 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Network-based Word Alignment through Score Aggregation
Jun 30, 2016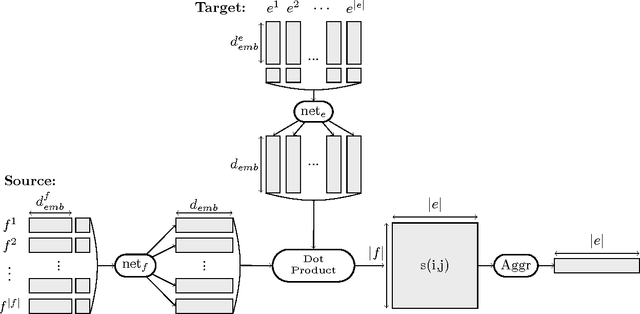
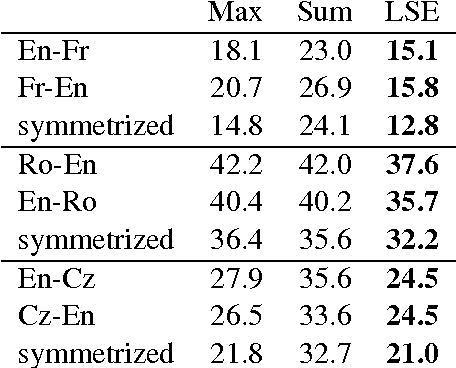
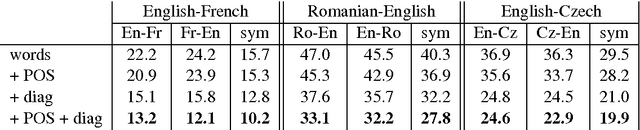
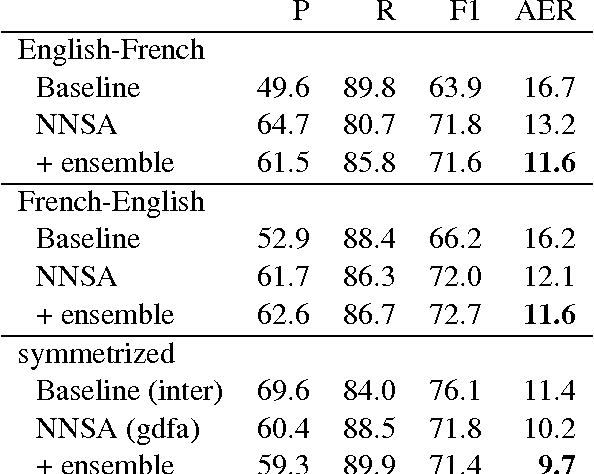
We present a simple neural network for word alignment that builds source and target word window representations to compute alignment scores for sentence pairs. To enable unsupervised training, we use an aggregation operation that summarizes the alignment scores for a given target word. A soft-margin objective increases scores for true target words while decreasing scores for target words that are not present. Compared to the popular Fast Align model, our approach improves alignment accuracy by 7 AER on English-Czech, by 6 AER on Romanian-English and by 1.7 AER on English-French alignment.
Video (language) modeling: a baseline for generative models of natural videos
May 04, 2016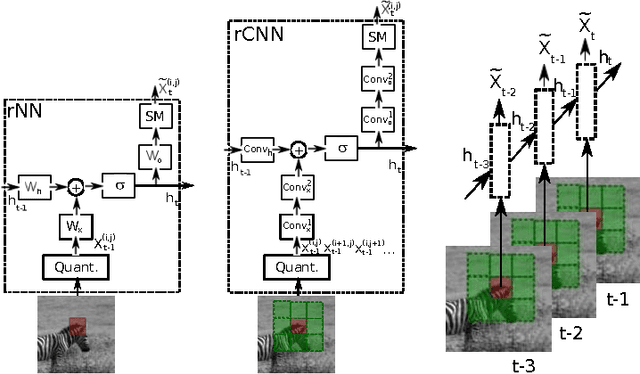



We propose a strong baseline model for unsupervised feature learning using video data. By learning to predict missing frames or extrapolate future frames from an input video sequence, the model discovers both spatial and temporal correlations which are useful to represent complex deformations and motion patterns. The models we propose are largely borrowed from the language modeling literature, and adapted to the vision domain by quantizing the space of image patches into a large dictionary. We demonstrate the approach on both a filling and a generation task. For the first time, we show that, after training on natural videos, such a model can predict non-trivial motions over short video sequences.
ProNet: Learning to Propose Object-specific Boxes for Cascaded Neural Networks
Apr 13, 2016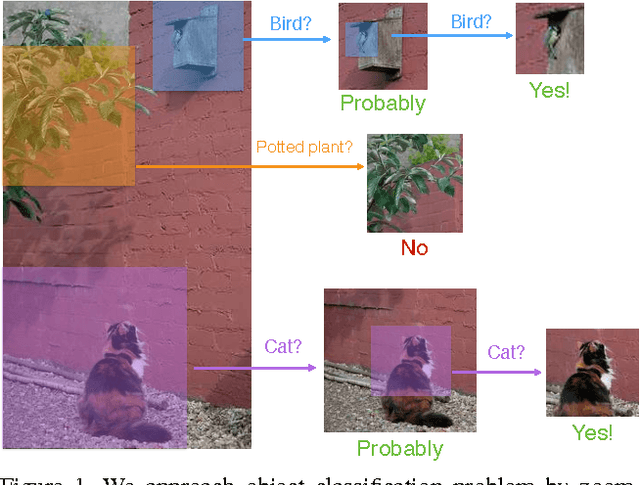

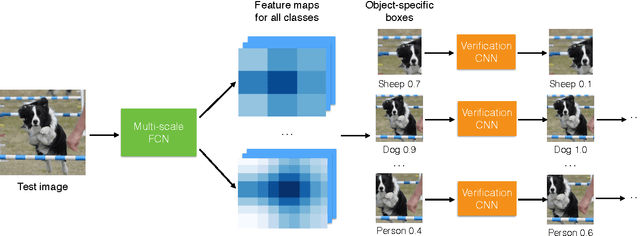

This paper aims to classify and locate objects accurately and efficiently, without using bounding box annotations. It is challenging as objects in the wild could appear at arbitrary locations and in different scales. In this paper, we propose a novel classification architecture ProNet based on convolutional neural networks. It uses computationally efficient neural networks to propose image regions that are likely to contain objects, and applies more powerful but slower networks on the proposed regions. The basic building block is a multi-scale fully-convolutional network which assigns object confidence scores to boxes at different locations and scales. We show that such networks can be trained effectively using image-level annotations, and can be connected into cascades or trees for efficient object classification. ProNet outperforms previous state-of-the-art significantly on PASCAL VOC 2012 and MS COCO datasets for object classification and point-based localization.
Learning to Segment Object Candidates
Sep 01, 2015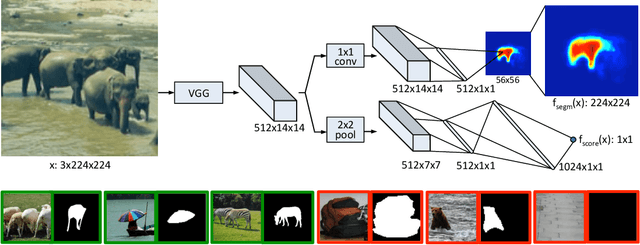
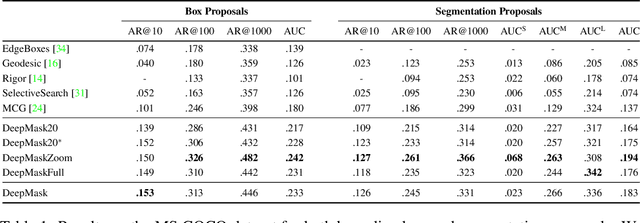


Recent object detection systems rely on two critical steps: (1) a set of object proposals is predicted as efficiently as possible, and (2) this set of candidate proposals is then passed to an object classifier. Such approaches have been shown they can be fast, while achieving the state of the art in detection performance. In this paper, we propose a new way to generate object proposals, introducing an approach based on a discriminative convolutional network. Our model is trained jointly with two objectives: given an image patch, the first part of the system outputs a class-agnostic segmentation mask, while the second part of the system outputs the likelihood of the patch being centered on a full object. At test time, the model is efficiently applied on the whole test image and generates a set of segmentation masks, each of them being assigned with a corresponding object likelihood score. We show that our model yields significant improvements over state-of-the-art object proposal algorithms. In particular, compared to previous approaches, our model obtains substantially higher object recall using fewer proposals. We also show that our model is able to generalize to unseen categories it has not seen during training. Unlike all previous approaches for generating object masks, we do not rely on edges, superpixels, or any other form of low-level segmentation.
"The Sum of Its Parts": Joint Learning of Word and Phrase Representations with Autoencoders
Jun 18, 2015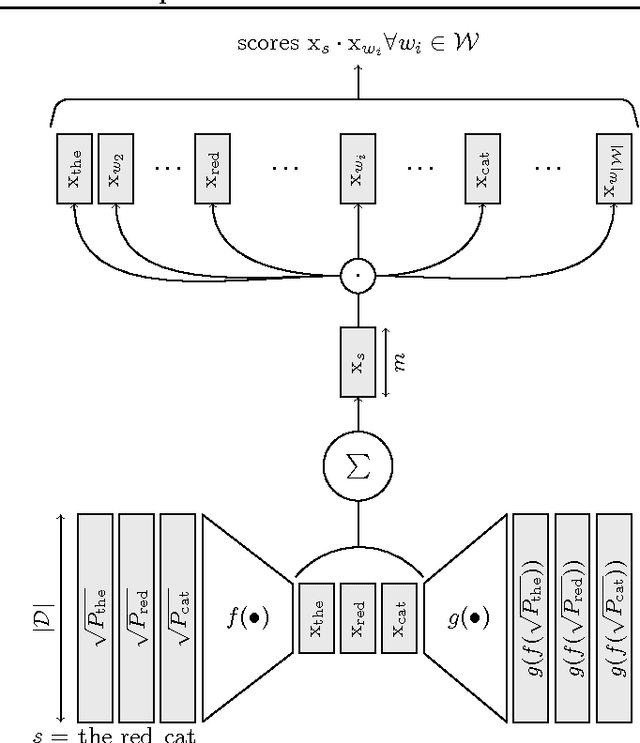
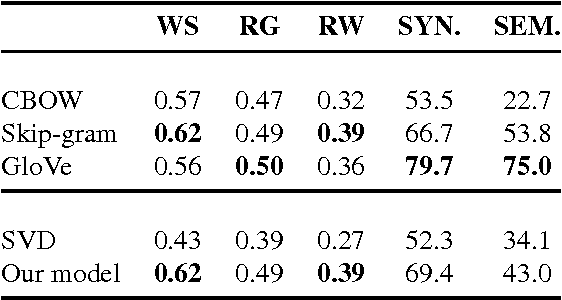
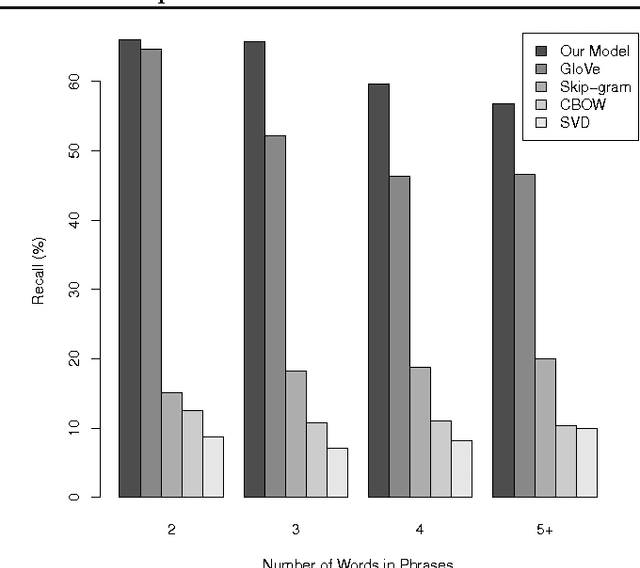
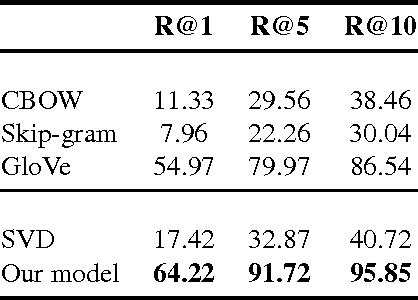
Recently, there has been a lot of effort to represent words in continuous vector spaces. Those representations have been shown to capture both semantic and syntactic information about words. However, distributed representations of phrases remain a challenge. We introduce a novel model that jointly learns word vector representations and their summation. Word representations are learnt using the word co-occurrence statistical information. To embed sequences of words (i.e. phrases) with different sizes into a common semantic space, we propose to average word vector representations. In contrast with previous methods which reported a posteriori some compositionality aspects by simple summation, we simultaneously train words to sum, while keeping the maximum information from the original vectors. We evaluate the quality of the word representations on several classical word evaluation tasks, and we introduce a novel task to evaluate the quality of the phrase representations. While our distributed representations compete with other methods of learning word representations on word evaluations, we show that they give better performance on the phrase evaluation. Such representations of phrases could be interesting for many tasks in natural language processing.
From Image-level to Pixel-level Labeling with Convolutional Networks
Apr 24, 2015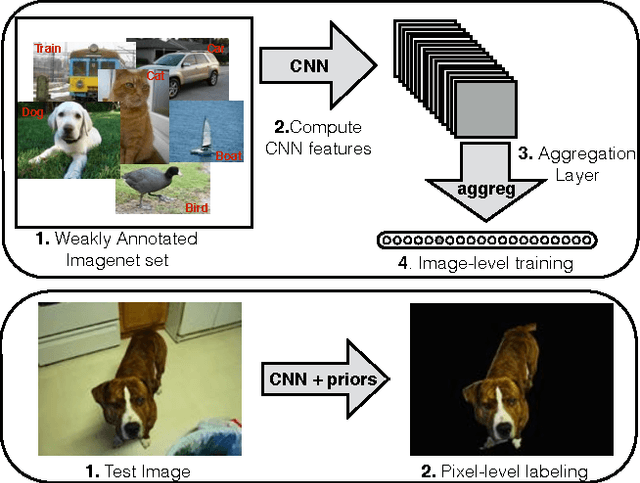
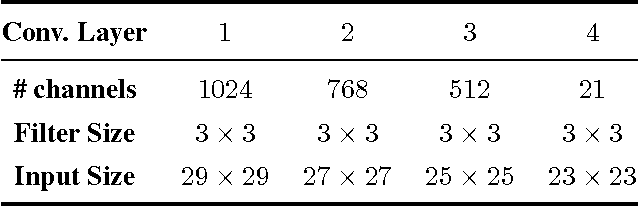
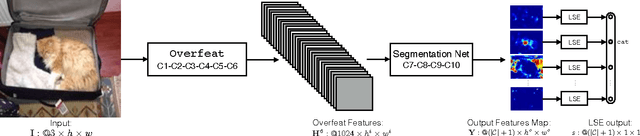
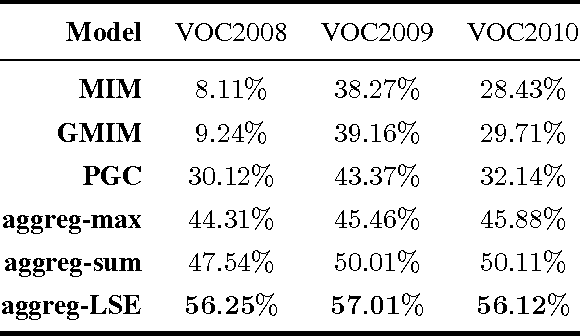
We are interested in inferring object segmentation by leveraging only object class information, and by considering only minimal priors on the object segmentation task. This problem could be viewed as a kind of weakly supervised segmentation task, and naturally fits the Multiple Instance Learning (MIL) framework: every training image is known to have (or not) at least one pixel corresponding to the image class label, and the segmentation task can be rewritten as inferring the pixels belonging to the class of the object (given one image, and its object class). We propose a Convolutional Neural Network-based model, which is constrained during training to put more weight on pixels which are important for classifying the image. We show that at test time, the model has learned to discriminate the right pixels well enough, such that it performs very well on an existing segmentation benchmark, by adding only few smoothing priors. Our system is trained using a subset of the Imagenet dataset and the segmentation experiments are performed on the challenging Pascal VOC dataset (with no fine-tuning of the model on Pascal VOC). Our model beats the state of the art results in weakly supervised object segmentation task by a large margin. We also compare the performance of our model with state of the art fully-supervised segmentation approaches.
Learning linearly separable features for speech recognition using convolutional neural networks
Apr 16, 2015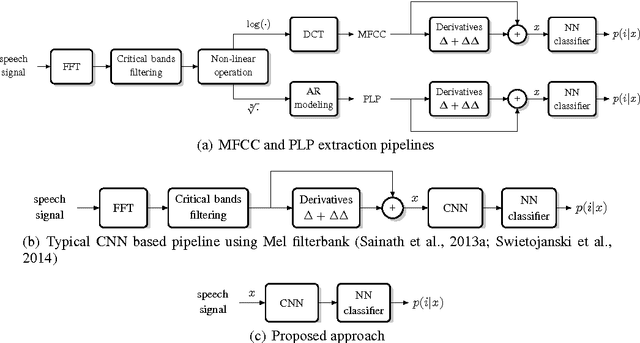
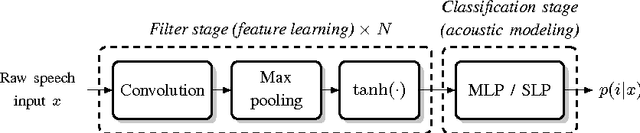
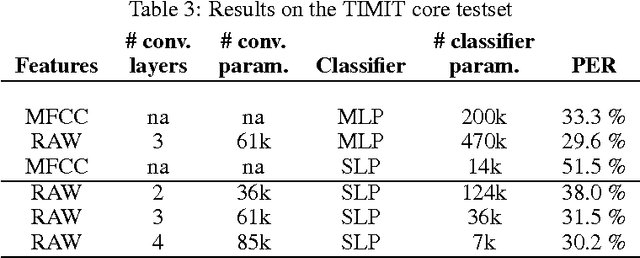
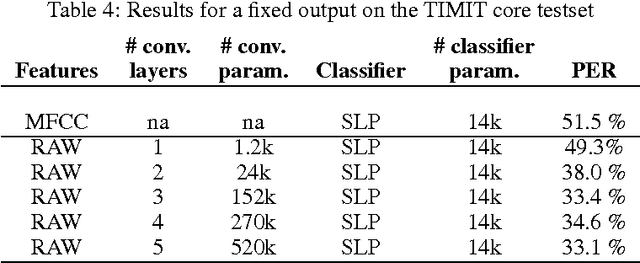
Automatic speech recognition systems usually rely on spectral-based features, such as MFCC of PLP. These features are extracted based on prior knowledge such as, speech perception or/and speech production. Recently, convolutional neural networks have been shown to be able to estimate phoneme conditional probabilities in a completely data-driven manner, i.e. using directly temporal raw speech signal as input. This system was shown to yield similar or better performance than HMM/ANN based system on phoneme recognition task and on large scale continuous speech recognition task, using less parameters. Motivated by these studies, we investigate the use of simple linear classifier in the CNN-based framework. Thus, the network learns linearly separable features from raw speech. We show that such system yields similar or better performance than MLP based system using cepstral-based features as input.
Simple Image Description Generator via a Linear Phrase-Based Approach
Apr 11, 2015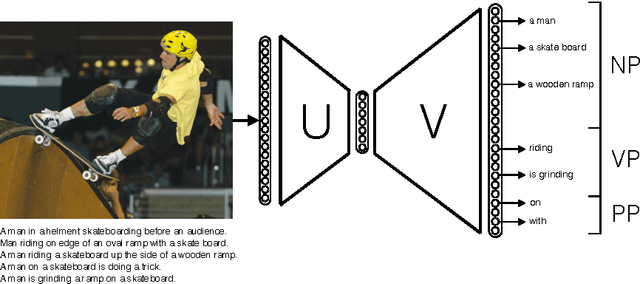
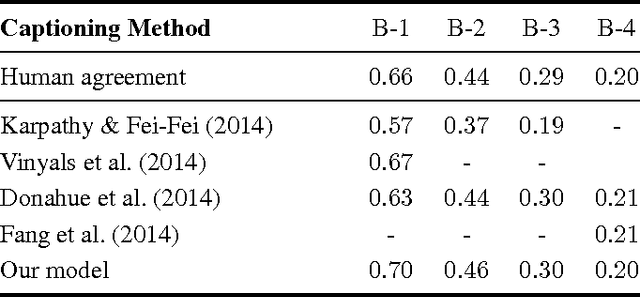
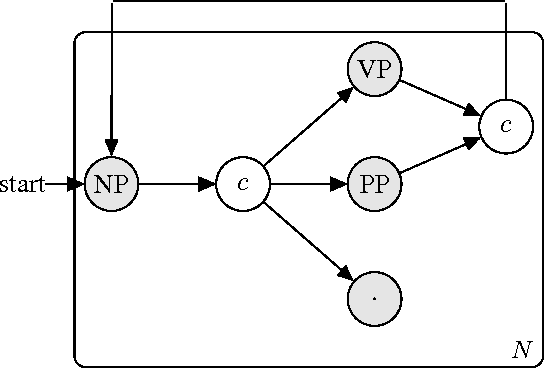
Generating a novel textual description of an image is an interesting problem that connects computer vision and natural language processing. In this paper, we present a simple model that is able to generate descriptive sentences given a sample image. This model has a strong focus on the syntax of the descriptions. We train a purely bilinear model that learns a metric between an image representation (generated from a previously trained Convolutional Neural Network) and phrases that are used to described them. The system is then able to infer phrases from a given image sample. Based on caption syntax statistics, we propose a simple language model that can produce relevant descriptions for a given test image using the phrases inferred. Our approach, which is considerably simpler than state-of-the-art models, achieves comparable results on the recently release Microsoft COCO dataset.
Joint RNN-Based Greedy Parsing and Word Composition
Apr 10, 2015

This paper introduces a greedy parser based on neural networks, which leverages a new compositional sub-tree representation. The greedy parser and the compositional procedure are jointly trained, and tightly depends on each-other. The composition procedure outputs a vector representation which summarizes syntactically (parsing tags) and semantically (words) sub-trees. Composition and tagging is achieved over continuous (word or tag) representations, and recurrent neural networks. We reach F1 performance on par with well-known existing parsers, while having the advantage of speed, thanks to the greedy nature of the parser. We provide a fully functional implementation of the method described in this paper.
N-gram-Based Low-Dimensional Representation for Document Classification
Apr 10, 2015
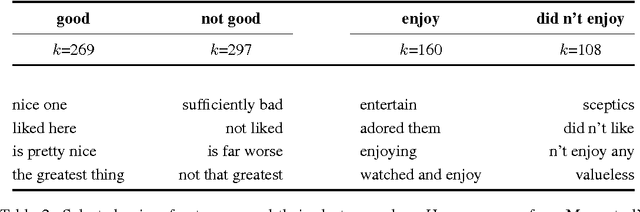
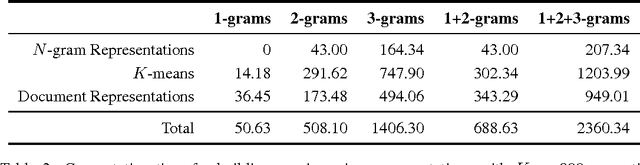
The bag-of-words (BOW) model is the common approach for classifying documents, where words are used as feature for training a classifier. This generally involves a huge number of features. Some techniques, such as Latent Semantic Analysis (LSA) or Latent Dirichlet Allocation (LDA), have been designed to summarize documents in a lower dimension with the least semantic information loss. Some semantic information is nevertheless always lost, since only words are considered. Instead, we aim at using information coming from n-grams to overcome this limitation, while remaining in a low-dimension space. Many approaches, such as the Skip-gram model, provide good word vector representations very quickly. We propose to average these representations to obtain representations of n-grams. All n-grams are thus embedded in a same semantic space. A K-means clustering can then group them into semantic concepts. The number of features is therefore dramatically reduced and documents can be represented as bag of semantic concepts. We show that this model outperforms LSA and LDA on a sentiment classification task, and yields similar results than a traditional BOW-model with far less features.