 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe k-tied Normal Distribution: A Compact Parameterization of Gaussian Mean Field Posteriors in Bayesian Neural Networks
Feb 07, 2020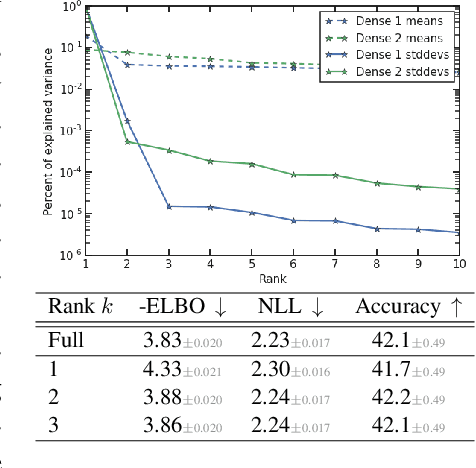
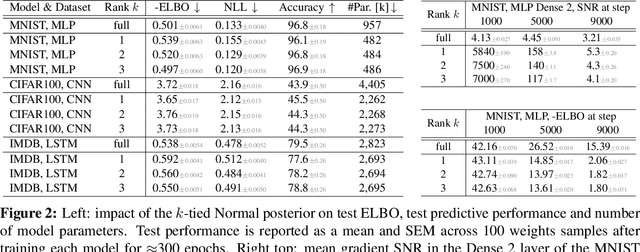
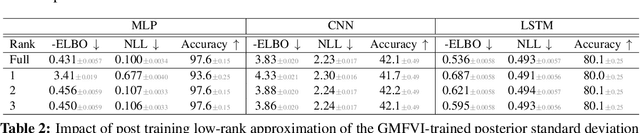
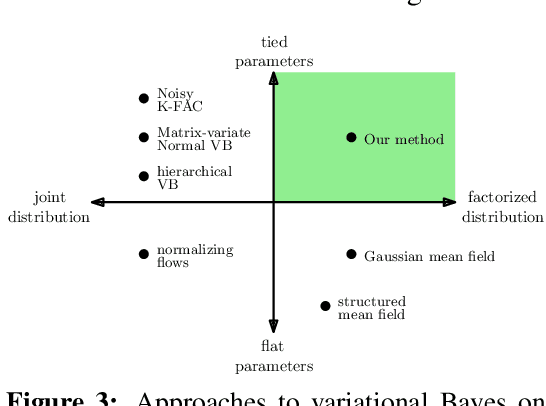
Variational Bayesian Inference is a popular methodology for approximating posterior distributions over Bayesian neural network weights. Recent work developing this class of methods has explored ever richer parameterizations of the approximate posterior in the hope of improving performance. In contrast, here we share a curious experimental finding that suggests instead restricting the variational distribution to a more compact parameterization. For a variety of deep Bayesian neural networks trained using Gaussian mean-field variational inference, we find that the posterior standard deviations consistently exhibit strong low-rank structure after convergence. This means that by decomposing these variational parameters into a low-rank factorization, we can make our variational approximation more compact without decreasing the models' performance. Furthermore, we find that such factorized parameterizations improve the signal-to-noise ratio of stochastic gradient estimates of the variational lower bound, resulting in faster convergence.
How Good is the Bayes Posterior in Deep Neural Networks Really?
Feb 06, 2020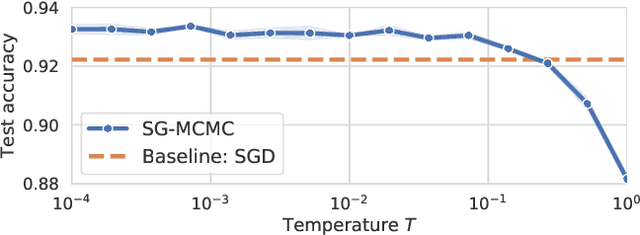
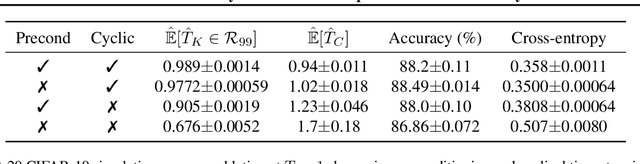
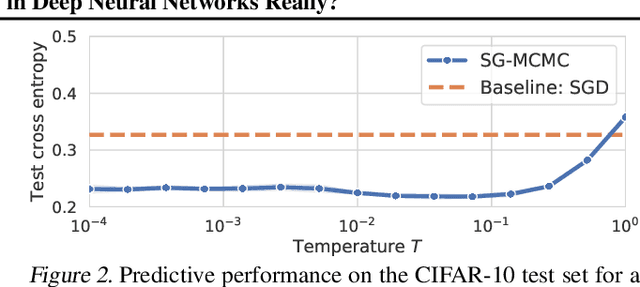

During the past five years the Bayesian deep learning community has developed increasingly accurate and efficient approximate inference procedures that allow for Bayesian inference in deep neural networks. However, despite this algorithmic progress and the promise of improved uncertainty quantification and sample efficiency there are---as of early 2020---no publicized deployments of Bayesian neural networks in industrial practice. In this work we cast doubt on the current understanding of Bayes posteriors in popular deep neural networks: we demonstrate through careful MCMC sampling that the posterior predictive induced by the Bayes posterior yields systematically worse predictions compared to simpler methods including point estimates obtained from SGD. Furthermore, we demonstrate that predictive performance is improved significantly through the use of a "cold posterior" that overcounts evidence. Such cold posteriors sharply deviate from the Bayesian paradigm but are commonly used as heuristic in Bayesian deep learning papers. We put forward several hypotheses that could explain cold posteriors and evaluate the hypotheses through experiments. Our work questions the goal of accurate posterior approximations in Bayesian deep learning: If the true Bayes posterior is poor, what is the use of more accurate approximations? Instead, we argue that it is timely to focus on understanding the origin of the improved performance of cold posteriors.
Hydra: Preserving Ensemble Diversity for Model Distillation
Jan 14, 2020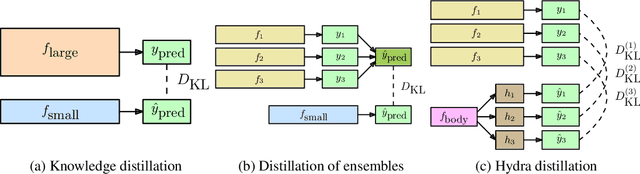
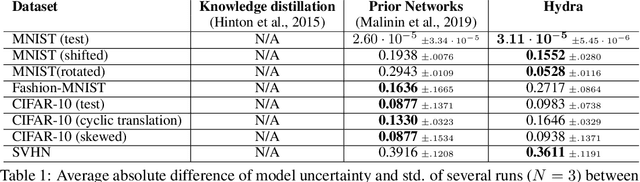
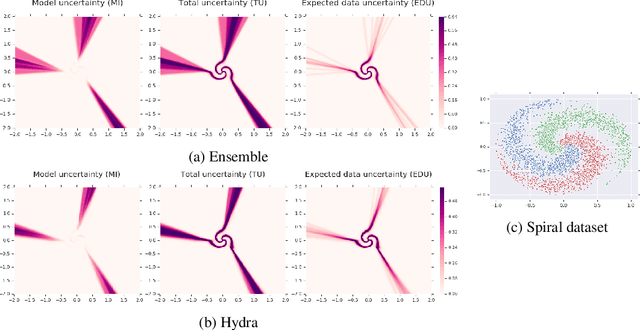
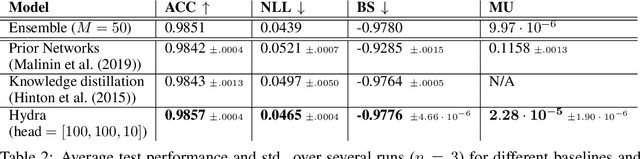
Ensembles of models have been empirically shown to improve predictive performance and to yield robust measures of uncertainty. However, they are expensive in computation and memory. Therefore, recent research has focused on distilling ensembles into a single compact model, reducing the computational and memory burden of the ensemble while trying to preserve its predictive behavior. Most existing distillation formulations summarize the ensemble by capturing its average predictions. As a result, the diversity of the ensemble predictions, stemming from each individual member, is lost. Thus, the distilled model cannot provide a measure of uncertainty comparable to that of the original ensemble. To retain more faithfully the diversity of the ensemble, we propose a distillation method based on a single multi-headed neural network, which we refer to as Hydra. The shared body network learns a joint feature representation that enables each head to capture the predictive behavior of each ensemble member. We demonstrate that with a slight increase in parameter count, Hydra improves distillation performance on classification and regression settings while capturing the uncertainty behaviour of the original ensemble over both in-domain and out-of-distribution tasks.
Constrained Bayesian Optimization with Max-Value Entropy Search
Oct 15, 2019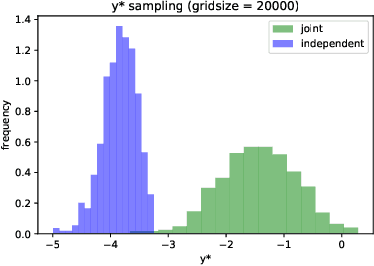
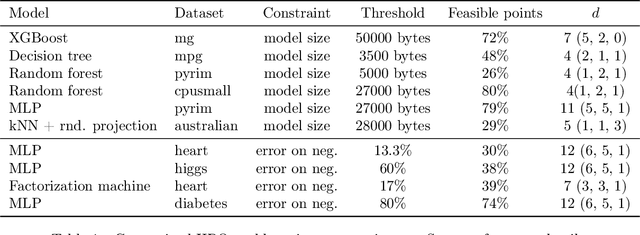
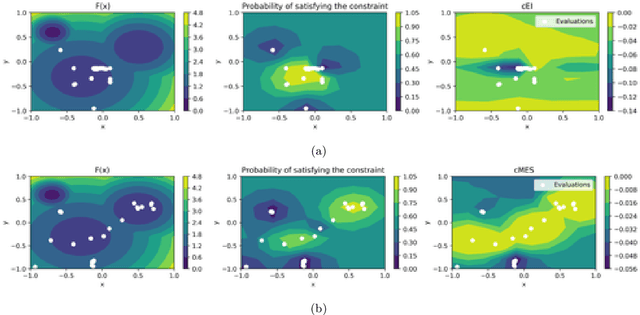
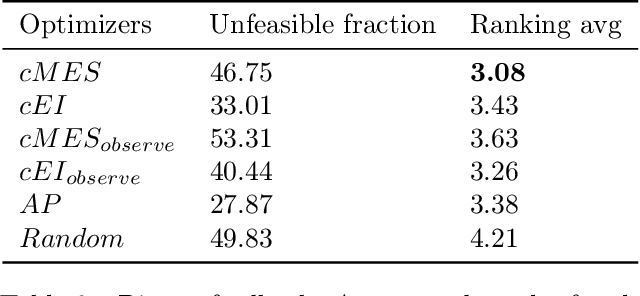
Bayesian optimization (BO) is a model-based approach to sequentially optimize expensive black-box functions, such as the validation error of a deep neural network with respect to its hyperparameters. In many real-world scenarios, the optimization is further subject to a priori unknown constraints. For example, training a deep network configuration may fail with an out-of-memory error when the model is too large. In this work, we focus on a general formulation of Gaussian process-based BO with continuous or binary constraints. We propose constrained Max-value Entropy Search (cMES), a novel information theoretic-based acquisition function implementing this formulation. We also revisit the validity of the factorized approximation adopted for rapid computation of the MES acquisition function, showing empirically that this leads to inaccurate results. On an extensive set of real-world constrained hyperparameter optimization problems we show that cMES compares favourably to prior work, while being simpler to implement and faster than other constrained extensions of Entropy Search.
Learning search spaces for Bayesian optimization: Another view of hyperparameter transfer learning
Sep 27, 2019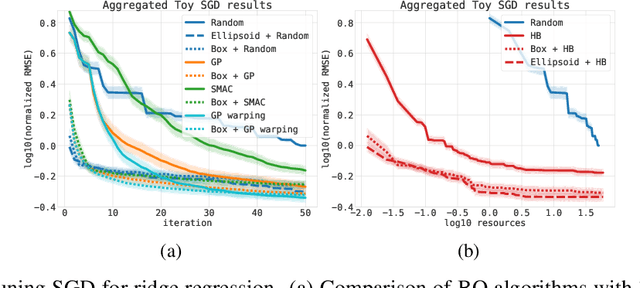
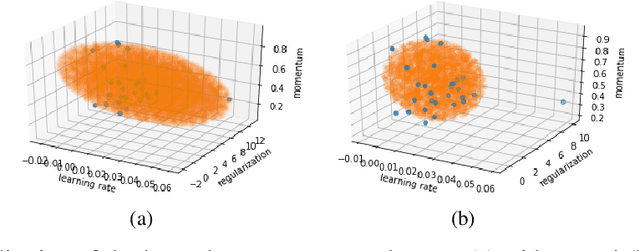
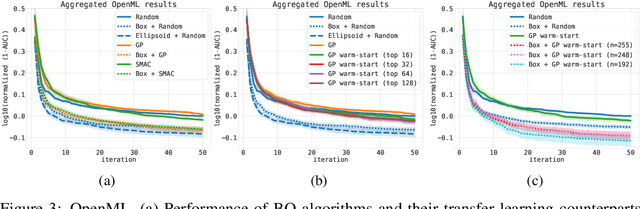
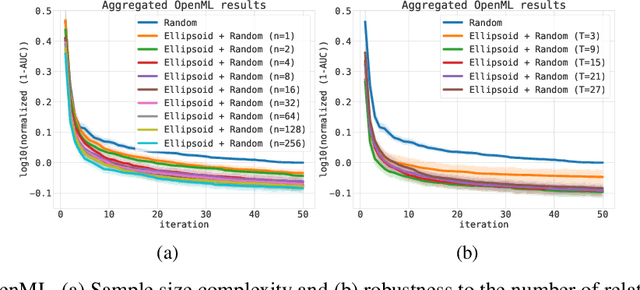
Bayesian optimization (BO) is a successful methodology to optimize black-box functions that are expensive to evaluate. While traditional methods optimize each black-box function in isolation, there has been recent interest in speeding up BO by transferring knowledge across multiple related black-box functions. In this work, we introduce a method to automatically design the BO search space by relying on evaluations of previous black-box functions. We depart from the common practice of defining a set of arbitrary search ranges a priori by considering search space geometries that are learned from historical data. This simple, yet effective strategy can be used to endow many existing BO methods with transfer learning properties. Despite its simplicity, we show that our approach considerably boosts BO by reducing the size of the search space, thus accelerating the optimization of a variety of black-box optimization problems. In particular, the proposed approach combined with random search results in a parameter-free, easy-to-implement, robust hyperparameter optimization strategy. We hope it will constitute a natural baseline for further research attempting to warm-start BO.
Multiple Adaptive Bayesian Linear Regression for Scalable Bayesian Optimization with Warm Start
Dec 08, 2017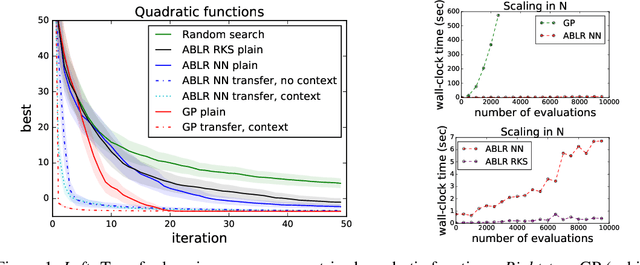
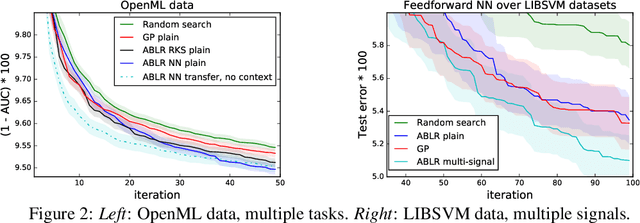
Bayesian optimization (BO) is a model-based approach for gradient-free black-box function optimization. Typically, BO is powered by a Gaussian process (GP), whose algorithmic complexity is cubic in the number of evaluations. Hence, GP-based BO cannot leverage large amounts of past or related function evaluations, for example, to warm start the BO procedure. We develop a multiple adaptive Bayesian linear regression model as a scalable alternative whose complexity is linear in the number of observations. The multiple Bayesian linear regression models are coupled through a shared feedforward neural network, which learns a joint representation and transfers knowledge across machine learning problems.
Online optimization and regret guarantees for non-additive long-term constraints
Jun 08, 2016
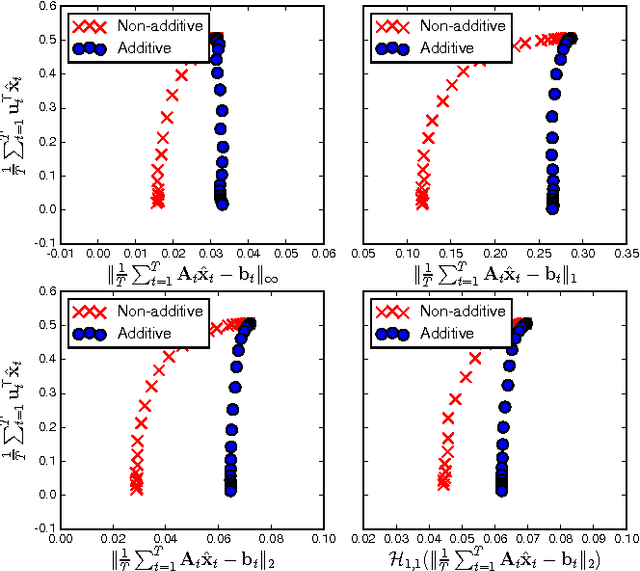
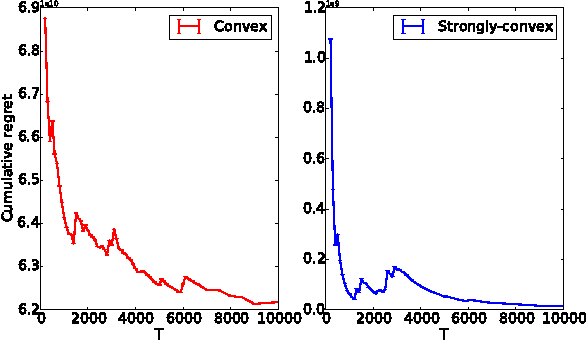
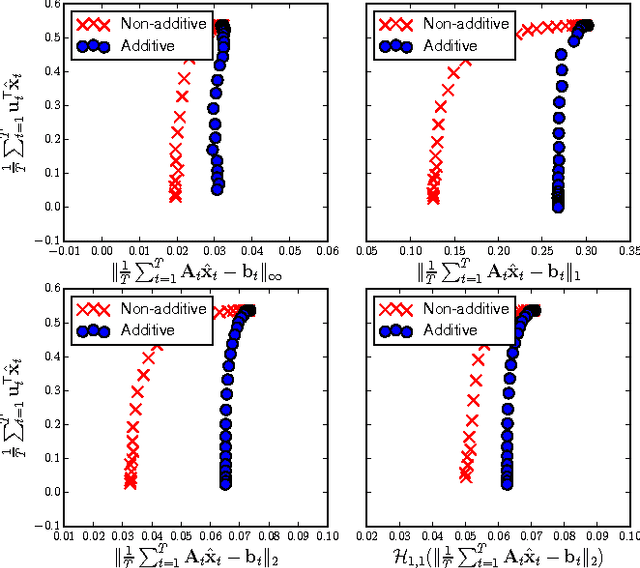
We consider online optimization in the 1-lookahead setting, where the objective does not decompose additively over the rounds of the online game. The resulting formulation enables us to deal with non-stationary and/or long-term constraints , which arise, for example, in online display advertising problems. We propose an on-line primal-dual algorithm for which we obtain dynamic cumulative regret guarantees. They depend on the convexity and the smoothness of the non-additive penalty, as well as terms capturing the smoothness with which the residuals of the non-stationary and long-term constraints vary over the rounds. We conduct experiments on synthetic data to illustrate the benefits of the non-additive penalty and show vanishing regret convergence on live traffic data collected by a display advertising platform in production.
Adaptive Algorithms for Online Convex Optimization with Long-term Constraints
Dec 23, 2015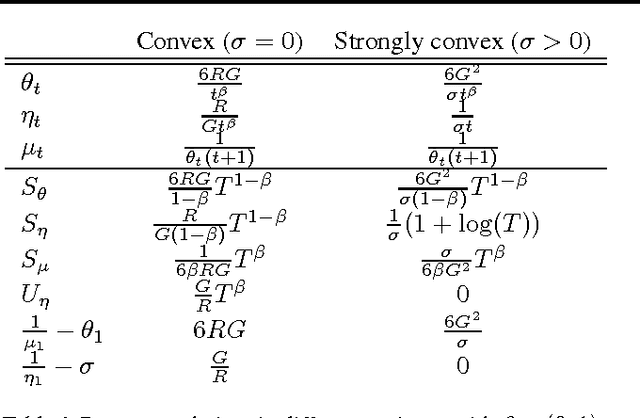
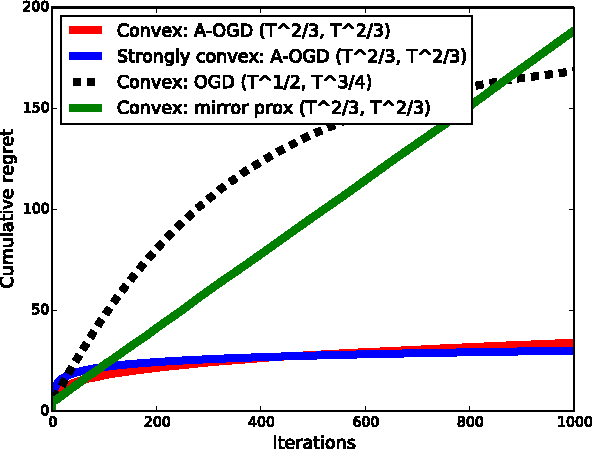
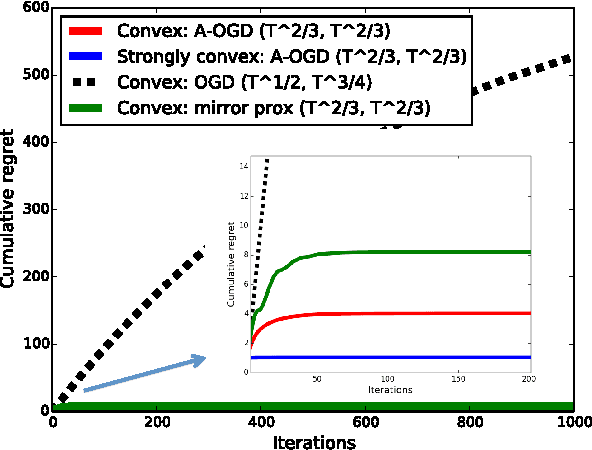
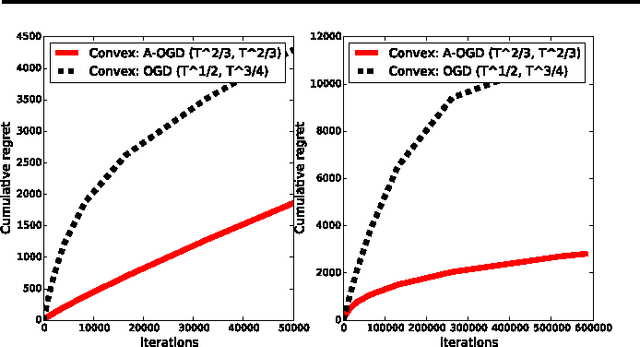
We present an adaptive online gradient descent algorithm to solve online convex optimization problems with long-term constraints , which are constraints that need to be satisfied when accumulated over a finite number of rounds T , but can be violated in intermediate rounds. For some user-defined trade-off parameter $\beta$ $\in$ (0, 1), the proposed algorithm achieves cumulative regret bounds of O(T^max{$\beta$,1--$\beta$}) and O(T^(1--$\beta$/2)) for the loss and the constraint violations respectively. Our results hold for convex losses and can handle arbitrary convex constraints without requiring knowledge of the number of rounds in advance. Our contributions improve over the best known cumulative regret bounds by Mahdavi, et al. (2012) that are respectively O(T^1/2) and O(T^3/4) for general convex domains, and respectively O(T^2/3) and O(T^2/3) when further restricting to polyhedral domains. We supplement the analysis with experiments validating the performance of our algorithm in practice.
Sparse and spurious: dictionary learning with noise and outliers
Aug 22, 2015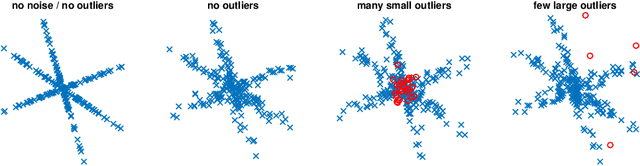
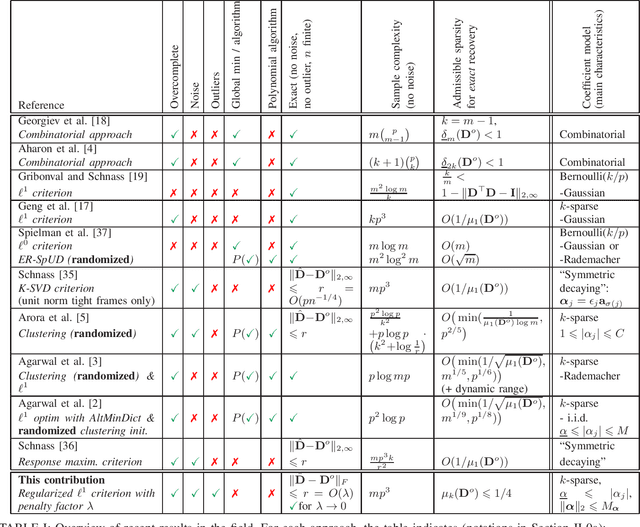
A popular approach within the signal processing and machine learning communities consists in modelling signals as sparse linear combinations of atoms selected from a learned dictionary. While this paradigm has led to numerous empirical successes in various fields ranging from image to audio processing, there have only been a few theoretical arguments supporting these evidences. In particular, sparse coding, or sparse dictionary learning, relies on a non-convex procedure whose local minima have not been fully analyzed yet. In this paper, we consider a probabilistic model of sparse signals, and show that, with high probability, sparse coding admits a local minimum around the reference dictionary generating the signals. Our study takes into account the case of over-complete dictionaries, noisy signals, and possible outliers, thus extending previous work limited to noiseless settings and/or under-complete dictionaries. The analysis we conduct is non-asymptotic and makes it possible to understand how the key quantities of the problem, such as the coherence or the level of noise, can scale with respect to the dimension of the signals, the number of atoms, the sparsity and the number of observations.
Sample Complexity of Dictionary Learning and other Matrix Factorizations
Apr 09, 2015

Many modern tools in machine learning and signal processing, such as sparse dictionary learning, principal component analysis (PCA), non-negative matrix factorization (NMF), $K$-means clustering, etc., rely on the factorization of a matrix obtained by concatenating high-dimensional vectors from a training collection. While the idealized task would be to optimize the expected quality of the factors over the underlying distribution of training vectors, it is achieved in practice by minimizing an empirical average over the considered collection. The focus of this paper is to provide sample complexity estimates to uniformly control how much the empirical average deviates from the expected cost function. Standard arguments imply that the performance of the empirical predictor also exhibit such guarantees. The level of genericity of the approach encompasses several possible constraints on the factors (tensor product structure, shift-invariance, sparsity \ldots), thus providing a unified perspective on the sample complexity of several widely used matrix factorization schemes. The derived generalization bounds behave proportional to $\sqrt{\log(n)/n}$ w.r.t.\ the number of samples $n$ for the considered matrix factorization techniques.
* to appear