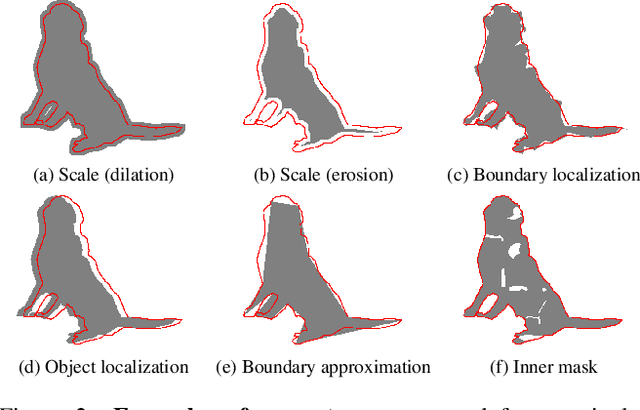
We present Boundary IoU (Intersection-over-Union), a new segmentation evaluation measure focused on boundary quality. We perform an extensive analysis across different error types and object sizes and show that Boundary IoU is significantly more sensitive than the standard Mask IoU measure to boundary errors for large objects and does not over-penalize errors on smaller objects. The new quality measure displays several desirable characteristics like symmetry w.r.t. prediction/ground truth pairs and balanced responsiveness across scales, which makes it more suitable for segmentation evaluation than other boundary-focused measures like Trimap IoU and F-measure. Based on Boundary IoU, we update the standard evaluation protocols for instance and panoptic segmentation tasks by proposing the Boundary AP (Average Precision) and Boundary PQ (Panoptic Quality) metrics, respectively. Our experiments show that the new evaluation metrics track boundary quality improvements that are generally overlooked by current Mask IoU-based evaluation metrics. We hope that the adoption of the new boundary-sensitive evaluation metrics will lead to rapid progress in segmentation methods that improve boundary quality.
Fast and Accurate Model Scaling
Mar 11, 2021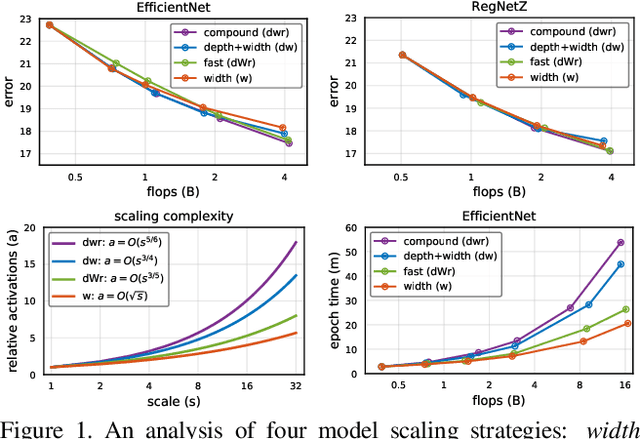

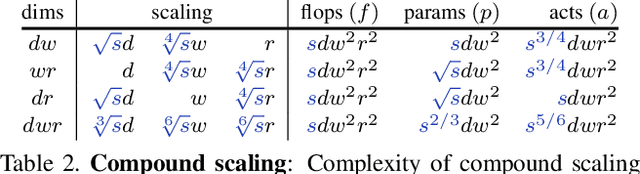
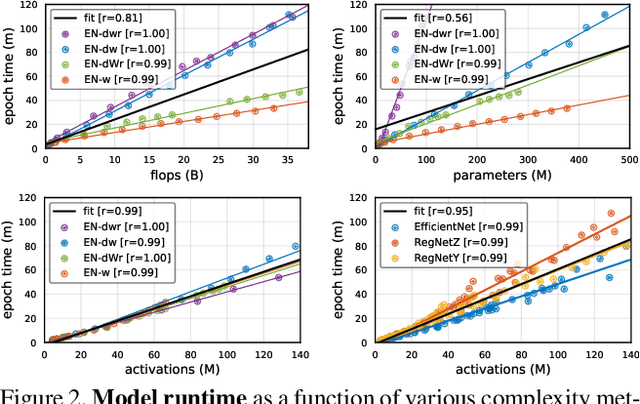
In this work we analyze strategies for convolutional neural network scaling; that is, the process of scaling a base convolutional network to endow it with greater computational complexity and consequently representational power. Example scaling strategies may include increasing model width, depth, resolution, etc. While various scaling strategies exist, their tradeoffs are not fully understood. Existing analysis typically focuses on the interplay of accuracy and flops (floating point operations). Yet, as we demonstrate, various scaling strategies affect model parameters, activations, and consequently actual runtime quite differently. In our experiments we show the surprising result that numerous scaling strategies yield networks with similar accuracy but with widely varying properties. This leads us to propose a simple fast compound scaling strategy that encourages primarily scaling model width, while scaling depth and resolution to a lesser extent. Unlike currently popular scaling strategies, which result in about $O(s)$ increase in model activation w.r.t. scaling flops by a factor of $s$, the proposed fast compound scaling results in close to $O(\sqrt{s})$ increase in activations, while achieving excellent accuracy. This leads to comparable speedups on modern memory-limited hardware (e.g., GPU, TPU). More generally, we hope this work provides a framework for analyzing and selecting scaling strategies under various computational constraints.
Evaluating Large-Vocabulary Object Detectors: The Devil is in the Details
Feb 01, 2021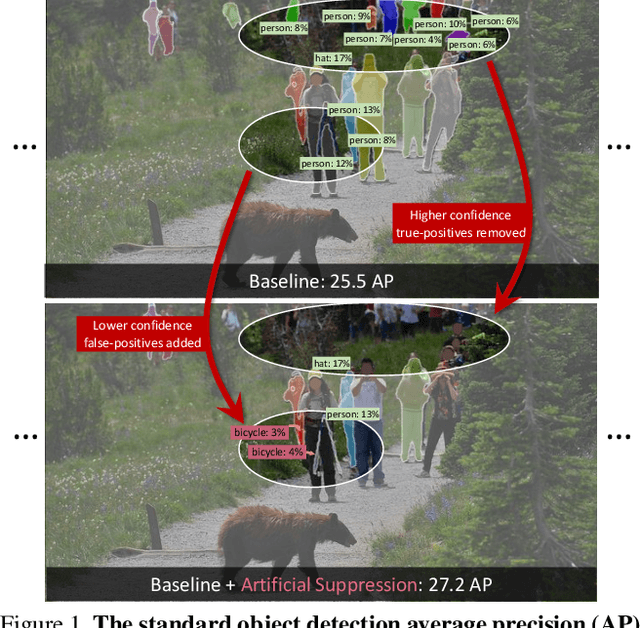

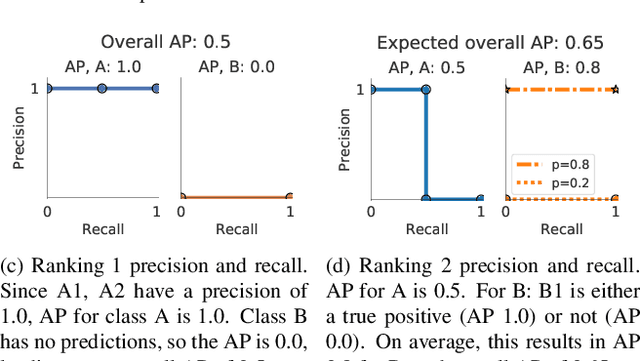
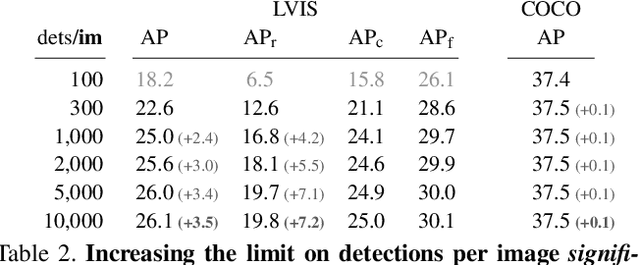
By design, average precision (AP) for object detection aims to treat all classes independently: AP is computed independently per category and averaged. On the one hand, this is desirable as it treats all classes, rare to frequent, equally. On the other hand, it ignores cross-category confidence calibration, a key property in real-world use cases. Unfortunately, we find that on imbalanced, large-vocabulary datasets, the default implementation of AP is neither category independent, nor does it directly reward properly calibrated detectors. In fact, we show that the default implementation produces a gameable metric, where a simple, nonsensical re-ranking policy can improve AP by a large margin. To address these limitations, we introduce two complementary metrics. First, we present a simple fix to the default AP implementation, ensuring that it is truly independent across categories as originally intended. We benchmark recent advances in large-vocabulary detection and find that many reported gains do not translate to improvements under our new per-class independent evaluation, suggesting recent improvements may arise from difficult to interpret changes to cross-category rankings. Given the importance of reliably benchmarking cross-category rankings, we consider a pooled version of AP (AP-pool) that rewards properly calibrated detectors by directly comparing cross-category rankings. Finally, we revisit classical approaches for calibration and find that explicitly calibrating detectors improves state-of-the-art on AP-pool by 1.7 points.
Large scale weakly and semi-supervised learning for low-resource video ASR
May 16, 2020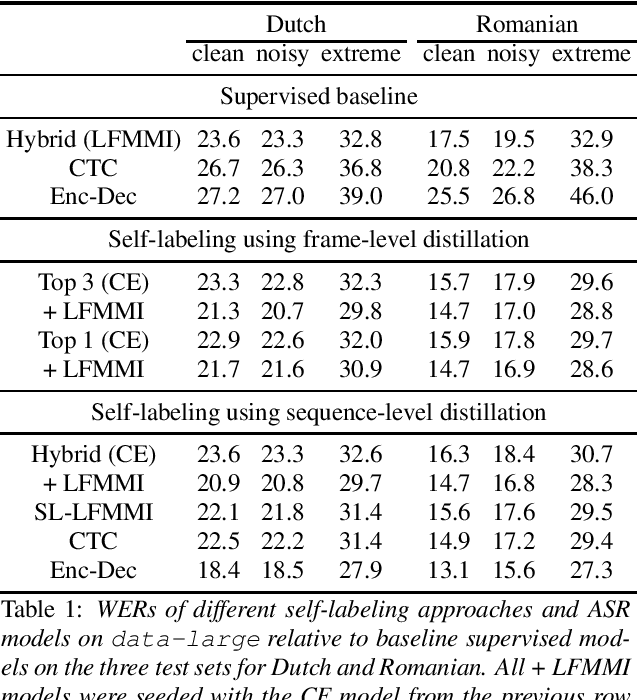
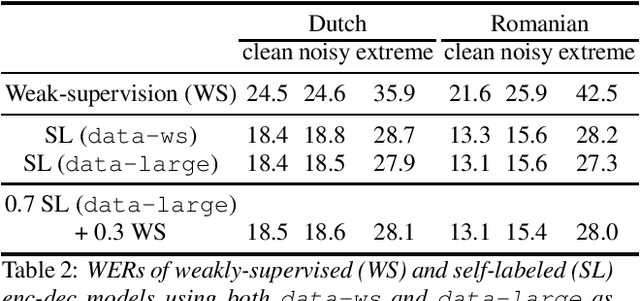
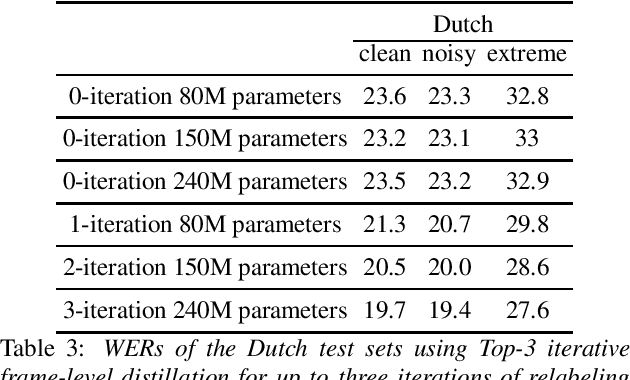
Many semi- and weakly-supervised approaches have been investigated for overcoming the labeling cost of building high quality speech recognition systems. On the challenging task of transcribing social media videos in low-resource conditions, we conduct a large scale systematic comparison between two self-labeling methods on one hand, and weakly-supervised pretraining using contextual metadata on the other. We investigate distillation methods at the frame level and the sequence level for hybrid, encoder-only CTC-based, and encoder-decoder speech recognition systems on Dutch and Romanian languages using 27,000 and 58,000 hours of unlabeled audio respectively. Although all approaches improved upon their respective baseline WERs by more than 8%, sequence-level distillation for encoder-decoder models provided the largest relative WER reduction of 20% compared to the strongest data-augmented supervised baseline.
Designing Network Design Spaces
Mar 30, 2020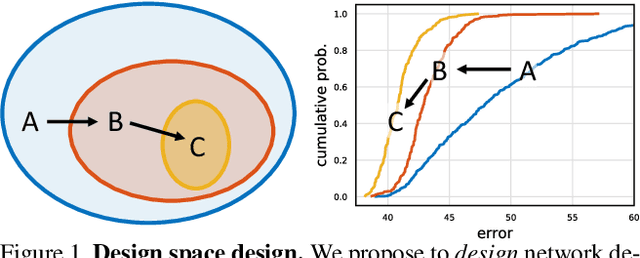
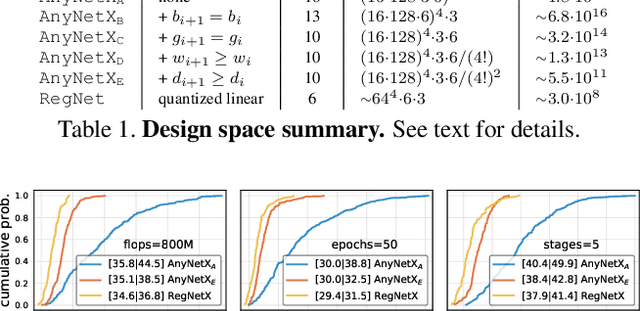
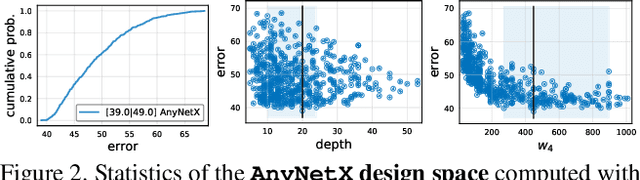
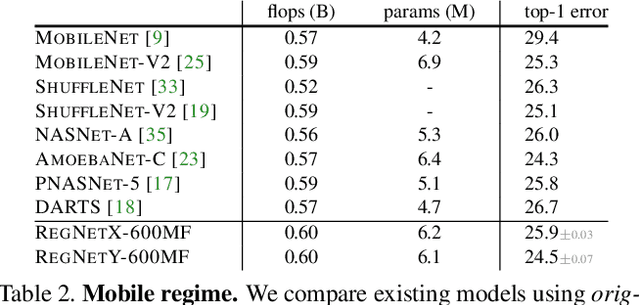
In this work, we present a new network design paradigm. Our goal is to help advance the understanding of network design and discover design principles that generalize across settings. Instead of focusing on designing individual network instances, we design network design spaces that parametrize populations of networks. The overall process is analogous to classic manual design of networks, but elevated to the design space level. Using our methodology we explore the structure aspect of network design and arrive at a low-dimensional design space consisting of simple, regular networks that we call RegNet. The core insight of the RegNet parametrization is surprisingly simple: widths and depths of good networks can be explained by a quantized linear function. We analyze the RegNet design space and arrive at interesting findings that do not match the current practice of network design. The RegNet design space provides simple and fast networks that work well across a wide range of flop regimes. Under comparable training settings and flops, the RegNet models outperform the popular EfficientNet models while being up to 5x faster on GPUs.
Are Labels Necessary for Neural Architecture Search?
Mar 26, 2020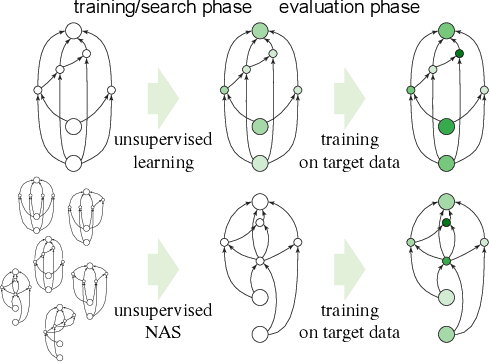
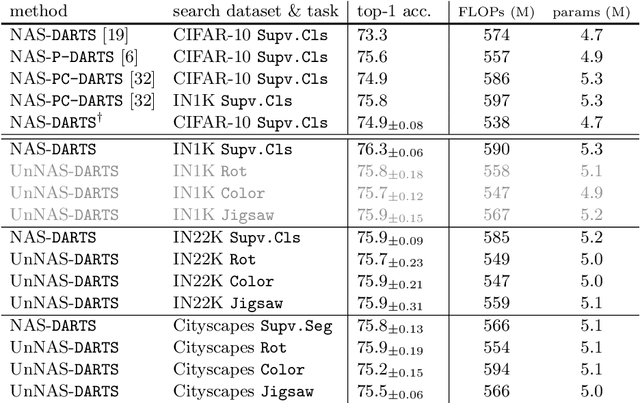
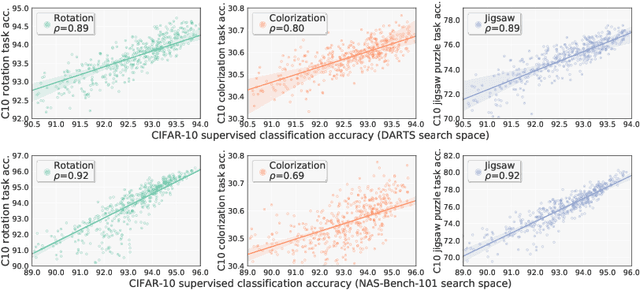
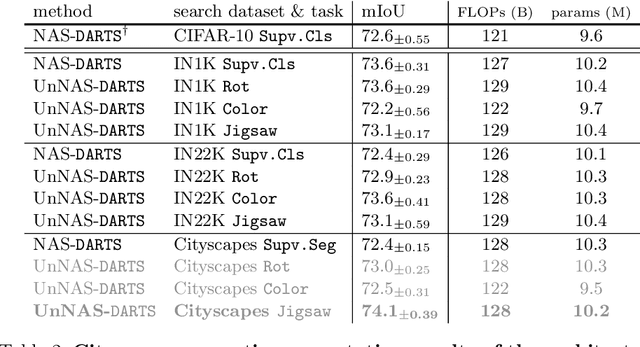
Existing neural network architectures in computer vision --- whether designed by humans or by machines --- were typically found using both images and their associated labels. In this paper, we ask the question: can we find high-quality neural architectures using only images, but no human-annotated labels? To answer this question, we first define a new setup called Unsupervised Neural Architecture Search (UnNAS). We then conduct two sets of experiments. In sample-based experiments, we train a large number (500) of diverse architectures with either supervised or unsupervised objectives, and find that the architecture rankings produced with and without labels are highly correlated. In search-based experiments, we run a well-established NAS algorithm (DARTS) using various unsupervised objectives, and report that the architectures searched without labels can be competitive to their counterparts searched with labels. Together, these results reveal the potentially surprising finding that labels are not necessary, and the image statistics alone may be sufficient to identify good neural architectures.
Improved Baselines with Momentum Contrastive Learning
Mar 09, 2020
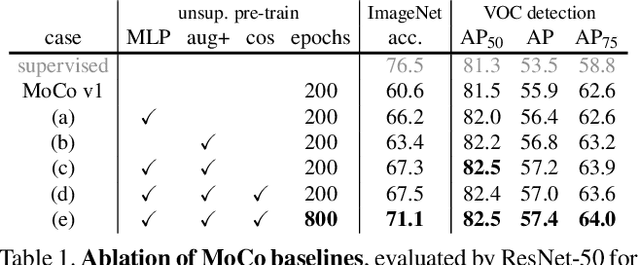
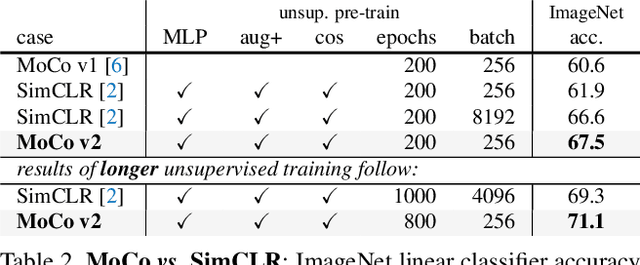

Contrastive unsupervised learning has recently shown encouraging progress, e.g., in Momentum Contrast (MoCo) and SimCLR. In this note, we verify the effectiveness of two of SimCLR's design improvements by implementing them in the MoCo framework. With simple modifications to MoCo---namely, using an MLP projection head and more data augmentation---we establish stronger baselines that outperform SimCLR and do not require large training batches. We hope this will make state-of-the-art unsupervised learning research more accessible. Code will be made public.