 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructural Guidance for Transformer Language Models
Jul 30, 2021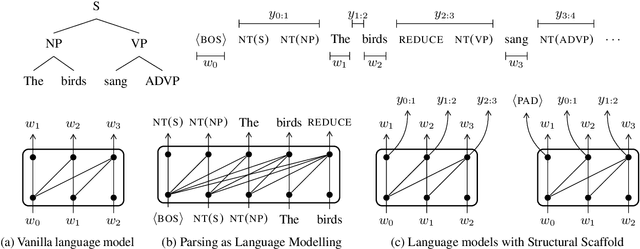
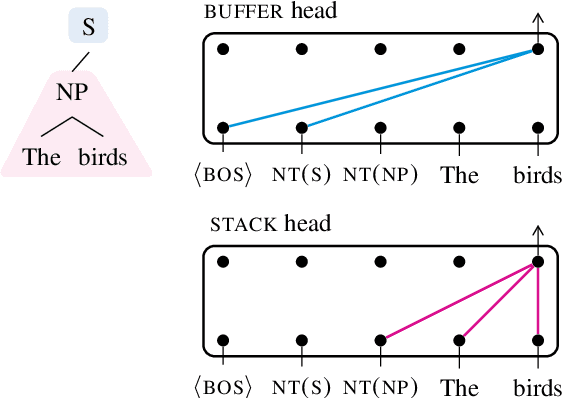
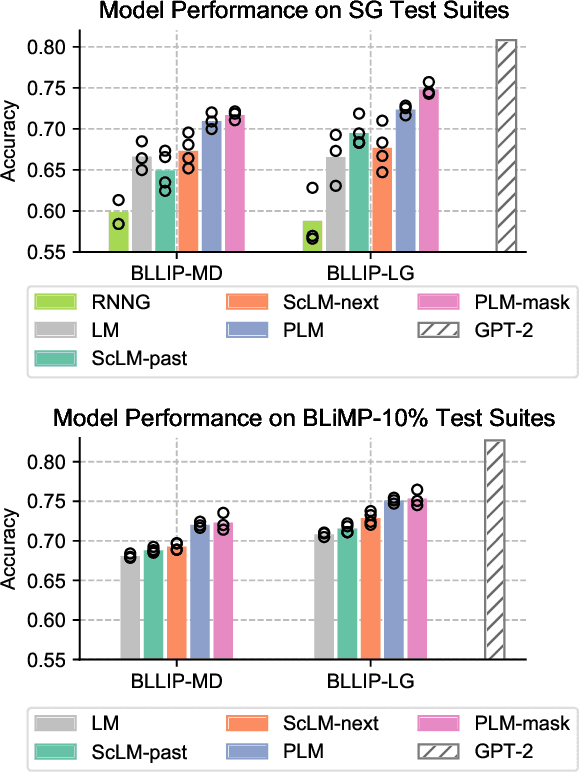
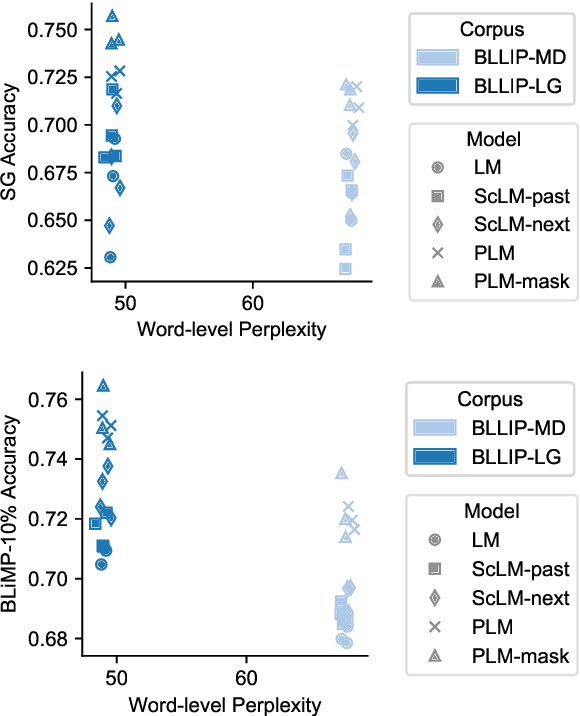
Transformer-based language models pre-trained on large amounts of text data have proven remarkably successful in learning generic transferable linguistic representations. Here we study whether structural guidance leads to more human-like systematic linguistic generalization in Transformer language models without resorting to pre-training on very large amounts of data. We explore two general ideas. The "Generative Parsing" idea jointly models the incremental parse and word sequence as part of the same sequence modeling task. The "Structural Scaffold" idea guides the language model's representation via additional structure loss that separately predicts the incremental constituency parse. We train the proposed models along with a vanilla Transformer language model baseline on a 14 million-token and a 46 million-token subset of the BLLIP dataset, and evaluate models' syntactic generalization performances on SG Test Suites and sized BLiMP. Experiment results across two benchmarks suggest converging evidence that generative structural supervisions can induce more robust and humanlike linguistic generalization in Transformer language models without the need for data intensive pre-training.
What if This Modified That? Syntactic Interventions via Counterfactual Embeddings
May 28, 2021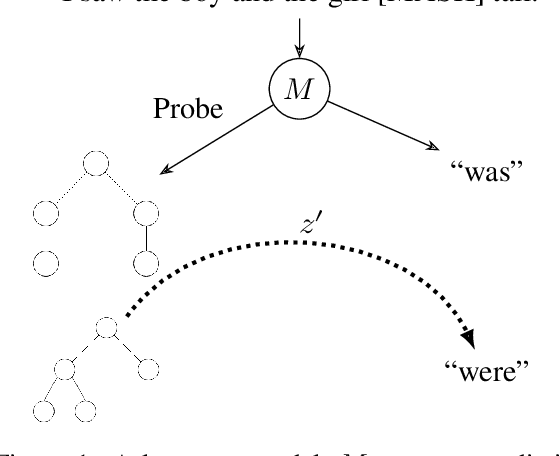

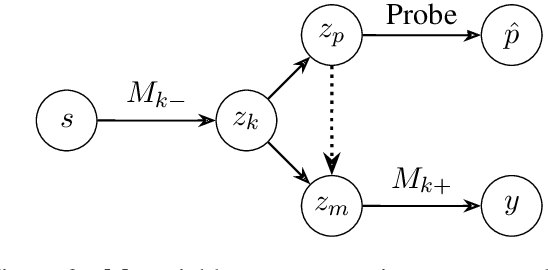
Neural language models exhibit impressive performance on a variety of tasks, but their internal reasoning may be difficult to understand. Prior art aims to uncover meaningful properties within model representations via probes, but it is unclear how faithfully such probes portray information that the models actually use. To overcome such limitations, we propose a technique, inspired by causal analysis, for generating counterfactual embeddings within models. In experiments testing our technique, we produce evidence that suggests some BERT-based models use a tree-distance-like representation of syntax in downstream prediction tasks.
Learning Evolved Combinatorial Symbols with a Neuro-symbolic Generative Model
Apr 16, 2021
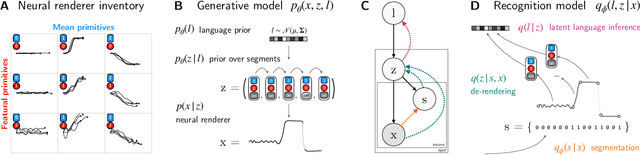
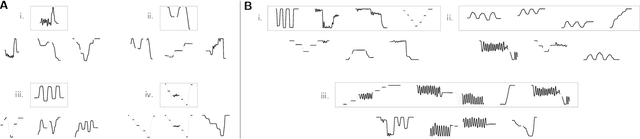
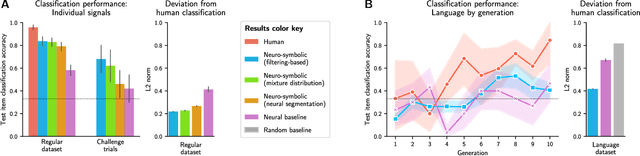
Humans have the ability to rapidly understand rich combinatorial concepts from limited data. Here we investigate this ability in the context of auditory signals, which have been evolved in a cultural transmission experiment to study the emergence of combinatorial structure in language. We propose a neuro-symbolic generative model which combines the strengths of previous approaches to concept learning. Our model performs fast inference drawing on neural network methods, while still retaining the interpretability and generalization from limited data seen in structured generative approaches. This model outperforms a purely neural network-based approach on classification as evaluated against both ground truth and human experimental classification preferences, and produces superior reproductions of observed signals as well. Our results demonstrate the power of flexible combined neural-symbolic architectures for human-like generalization in raw perceptual domains and offers a step towards developing precise computational models of inductive biases in language evolution.
Investigating Novel Verb Learning in BERT: Selectional Preference Classes and Alternation-Based Syntactic Generalization
Nov 04, 2020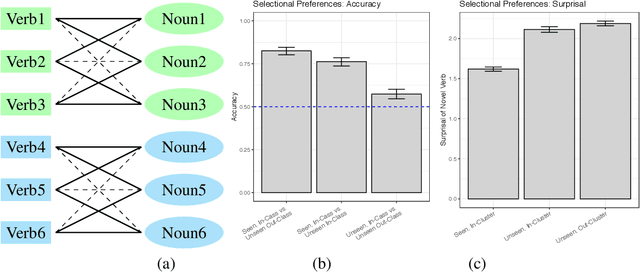
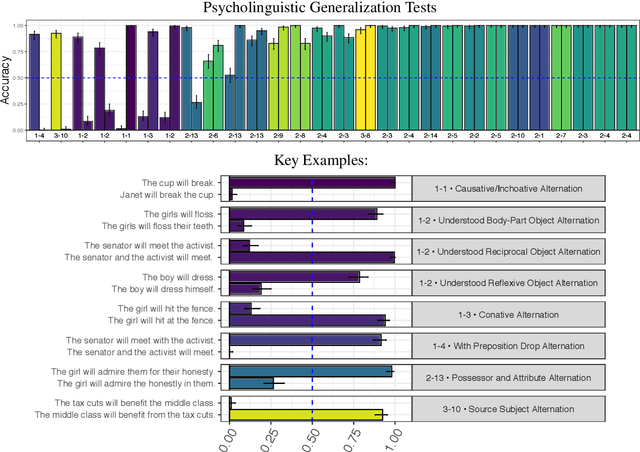
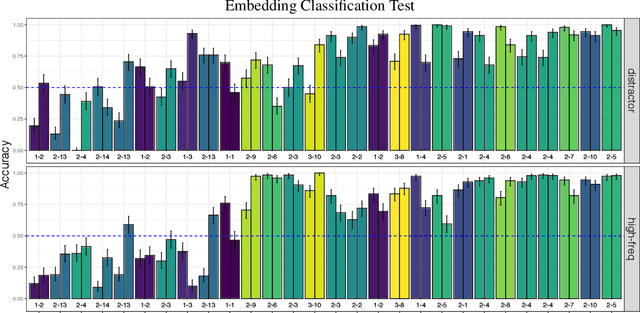
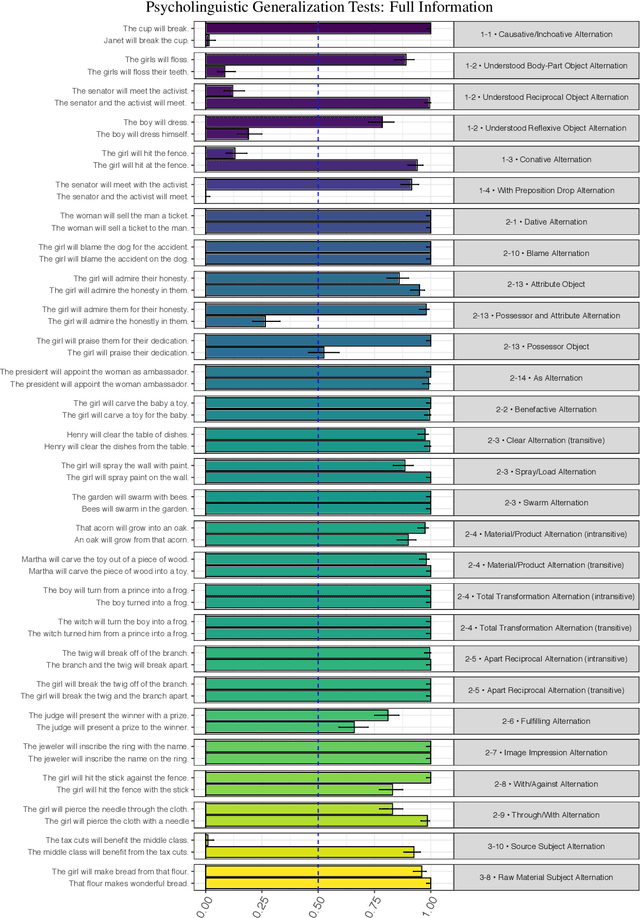
Previous studies investigating the syntactic abilities of deep learning models have not targeted the relationship between the strength of the grammatical generalization and the amount of evidence to which the model is exposed during training. We address this issue by deploying a novel word-learning paradigm to test BERT's few-shot learning capabilities for two aspects of English verbs: alternations and classes of selectional preferences. For the former, we fine-tune BERT on a single frame in a verbal-alternation pair and ask whether the model expects the novel verb to occur in its sister frame. For the latter, we fine-tune BERT on an incomplete selectional network of verbal objects and ask whether it expects unattested but plausible verb/object pairs. We find that BERT makes robust grammatical generalizations after just one or two instances of a novel word in fine-tuning. For the verbal alternation tests, we find that the model displays behavior that is consistent with a transitivity bias: verbs seen few times are expected to take direct objects, but verbs seen with direct objects are not expected to occur intransitively.
Bridging Information-Seeking Human Gaze and Machine Reading Comprehension
Oct 15, 2020
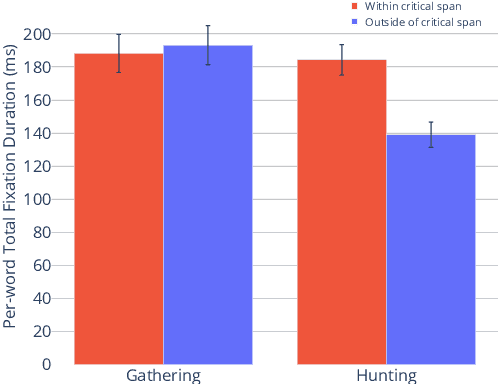
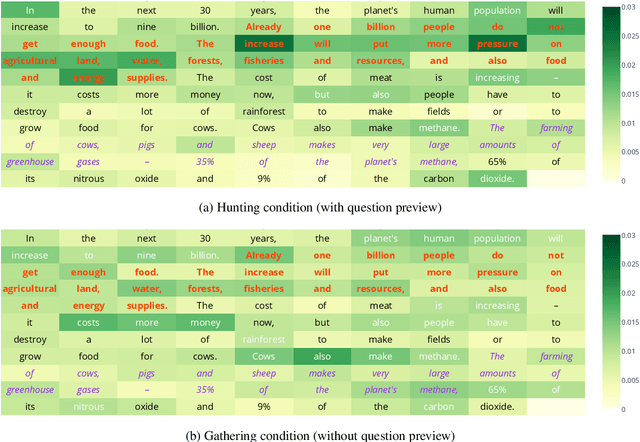
In this work, we analyze how human gaze during reading comprehension is conditioned on the given reading comprehension question, and whether this signal can be beneficial for machine reading comprehension. To this end, we collect a new eye-tracking dataset with a large number of participants engaging in a multiple choice reading comprehension task. Our analysis of this data reveals increased fixation times over parts of the text that are most relevant for answering the question. Motivated by this finding, we propose making automated reading comprehension more human-like by mimicking human information-seeking reading behavior during reading comprehension. We demonstrate that this approach leads to performance gains on multiple choice question answering in English for a state-of-the-art reading comprehension model.
Structural Supervision Improves Few-Shot Learning and Syntactic Generalization in Neural Language Models
Oct 12, 2020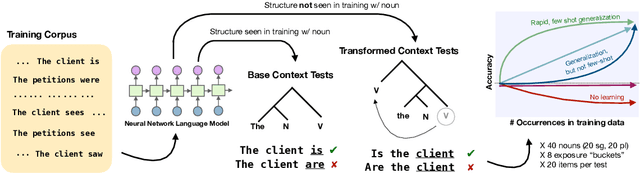
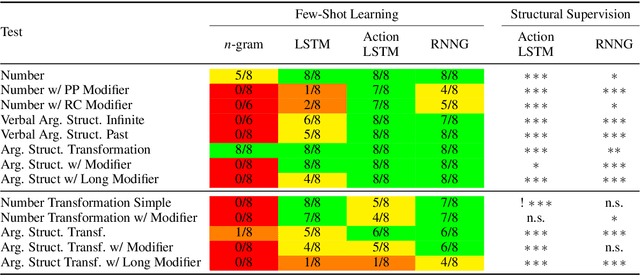
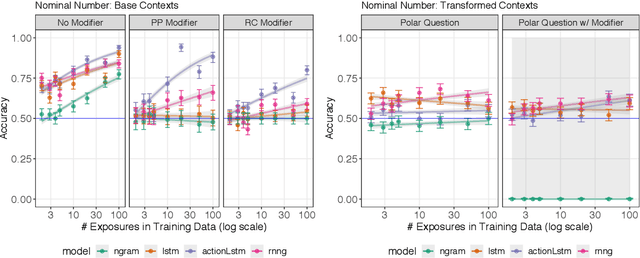
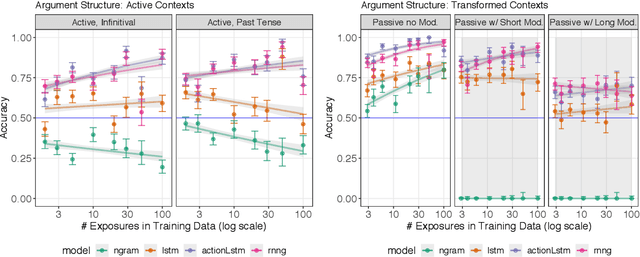
Humans can learn structural properties about a word from minimal experience, and deploy their learned syntactic representations uniformly in different grammatical contexts. We assess the ability of modern neural language models to reproduce this behavior in English and evaluate the effect of structural supervision on learning outcomes. First, we assess few-shot learning capabilities by developing controlled experiments that probe models' syntactic nominal number and verbal argument structure generalizations for tokens seen as few as two times during training. Second, we assess invariance properties of learned representation: the ability of a model to transfer syntactic generalizations from a base context (e.g., a simple declarative active-voice sentence) to a transformed context (e.g., an interrogative sentence). We test four models trained on the same dataset: an n-gram baseline, an LSTM, and two LSTM-variants trained with explicit structural supervision (Dyer et al.,2016; Charniak et al., 2016). We find that in most cases, the neural models are able to induce the proper syntactic generalizations after minimal exposure, often from just two examples during training, and that the two structurally supervised models generalize more accurately than the LSTM model. All neural models are able to leverage information learned in base contexts to drive expectations in transformed contexts, indicating that they have learned some invariance properties of syntax.
On the Predictive Power of Neural Language Models for Human Real-Time Comprehension Behavior
Jun 02, 2020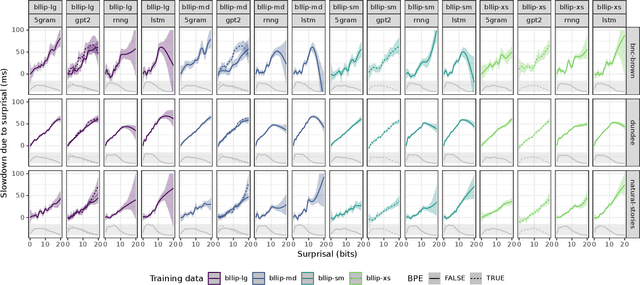
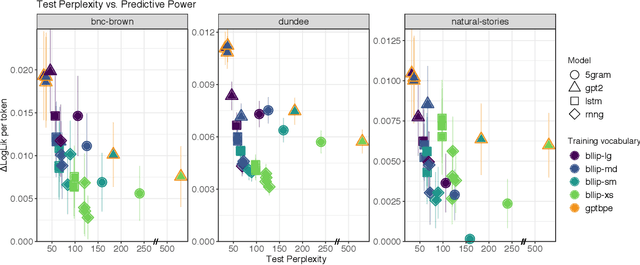
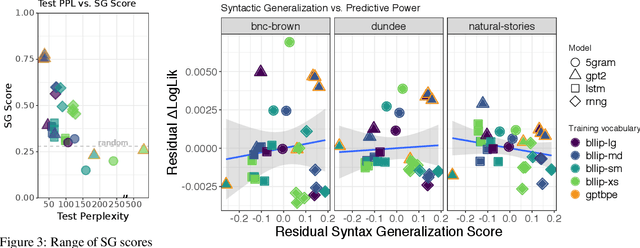
Human reading behavior is tuned to the statistics of natural language: the time it takes human subjects to read a word can be predicted from estimates of the word's probability in context. However, it remains an open question what computational architecture best characterizes the expectations deployed in real time by humans that determine the behavioral signatures of reading. Here we test over two dozen models, independently manipulating computational architecture and training dataset size, on how well their next-word expectations predict human reading time behavior on naturalistic text corpora. We find that across model architectures and training dataset sizes the relationship between word log-probability and reading time is (near-)linear. We next evaluate how features of these models determine their psychometric predictive power, or ability to predict human reading behavior. In general, the better a model's next-word expectations, the better its psychometric predictive power. However, we find nontrivial differences across model architectures. For any given perplexity, deep Transformer models and n-gram models generally show superior psychometric predictive power over LSTM or structurally supervised neural models, especially for eye movement data. Finally, we compare models' psychometric predictive power to the depth of their syntactic knowledge, as measured by a battery of syntactic generalization tests developed using methods from controlled psycholinguistic experiments. Once perplexity is controlled for, we find no significant relationship between syntactic knowledge and predictive power. These results suggest that different approaches may be required to best model human real-time language comprehension behavior in naturalistic reading versus behavior for controlled linguistic materials designed for targeted probing of syntactic knowledge.
STARC: Structured Annotations for Reading Comprehension
Apr 30, 2020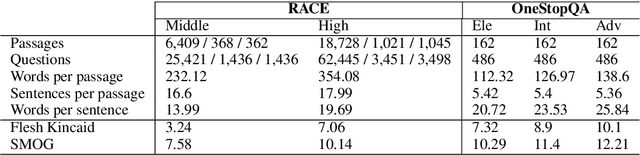

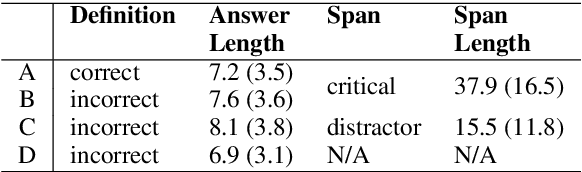

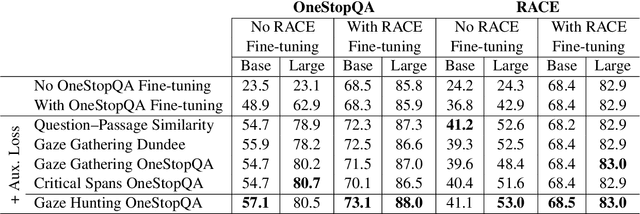
We present STARC (Structured Annotations for Reading Comprehension), a new annotation framework for assessing reading comprehension with multiple choice questions. Our framework introduces a principled structure for the answer choices and ties them to textual span annotations. The framework is implemented in OneStopQA, a new high-quality dataset for evaluation and analysis of reading comprehension in English. We use this dataset to demonstrate that STARC can be leveraged for a key new application for the development of SAT-like reading comprehension materials: automatic annotation quality probing via span ablation experiments. We further show that it enables in-depth analyses and comparisons between machine and human reading comprehension behavior, including error distributions and guessing ability. Our experiments also reveal that the standard multiple choice dataset in NLP, RACE, is limited in its ability to measure reading comprehension. 47% of its questions can be guessed by machines without accessing the passage, and 18% are unanimously judged by humans as not having a unique correct answer. OneStopQA provides an alternative test set for reading comprehension which alleviates these shortcomings and has a substantially higher human ceiling performance.
Linking artificial and human neural representations of language
Oct 02, 2019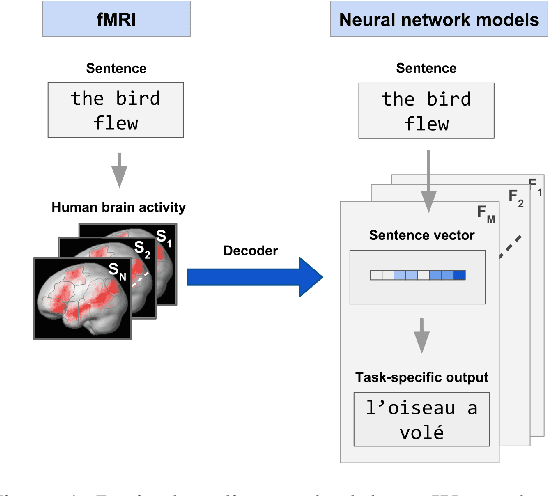

What information from an act of sentence understanding is robustly represented in the human brain? We investigate this question by comparing sentence encoding models on a brain decoding task, where the sentence that an experimental participant has seen must be predicted from the fMRI signal evoked by the sentence. We take a pre-trained BERT architecture as a baseline sentence encoding model and fine-tune it on a variety of natural language understanding (NLU) tasks, asking which lead to improvements in brain-decoding performance. We find that none of the sentence encoding tasks tested yield significant increases in brain decoding performance. Through further task ablations and representational analyses, we find that tasks which produce syntax-light representations yield significant improvements in brain decoding performance. Our results constrain the space of NLU models that could best account for human neural representations of language, but also suggest limits on the possibility of decoding fine-grained syntactic information from fMRI human neuroimaging.
Representation of Constituents in Neural Language Models: Coordination Phrase as a Case Study
Sep 10, 2019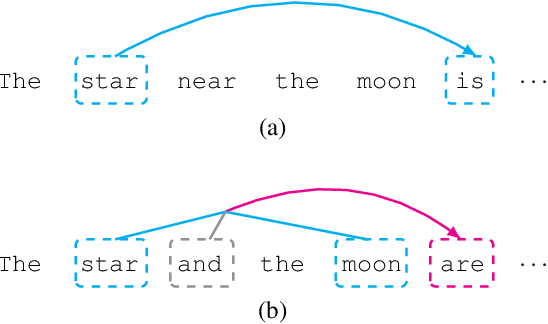
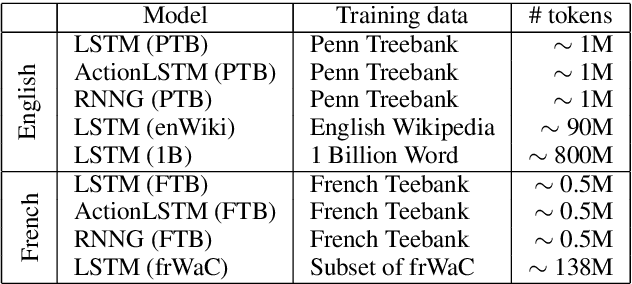
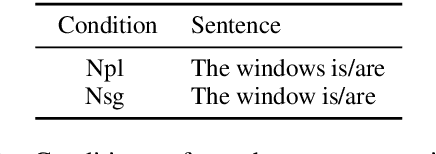

Neural language models have achieved state-of-the-art performances on many NLP tasks, and recently have been shown to learn a number of hierarchically-sensitive syntactic dependencies between individual words. However, equally important for language processing is the ability to combine words into phrasal constituents, and use constituent-level features to drive downstream expectations. Here we investigate neural models' ability to represent constituent-level features, using coordinated noun phrases as a case study. We assess whether different neural language models trained on English and French represent phrase-level number and gender features, and use those features to drive downstream expectations. Our results suggest that models use a linear combination of NP constituent number to drive CoordNP/verb number agreement. This behavior is highly regular and even sensitive to local syntactic context, however it differs crucially from observed human behavior. Models have less success with gender agreement. Models trained on large corpora perform best, and there is no obvious advantage for models trained using explicit syntactic supervision.