 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeN-gram-Based Low-Dimensional Representation for Document Classification
Paper and Code
Apr 10, 2015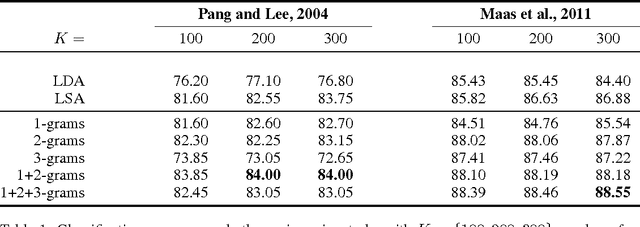
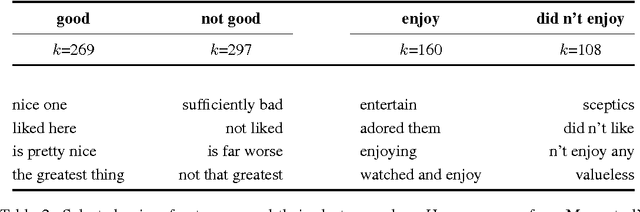
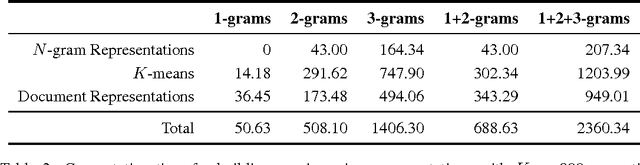
The bag-of-words (BOW) model is the common approach for classifying documents, where words are used as feature for training a classifier. This generally involves a huge number of features. Some techniques, such as Latent Semantic Analysis (LSA) or Latent Dirichlet Allocation (LDA), have been designed to summarize documents in a lower dimension with the least semantic information loss. Some semantic information is nevertheless always lost, since only words are considered. Instead, we aim at using information coming from n-grams to overcome this limitation, while remaining in a low-dimension space. Many approaches, such as the Skip-gram model, provide good word vector representations very quickly. We propose to average these representations to obtain representations of n-grams. All n-grams are thus embedded in a same semantic space. A K-means clustering can then group them into semantic concepts. The number of features is therefore dramatically reduced and documents can be represented as bag of semantic concepts. We show that this model outperforms LSA and LDA on a sentiment classification task, and yields similar results than a traditional BOW-model with far less features.