 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring the Robustness of Natural Language Processing Models to Domain Shifts
May 31, 2023



Large Language Models have shown promising performance on various tasks, including fine-tuning, few-shot learning, and zero-shot learning. However, their performance on domains without labeled data still lags behind those with labeled data, which we refer as the Domain Robustness (DR) challenge. Existing research on DR suffers from disparate setups, lack of evaluation task variety, and reliance on challenge sets. In this paper, we explore the DR challenge of both fine-tuned and few-shot learning models in natural domain shift settings. We introduce a DR benchmark comprising diverse NLP tasks, including sentence and token-level classification, QA, and generation, each task consists of several domains. We propose two views of the DR challenge: Source Drop (SD) and Target Drop (TD), which alternate between the source and target in-domain performance as reference points. We find that in significant proportions of domain shifts, either SD or TD is positive, but not both, emphasizing the importance of considering both measures as diagnostic tools. Our experimental results demonstrate the persistent existence of the DR challenge in both fine-tuning and few-shot learning models, though it is less pronounced in the latter. We also find that increasing the fine-tuned model size improves performance, particularly in classification.
Human Choice Prediction in Language-based Non-Cooperative Games: Simulation-based Off-Policy Evaluation
May 23, 2023Persuasion games have been fundamental in economics and AI research, and have significant practical applications. Recent works in this area have started to incorporate natural language, moving beyond the traditional stylized message setting. However, previous research has focused on on-policy prediction, where the train and test data have the same distribution, which is not representative of real-life scenarios. In this paper, we tackle the challenging problem of off-policy evaluation (OPE) in language-based persuasion games. To address the inherent difficulty of human data collection in this setup, we propose a novel approach which combines real and simulated human-bot interaction data. Our simulated data is created by an exogenous model assuming decision makers (DMs) start with a mixture of random and decision-theoretic based behaviors and improve over time. We present a deep learning training algorithm that effectively integrates real interaction and simulated data, substantially improving over models that train only with interaction data. Our results demonstrate the potential of real interaction and simulation mixtures as a cost-effective and scalable solution for OPE in language-based persuasion games.\footnote{Our code and the large dataset we collected and generated are submitted as supplementary material and will be made publicly available upon acceptance.
A Systematic Study of Knowledge Distillation for Natural Language Generation with Pseudo-Target Training
May 03, 2023



Modern Natural Language Generation (NLG) models come with massive computational and storage requirements. In this work, we study the potential of compressing them, which is crucial for real-world applications serving millions of users. We focus on Knowledge Distillation (KD) techniques, in which a small student model learns to imitate a large teacher model, allowing to transfer knowledge from the teacher to the student. In contrast to much of the previous work, our goal is to optimize the model for a specific NLG task and a specific dataset. Typically, in real-world applications, in addition to labeled data there is abundant unlabeled task-specific data, which is crucial for attaining high compression rates via KD. In this work, we conduct a systematic study of task-specific KD techniques for various NLG tasks under realistic assumptions. We discuss the special characteristics of NLG distillation and particularly the exposure bias problem. Following, we derive a family of Pseudo-Target (PT) augmentation methods, substantially extending prior work on sequence-level KD. We propose the Joint-Teaching method for NLG distillation, which applies word-level KD to multiple PTs generated by both the teacher and the student. Our study provides practical model design observations and demonstrates the effectiveness of PT training for task-specific KD in NLG.
A Picture May Be Worth a Thousand Lives: An Interpretable Artificial Intelligence Strategy for Predictions of Suicide Risk from Social Media Images
Feb 19, 2023



The promising research on Artificial Intelligence usages in suicide prevention has principal gaps, including black box methodologies, inadequate outcome measures, and scarce research on non-verbal inputs, such as social media images (despite their popularity today, in our digital era). This study addresses these gaps and combines theory-driven and bottom-up strategies to construct a hybrid and interpretable prediction model of valid suicide risk from images. The lead hypothesis was that images contain valuable information about emotions and interpersonal relationships, two central concepts in suicide-related treatments and theories. The dataset included 177,220 images by 841 Facebook users who completed a gold-standard suicide scale. The images were represented with CLIP, a state-of-the-art algorithm, which was utilized, unconventionally, to extract predefined features that served as inputs to a simple logistic-regression prediction model (in contrast to complex neural networks). The features addressed basic and theory-driven visual elements using everyday language (e.g., bright photo, photo of sad people). The results of the hybrid model (that integrated theory-driven and bottom-up methods) indicated high prediction performance that surpassed common bottom-up algorithms, thus providing a first proof that images (alone) can be leveraged to predict validated suicide risk. Corresponding with the lead hypothesis, at-risk users had images with increased negative emotions and decreased belonginess. The results are discussed in the context of non-verbal warning signs of suicide. Notably, the study illustrates the advantages of hybrid models in such complicated tasks and provides simple and flexible prediction strategies that could be utilized to develop real-life monitoring tools of suicide.
Text2Model: Model Induction for Zero-shot Generalization Using Task Descriptions
Oct 27, 2022



We study the problem of generating a training-free task-dependent visual classifier from text descriptions without visual samples. This \textit{Text-to-Model} (T2M) problem is closely related to zero-shot learning, but unlike previous work, a T2M model infers a model tailored to a task, taking into account all classes in the task. We analyze the symmetries of T2M, and characterize the equivariance and invariance properties of corresponding models. In light of these properties, we design an architecture based on hypernetworks that given a set of new class descriptions predicts the weights for an object recognition model which classifies images from those zero-shot classes. We demonstrate the benefits of our approach compared to zero-shot learning from text descriptions in image and point-cloud classification using various types of text descriptions: From single words to rich text descriptions.
Domain Adaptation from Scratch
Sep 02, 2022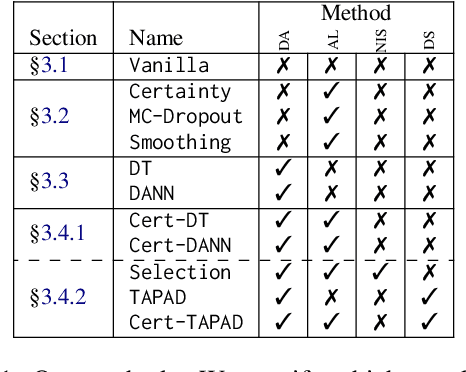
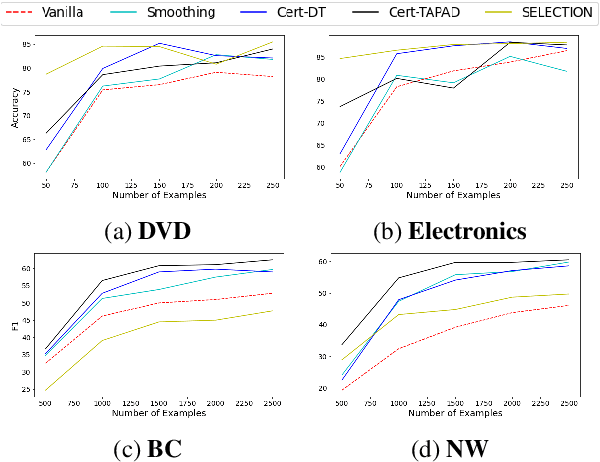
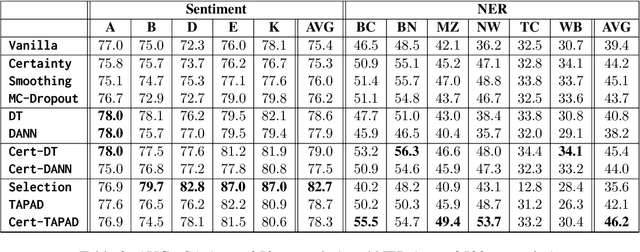
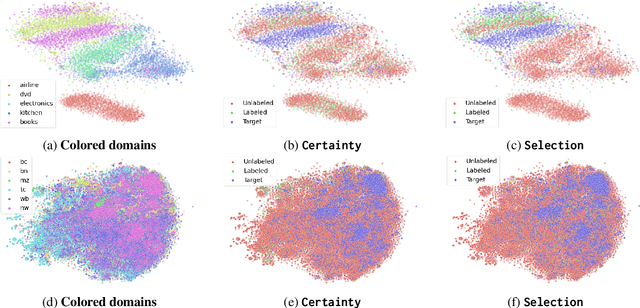
Natural language processing (NLP) algorithms are rapidly improving but often struggle when applied to out-of-distribution examples. A prominent approach to mitigate the domain gap is domain adaptation, where a model trained on a source domain is adapted to a new target domain. We present a new learning setup, ``domain adaptation from scratch'', which we believe to be crucial for extending the reach of NLP to sensitive domains in a privacy-preserving manner. In this setup, we aim to efficiently annotate data from a set of source domains such that the trained model performs well on a sensitive target domain from which data is unavailable for annotation. Our study compares several approaches for this challenging setup, ranging from data selection and domain adaptation algorithms to active learning paradigms, on two NLP tasks: sentiment analysis and Named Entity Recognition. Our results suggest that using the abovementioned approaches eases the domain gap, and combining them further improves the results.
Multi-task Active Learning for Pre-trained Transformer-based Models
Aug 10, 2022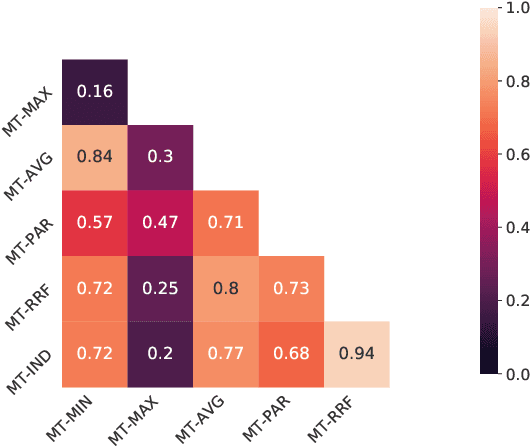
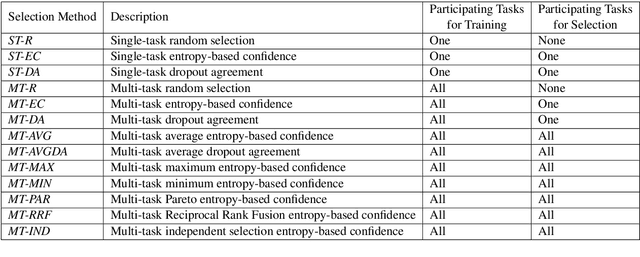

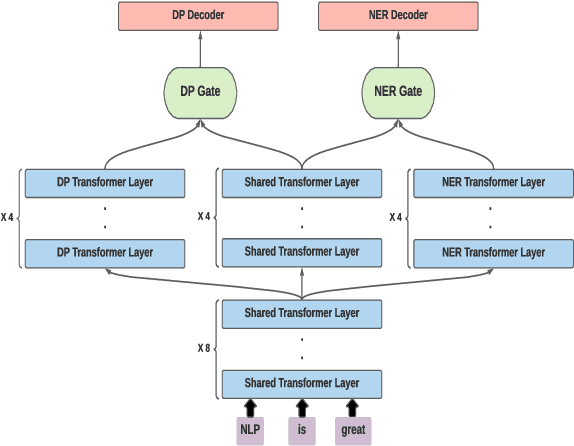
Multi-task learning, in which several tasks are jointly learned by a single model, allows NLP models to share information from multiple annotations and may facilitate better predictions when the tasks are inter-related. This technique, however, requires annotating the same text with multiple annotation schemes which may be costly and laborious. Active learning (AL) has been demonstrated to optimize annotation processes by iteratively selecting unlabeled examples whose annotation is most valuable for the NLP model. Yet, multi-task active learning (MT-AL) has not been applied to state-of-the-art pre-trained Transformer-based NLP models. This paper aims to close this gap. We explore various multi-task selection criteria in three realistic multi-task scenarios, reflecting different relations between the participating tasks, and demonstrate the effectiveness of multi-task compared to single-task selection. Our results suggest that MT-AL can be effectively used in order to minimize annotation efforts for multi-task NLP models.
On the Robustness of Dialogue History Representation in Conversational Question Answering: A Comprehensive Study and a New Prompt-based Method
Jun 29, 2022
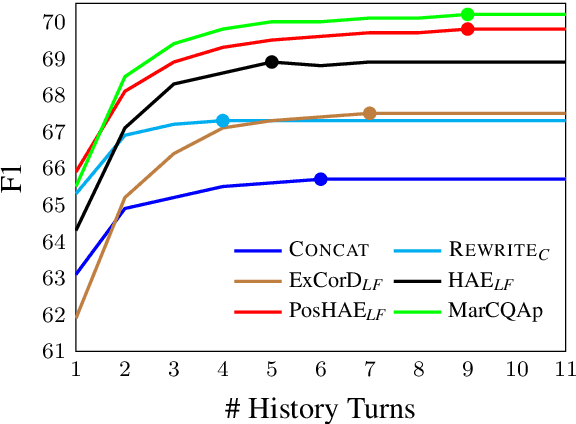
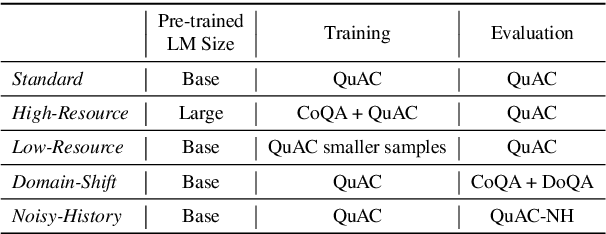
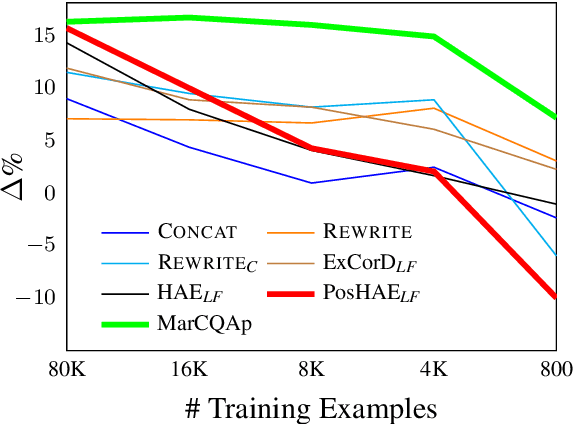
Most works on modeling the conversation history in Conversational Question Answering (CQA) report a single main result on a common CQA benchmark. While existing models show impressive results on CQA leaderboards, it remains unclear whether they are robust to shifts in setting (sometimes to more realistic ones), training data size (e.g. from large to small sets) and domain. In this work, we design and conduct the first large-scale robustness study of history modeling approaches for CQA. We find that high benchmark scores do not necessarily translate to strong robustness, and that various methods can perform extremely differently under different settings. Equipped with the insights from our study, we design a novel prompt-based history modeling approach, and demonstrate its strong robustness across various settings. Our approach is inspired by existing methods that highlight historic answers in the passage. However, instead of highlighting by modifying the passage token embeddings, we add textual prompts directly in the passage text. Our approach is simple, easy-to-plug into practically any model, and highly effective, thus we recommend it as a starting point for future model developers. We also hope that our study and insights will raise awareness to the importance of robustness-focused evaluation, in addition to obtaining high leaderboard scores, leading to better CQA systems.
A Functional Information Perspective on Model Interpretation
Jun 14, 2022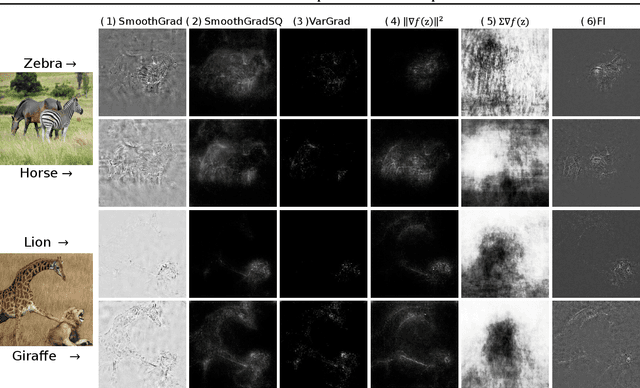
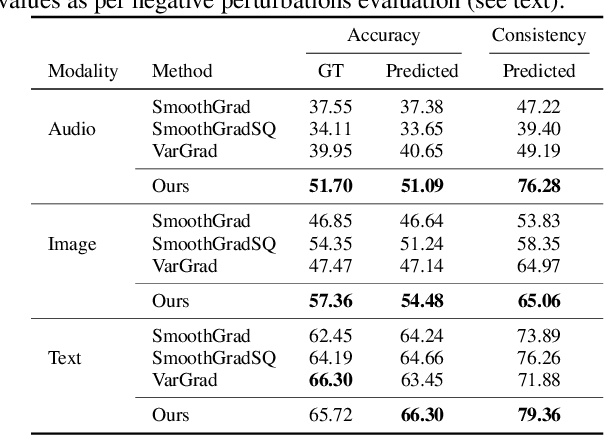

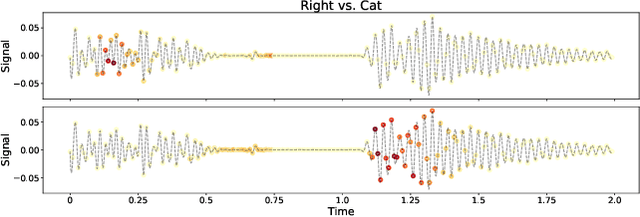
Contemporary predictive models are hard to interpret as their deep nets exploit numerous complex relations between input elements. This work suggests a theoretical framework for model interpretability by measuring the contribution of relevant features to the functional entropy of the network with respect to the input. We rely on the log-Sobolev inequality that bounds the functional entropy by the functional Fisher information with respect to the covariance of the data. This provides a principled way to measure the amount of information contribution of a subset of features to the decision function. Through extensive experiments, we show that our method surpasses existing interpretability sampling-based methods on various data signals such as image, text, and audio.
In the Eye of the Beholder: Robust Prediction with Causal User Modeling
Jun 01, 2022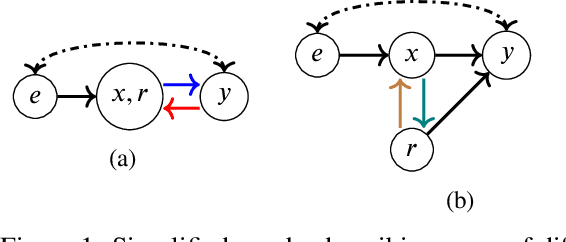

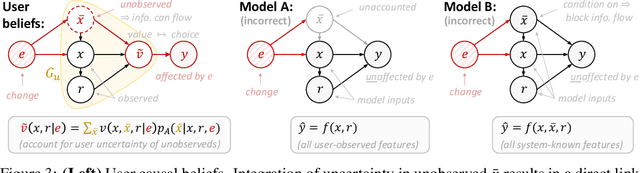
Accurately predicting the relevance of items to users is crucial to the success of many social platforms. Conventional approaches train models on logged historical data; but recommendation systems, media services, and online marketplaces all exhibit a constant influx of new content -- making relevancy a moving target, to which standard predictive models are not robust. In this paper, we propose a learning framework for relevance prediction that is robust to changes in the data distribution. Our key observation is that robustness can be obtained by accounting for how users causally perceive the environment. We model users as boundedly-rational decision makers whose causal beliefs are encoded by a causal graph, and show how minimal information regarding the graph can be used to contend with distributional changes. Experiments in multiple settings demonstrate the effectiveness of our approach.