 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAO-Instruct: Free-form Audio Editing using Natural Language Instructions
Oct 26, 2025Generative models have made significant progress in synthesizing high-fidelity audio from short textual descriptions. However, editing existing audio using natural language has remained largely underexplored. Current approaches either require the complete description of the edited audio or are constrained to predefined edit instructions that lack flexibility. In this work, we introduce SAO-Instruct, a model based on Stable Audio Open capable of editing audio clips using any free-form natural language instruction. To train our model, we create a dataset of audio editing triplets (input audio, edit instruction, output audio) using Prompt-to-Prompt, DDPM inversion, and a manual editing pipeline. Although partially trained on synthetic data, our model generalizes well to real in-the-wild audio clips and unseen edit instructions. We demonstrate that SAO-Instruct achieves competitive performance on objective metrics and outperforms other audio editing approaches in a subjective listening study. To encourage future research, we release our code and model weights.
Inductive Transfer Learning for Graph-Based Recommenders
Oct 26, 2025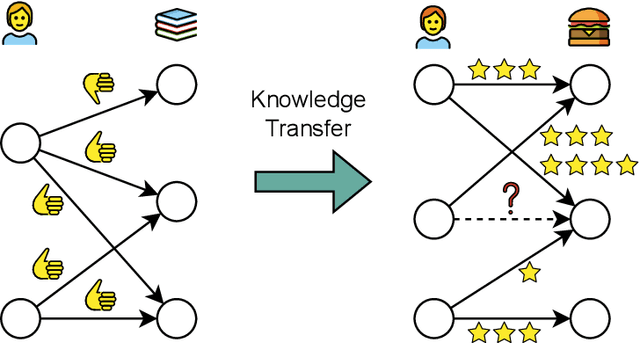
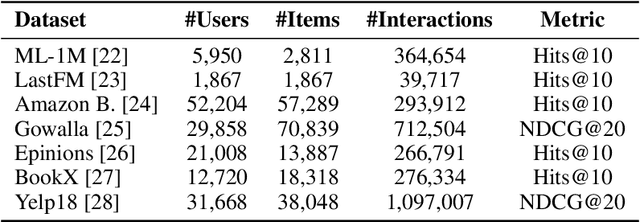
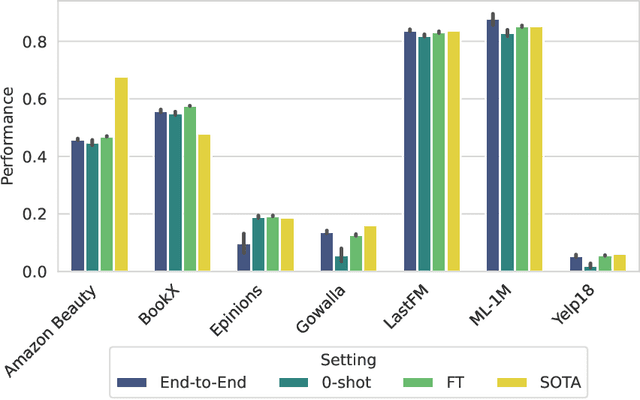
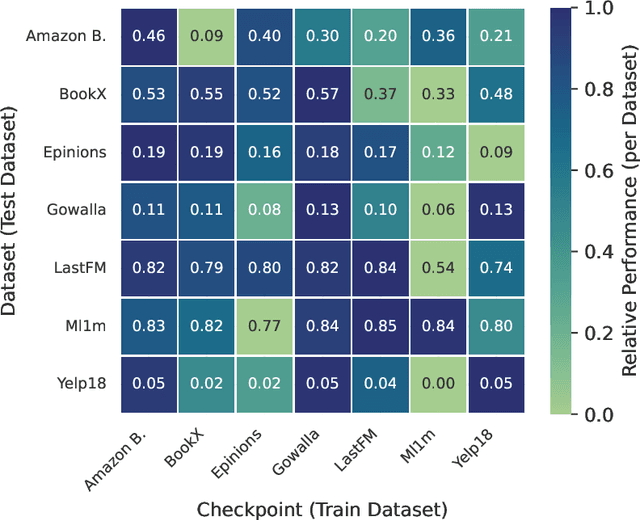
Graph-based recommender systems are commonly trained in transductive settings, which limits their applicability to new users, items, or datasets. We propose NBF-Rec, a graph-based recommendation model that supports inductive transfer learning across datasets with disjoint user and item sets. Unlike conventional embedding-based methods that require retraining for each domain, NBF-Rec computes node embeddings dynamically at inference time. We evaluate the method on seven real-world datasets spanning movies, music, e-commerce, and location check-ins. NBF-Rec achieves competitive performance in zero-shot settings, where no target domain data is used for training, and demonstrates further improvements through lightweight fine-tuning. These results show that inductive transfer is feasible in graph-based recommendation and that interaction-level message passing supports generalization across datasets without requiring aligned users or items.
Bias beyond Borders: Global Inequalities in AI-Generated Music
Oct 02, 2025While recent years have seen remarkable progress in music generation models, research on their biases across countries, languages, cultures, and musical genres remains underexplored. This gap is compounded by the lack of datasets and benchmarks that capture the global diversity of music. To address these challenges, we introduce GlobalDISCO, a large-scale dataset consisting of 73k music tracks generated by state-of-the-art commercial generative music models, along with paired links to 93k reference tracks in LAION-DISCO-12M. The dataset spans 147 languages and includes musical style prompts extracted from MusicBrainz and Wikipedia. The dataset is globally balanced, representing musical styles from artists across 79 countries and five continents. Our evaluation reveals large disparities in music quality and alignment with reference music between high-resource and low-resource regions. Furthermore, we find marked differences in model performance between mainstream and geographically niche genres, including cases where models generate music for regional genres that more closely align with the distribution of mainstream styles.
Multi-bit Audio Watermarking
Oct 02, 2025



We present Timbru, a post-hoc audio watermarking model that achieves state-of-the-art robustness and imperceptibility trade-offs without training an embedder-detector model. Given any 44.1 kHz stereo music snippet, our method performs per-audio gradient optimization to add imperceptible perturbations in the latent space of a pretrained audio VAE, guided by a combined message and perceptual loss. The watermark can then be extracted using a pretrained CLAP model. We evaluate 16-bit watermarking on MUSDB18-HQ against AudioSeal, WavMark, and SilentCipher across common filtering, noise, compression, resampling, cropping, and regeneration attacks. Our approach attains the best average bit error rates, while preserving perceptual quality, demonstrating an efficient, dataset-free path to imperceptible audio watermarking.
High-Fidelity Speech Enhancement via Discrete Audio Tokens
Oct 02, 2025Recent autoregressive transformer-based speech enhancement (SE) methods have shown promising results by leveraging advanced semantic understanding and contextual modeling of speech. However, these approaches often rely on complex multi-stage pipelines and low sampling rate codecs, limiting them to narrow and task-specific speech enhancement. In this work, we introduce DAC-SE1, a simplified language model-based SE framework leveraging discrete high-resolution audio representations; DAC-SE1 preserves fine-grained acoustic details while maintaining semantic coherence. Our experiments show that DAC-SE1 surpasses state-of-the-art autoregressive SE methods on both objective perceptual metrics and in a MUSHRA human evaluation. We release our codebase and model checkpoints to support further research in scalable, unified, and high-quality speech enhancement.
EuroSpeech: A Multilingual Speech Corpus
Oct 01, 2025Recent progress in speech processing has highlighted that high-quality performance across languages requires substantial training data for each individual language. While existing multilingual datasets cover many languages, they often contain insufficient data for most languages. Thus, trained models perform poorly on the majority of the supported languages. Our work addresses this challenge by introducing a scalable pipeline for constructing speech datasets from parliamentary recordings. The proposed pipeline includes robust components for media retrieval and a two-stage alignment algorithm designed to handle non-verbatim transcripts and long-form audio. Applying this pipeline to recordings from 22 European parliaments, we extract over 61k hours of aligned speech segments, achieving substantial per-language coverage with 19 languages exceeding 1k hours and 22 languages exceeding 500 hours of high-quality speech data. We obtain an average 41.8\% reduction in word error rates over baselines when finetuning an existing ASR model on our dataset, demonstrating the usefulness of our approach.
Recurrent Deep Differentiable Logic Gate Networks
Aug 08, 2025While differentiable logic gates have shown promise in feedforward networks, their application to sequential modeling remains unexplored. This paper presents the first implementation of Recurrent Deep Differentiable Logic Gate Networks (RDDLGN), combining Boolean operations with recurrent architectures for sequence-to-sequence learning. Evaluated on WMT'14 English-German translation, RDDLGN achieves 5.00 BLEU and 30.9\% accuracy during training, approaching GRU performance (5.41 BLEU) and graceful degradation (4.39 BLEU) during inference. This work establishes recurrent logic-based neural computation as viable, opening research directions for FPGA acceleration in sequential modeling and other recursive network architectures.
Keep It Real: Challenges in Attacking Compression-Based Adversarial Purification
Aug 07, 2025Previous work has suggested that preprocessing images through lossy compression can defend against adversarial perturbations, but comprehensive attack evaluations have been lacking. In this paper, we construct strong white-box and adaptive attacks against various compression models and identify a critical challenge for attackers: high realism in reconstructed images significantly increases attack difficulty. Through rigorous evaluation across multiple attack scenarios, we demonstrate that compression models capable of producing realistic, high-fidelity reconstructions are substantially more resistant to our attacks. In contrast, low-realism compression models can be broken. Our analysis reveals that this is not due to gradient masking. Rather, realistic reconstructions maintaining distributional alignment with natural images seem to offer inherent robustness. This work highlights a significant obstacle for future adversarial attacks and suggests that developing more effective techniques to overcome realism represents an essential challenge for comprehensive security evaluation.
Parametric Neural Amp Modeling with Active Learning
Jul 02, 2025We introduce PANAMA, an active learning framework for the training of end-to-end parametric guitar amp models using a WaveNet-like architecture. With \model, one can create a virtual amp by recording samples that are determined by an active learning strategy to use a minimum amount of datapoints (i.e., amp knob settings). We show that gradient-based optimization algorithms can be used to determine the optimal datapoints to sample, and that the approach helps under a constrained number of samples.
Benchmarking Music Generation Models and Metrics via Human Preference Studies
Jun 23, 2025Recent advancements have brought generated music closer to human-created compositions, yet evaluating these models remains challenging. While human preference is the gold standard for assessing quality, translating these subjective judgments into objective metrics, particularly for text-audio alignment and music quality, has proven difficult. In this work, we generate 6k songs using 12 state-of-the-art models and conduct a survey of 15k pairwise audio comparisons with 2.5k human participants to evaluate the correlation between human preferences and widely used metrics. To the best of our knowledge, this work is the first to rank current state-of-the-art music generation models and metrics based on human preference. To further the field of subjective metric evaluation, we provide open access to our dataset of generated music and human evaluations.
* Accepted at ICASSP 2025