 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTRABLE: Benchmarking Tabular Machine Learning with Strings
May 12, 2026Benchmarking tabular learning has revealed the benefit of dedicated architectures, pushing the state of the art. But real-world tables often contain string entries, beyond numbers, and these settings have been understudied due to a lack of a solid benchmarking suite. They lead to new research questions: Are dedicated learners needed, with end-to-end modeling of strings and numbers? Or does it suffice to encode strings as numbers, as with a categorical encoding? And if so, do the resulting tables resemble numerical tabular data, calling for the same learners? To enable these studies, we contribute STRABLE, a benchmarking corpus of 108 tables, all real-world learning problems with strings and numbers across diverse application fields. We run the first large-scale empirical study of tabular learning with strings, evaluating 445 pipelines. These pipelines span end-to-end architectures and modular pipelines, where strings are first encoded, then post-processed, and finally passed to a tabular learner. We find that, because most tables in the wild are categorical-dominant, advanced tabular learners paired with simple string embeddings achieve good predictions at low computational cost. On free-text-dominant tables, large LLM encoders become competitive. Their performance also appears sensitive to post-processing, with differences across LLM families. Finally, we show that STRABLE is a good set of tables to study "string tabular" learning as it leads to generalizable pipeline rankings that are close to the oracle rankings. We thus establish STRABLE as a foundation for research on tabular learning with strings, an important yet understudied area.
Predicting Decisions of AI Agents from Limited Interaction through Text-Tabular Modeling
May 12, 2026AI agents negotiate and transact in natural language with unfamiliar counterparts: a buyer bot facing an unknown seller, or a procurement assistant negotiating with a supplier. In such interactions, the counterpart's LLM, prompts, control logic, and rule-based fallbacks are hidden, while each decision can have monetary consequences. We ask whether an agent can predict an unfamiliar counterpart's next decision from a few interactions. To avoid real-world logging confounds, we study this problem in controlled bargaining and negotiation games, formulating it as target-adaptive text-tabular prediction: each decision point is a table row combining structured game state, offer history, and dialogue, while $K$ previous games of the same target agent, i.e., the counterpart being modeled, are provided in the prompt as labeled adaptation examples. Our model is built on a tabular foundation model that represents rows using game-state features and LLM-based text representations, and adds LLM-as-Observer as an additional representation: a small frozen LLM reads the decision-time state and dialogue; its answer is discarded, and its hidden state becomes a decision-oriented feature, making the LLM an encoder rather than a direct few-shot predictor. Training on 13 frontier-LLM agents and testing on 91 held-out scaffolded agents, the full model outperforms direct LLM-as-Predictor prompting and game+text features baselines. Within this tabular model, Observer features contribute beyond the other feature schemes: at $K=16$, they improve response-prediction AUC by about 4 points across both tasks and reduce bargaining offer-prediction error by 14%. These results show that formulating counterpart prediction as a target-adaptive text-tabular task enables effective adaptation, and that hidden LLM representations expose decision-relevant signals that direct prompting does not surface.
MulTaBench: Benchmarking Multimodal Tabular Learning with Text and Image
May 11, 2026Tabular Foundation Models have recently established the state of the art in supervised tabular learning, by leveraging pretraining to learn generalizable representations of numerical and categorical structured data. However, they lack native support for unstructured modalities such as text and image, and rely on frozen, pretrained embeddings to process them. On established Multimodal Tabular Learning benchmarks, we show that tuning the embeddings to the task improves performance. Existing benchmarks, however, often focus on the mere co-occurrence of modalities; this leads to high variance across datasets and masks the benefits of task-specific tuning. To address this gap, we introduce MulTaBench, a benchmark of 40 datasets, split equally between image-tabular and text-tabular tasks. We focus on predictive tasks where the modalities provide complementary predictive signal, and where generic embeddings lose critical information, necessitating Target-Aware Representations that are aligned with the task. Our experimental results demonstrate that the gains from target-aware representation tuning generalize across both text and image modalities, several tabular learners, encoder scales, and embedding dimensions. MulTaBench constitutes the largest image-tabular benchmarking effort to date, spanning high-impact domains such as healthcare and e-commerce. It is designed to enable the research of novel architectures which incorporate joint modeling and target-aware representations, paving the way for the development of novel Multimodal Tabular Foundation Models.
Alignment Makes Language Models Normative, Not Descriptive
Mar 17, 2026Post-training alignment optimizes language models to match human preference signals, but this objective is not equivalent to modeling observed human behavior. We compare 120 base-aligned model pairs on more than 10,000 real human decisions in multi-round strategic games - bargaining, persuasion, negotiation, and repeated matrix games. In these settings, base models outperform their aligned counterparts in predicting human choices by nearly 10:1, robustly across model families, prompt formulations, and game configurations. This pattern reverses, however, in settings where human behavior is more likely to follow normative predictions: aligned models dominate on one-shot textbook games across all 12 types tested and on non-strategic lottery choices - and even within the multi-round games themselves, at round one, before interaction history develops. This boundary-condition pattern suggests that alignment induces a normative bias: it improves prediction when human behavior is relatively well captured by normative solutions, but hurts prediction in multi-round strategic settings, where behavior is shaped by descriptive dynamics such as reciprocity, retaliation, and history-dependent adaptation. These results reveal a fundamental trade-off between optimizing models for human use and using them as proxies for human behavior.
TabAgent: A Framework for Replacing Agentic Generative Components with Tabular-Textual Classifiers
Feb 18, 2026Agentic systems, AI architectures that autonomously execute multi-step workflows to achieve complex goals, are often built using repeated large language model (LLM) calls for closed-set decision tasks such as routing, shortlisting, gating, and verification. While convenient, this design makes deployments slow and expensive due to cumulative latency and token usage. We propose TabAgent, a framework for replacing generative decision components in closed-set selection tasks with a compact textual-tabular classifier trained on execution traces. TabAgent (i) extracts structured schema, state, and dependency features from trajectories (TabSchema), (ii) augments coverage with schema-aligned synthetic supervision (TabSynth), and (iii) scores candidates with a lightweight classifier (TabHead). On the long-horizon AppWorld benchmark, TabAgent maintains task-level success while eliminating shortlist-time LLM calls, reducing latency by approximately 95% and inference cost by 85-91%. Beyond tool shortlisting, TabAgent generalizes to other agentic decision heads, establishing a paradigm for learned discriminative replacements of generative bottlenecks in production agent architectures.
Textual Planning with Explicit Latent Transitions
Feb 04, 2026Planning with LLMs is bottlenecked by token-by-token generation and repeated full forward passes, making multi-step lookahead and rollout-based search expensive in latency and compute. We propose EmbedPlan, which replaces autoregressive next-state generation with a lightweight transition model operating in a frozen language embedding space. EmbedPlan encodes natural language state and action descriptions into vectors, predicts the next-state embedding, and retrieves the next state by nearest-neighbor similarity, enabling fast planning computation without fine-tuning the encoder. We evaluate next-state prediction across nine classical planning domains using six evaluation protocols of increasing difficulty: interpolation, plan-variant, extrapolation, multi-domain, cross-domain, and leave-one-out. Results show near-perfect interpolation performance but a sharp degradation when generalization requires transfer to unseen problems or unseen domains; plan-variant evaluation indicates generalization to alternative plans rather than memorizing seen trajectories. Overall, frozen embeddings support within-domain dynamics learning after observing a domain's transitions, while transfer across domain boundaries remains a bottleneck.
The Poisoned Apple Effect: Strategic Manipulation of Mediated Markets via Technology Expansion of AI Agents
Jan 16, 2026The integration of AI agents into economic markets fundamentally alters the landscape of strategic interaction. We investigate the economic implications of expanding the set of available technologies in three canonical game-theoretic settings: bargaining (resource division), negotiation (asymmetric information trade), and persuasion (strategic information transmission). We find that simply increasing the choice of AI delegates can drastically shift equilibrium payoffs and regulatory outcomes, often creating incentives for regulators to proactively develop and release technologies. Conversely, we identify a strategic phenomenon termed the "Poisoned Apple" effect: an agent may release a new technology, which neither they nor their opponent ultimately uses, solely to manipulate the regulator's choice of market design in their favor. This strategic release improves the releaser's welfare at the expense of their opponent and the regulator's fairness objectives. Our findings demonstrate that static regulatory frameworks are vulnerable to manipulation via technology expansion, necessitating dynamic market designs that adapt to the evolving landscape of AI capabilities.
Donors and Recipients: On Asymmetric Transfer Across Tasks and Languages with Parameter-Efficient Fine-Tuning
Nov 17, 2025

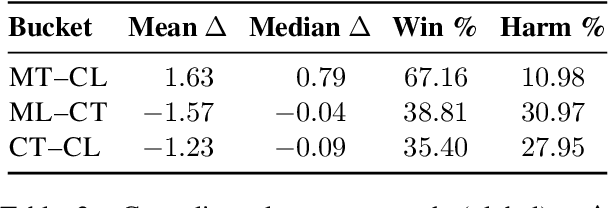

Large language models (LLMs) perform strongly across tasks and languages, yet how improvements in one task or language affect other tasks and languages and their combinations remains poorly understood. We conduct a controlled PEFT/LoRA study across multiple open-weight LLM families and sizes, treating task and language as transfer axes while conditioning on model family and size; we fine-tune each model on a single task-language source and measure transfer as the percentage-point change versus its baseline score when evaluated on all other task-language target pairs. We decompose transfer into (i) Matched-Task (Cross-Language), (ii) Matched-Language (Cross-Task), and (iii) Cross-Task (Cross-Language) regimes. We uncover two consistent general patterns. First, a pronounced on-task vs. off-task asymmetry: Matched-Task (Cross-Language) transfer is reliably positive, whereas off-task transfer often incurs collateral degradation. Second, a stable donor-recipient structure across languages and tasks (hub donors vs. brittle recipients). We outline implications for risk-aware fine-tuning and model specialisation.
TabSTAR: A Foundation Tabular Model With Semantically Target-Aware Representations
May 23, 2025While deep learning has achieved remarkable success across many domains, it has historically underperformed on tabular learning tasks, which remain dominated by gradient boosting decision trees (GBDTs). However, recent advancements are paving the way for Tabular Foundation Models, which can leverage real-world knowledge and generalize across diverse datasets, particularly when the data contains free-text. Although incorporating language model capabilities into tabular tasks has been explored, most existing methods utilize static, target-agnostic textual representations, limiting their effectiveness. We introduce TabSTAR: a Foundation Tabular Model with Semantically Target-Aware Representations. TabSTAR is designed to enable transfer learning on tabular data with textual features, with an architecture free of dataset-specific parameters. It unfreezes a pretrained text encoder and takes as input target tokens, which provide the model with the context needed to learn task-specific embeddings. TabSTAR achieves state-of-the-art performance for both medium- and large-sized datasets across known benchmarks of classification tasks with text features, and its pretraining phase exhibits scaling laws in the number of datasets, offering a pathway for further performance improvements.
Fairness under Competition
May 22, 2025


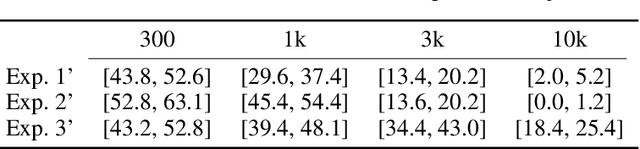
Algorithmic fairness has emerged as a central issue in ML, and it has become standard practice to adjust ML algorithms so that they will satisfy fairness requirements such as Equal Opportunity. In this paper we consider the effects of adopting such fair classifiers on the overall level of ecosystem fairness. Specifically, we introduce the study of fairness with competing firms, and demonstrate the failure of fair classifiers in yielding fair ecosystems. Our results quantify the loss of fairness in systems, under a variety of conditions, based on classifiers' correlation and the level of their data overlap. We show that even if competing classifiers are individually fair, the ecosystem's outcome may be unfair; and that adjusting biased algorithms to improve their individual fairness may lead to an overall decline in ecosystem fairness. In addition to these theoretical results, we also provide supporting experimental evidence. Together, our model and results provide a novel and essential call for action.