 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCreatures great and SMAL: Recovering the shape and motion of animals from video
Nov 14, 2018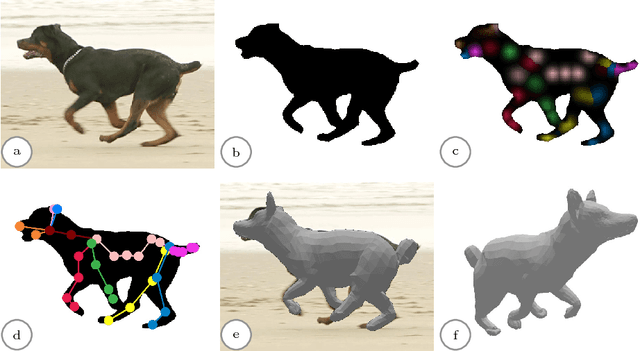
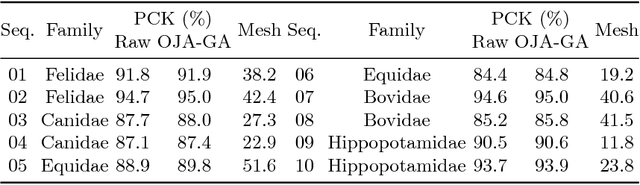

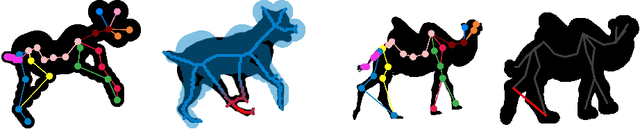
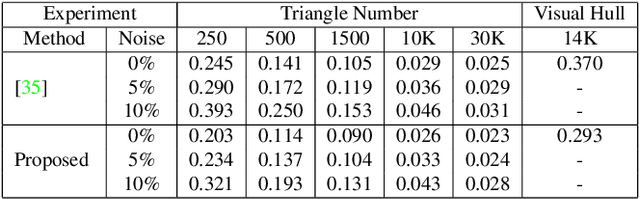
We present a system to recover the 3D shape and motion of a wide variety of quadrupeds from video. The system comprises a machine learning front-end which predicts candidate 2D joint positions, a discrete optimization which finds kinematically plausible joint correspondences, and an energy minimization stage which fits a detailed 3D model to the image. In order to overcome the limited availability of motion capture training data from animals, and the difficulty of generating realistic synthetic training images, the system is designed to work on silhouette data. The joint candidate predictor is trained on synthetically generated silhouette images, and at test time, deep learning methods or standard video segmentation tools are used to extract silhouettes from real data. The system is tested on animal videos from several species, and shows accurate reconstructions of 3D shape and pose.
A Differential Volumetric Approach to Multi-View Photometric Stereo
Nov 05, 2018

Highly accurate 3D volumetric reconstruction is still an open research topic where the main difficulties are usually related to merging rough estimations with high frequency details. One of the most promising methods is the fusion between multi-view stereo and photometric imaging 3D shape reconstruction techniques. However, beside the intrinsic difficulties that multi-view stereo and photometric stereo have to make them working reliably, supplementary problems raise when considered together. Most importantly, the projection of the fine details usually retrievable with photometric stereo onto the rough multi-view stereo reconstruction is difficult to handle. In this work, we present a volumetric approach to the multi-view photometric stereo problem defined by a unified differential model. The key to our method is the signed distance field parameterisation which avoids the complex step of re-projecting high frequency details as the parameterisation of the whole volume allows a photometric modeling on the volume itself efficiently dealing with occlusions, discontinuities, etc. The relation between the surface normals and the gradient of the signed distance field leads to a homogeneous linear partial differential equation. A variational optimisation is adopted in order to combine multiple images from multiple points of view in a single system avoiding the need of merging depth maps. Our approach is evaluated on synthetic and real data-sets and achieves state-of-the-art results.
Convolutional CRFs for Semantic Segmentation
May 15, 2018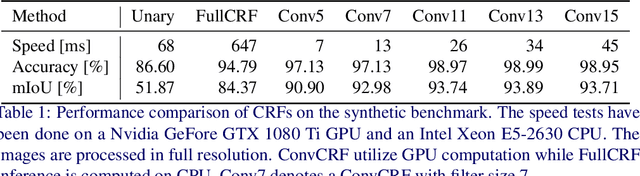

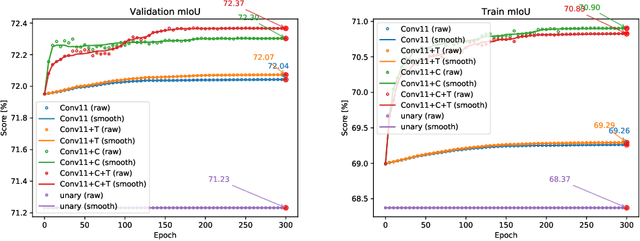
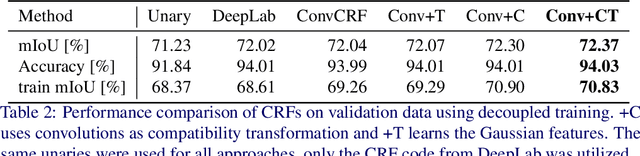
For the challenging semantic image segmentation task the most efficient models have traditionally combined the structured modelling capabilities of Conditional Random Fields (CRFs) with the feature extraction power of CNNs. In more recent works however, CRF post-processing has fallen out of favour. We argue that this is mainly due to the slow training and inference speeds of CRFs, as well as the difficulty of learning the internal CRF parameters. To overcome both issues we propose to add the assumption of conditional independence to the framework of fully-connected CRFs. This allows us to reformulate the inference in terms of convolutions, which can be implemented highly efficiently on GPUs. Doing so speeds up inference and training by a factor of more then 100. All parameters of the convolutional CRFs can easily be optimized using backpropagation. To facilitating further CRF research we make our implementation publicly available. Please visit: https://github.com/MarvinTeichmann/ConvCRF
MultiNet: Real-time Joint Semantic Reasoning for Autonomous Driving
May 08, 2018
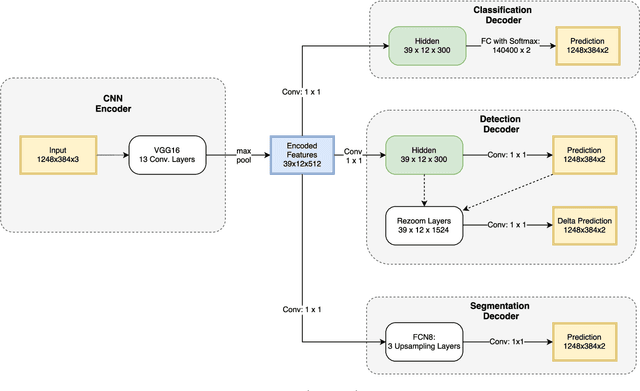
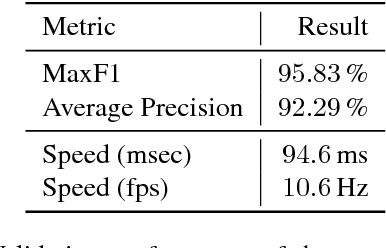
While most approaches to semantic reasoning have focused on improving performance, in this paper we argue that computational times are very important in order to enable real time applications such as autonomous driving. Towards this goal, we present an approach to joint classification, detection and semantic segmentation via a unified architecture where the encoder is shared amongst the three tasks. Our approach is very simple, can be trained end-to-end and performs extremely well in the challenging KITTI dataset, outperforming the state-of-the-art in the road segmentation task. Our approach is also very efficient, taking less than 100 ms to perform all tasks.
Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics
Apr 24, 2018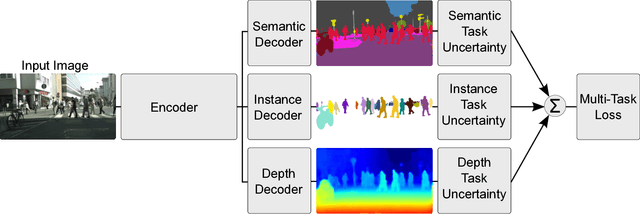

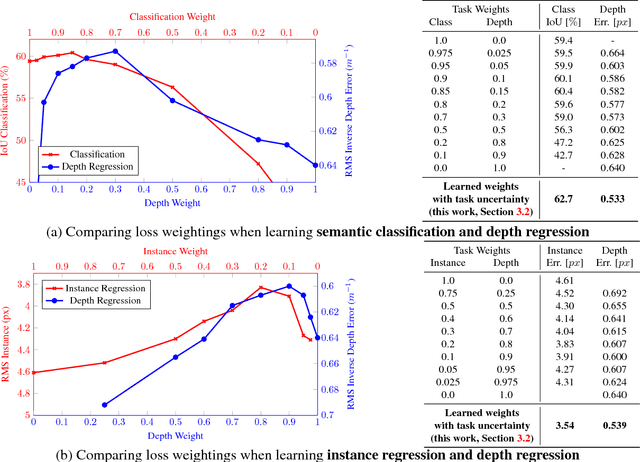

Numerous deep learning applications benefit from multi-task learning with multiple regression and classification objectives. In this paper we make the observation that the performance of such systems is strongly dependent on the relative weighting between each task's loss. Tuning these weights by hand is a difficult and expensive process, making multi-task learning prohibitive in practice. We propose a principled approach to multi-task deep learning which weighs multiple loss functions by considering the homoscedastic uncertainty of each task. This allows us to simultaneously learn various quantities with different units or scales in both classification and regression settings. We demonstrate our model learning per-pixel depth regression, semantic and instance segmentation from a monocular input image. Perhaps surprisingly, we show our model can learn multi-task weightings and outperform separate models trained individually on each task.
Geometric Loss Functions for Camera Pose Regression with Deep Learning
May 23, 2017

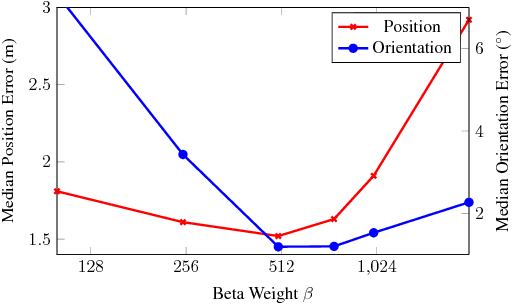

Deep learning has shown to be effective for robust and real-time monocular image relocalisation. In particular, PoseNet is a deep convolutional neural network which learns to regress the 6-DOF camera pose from a single image. It learns to localize using high level features and is robust to difficult lighting, motion blur and unknown camera intrinsics, where point based SIFT registration fails. However, it was trained using a naive loss function, with hyper-parameters which require expensive tuning. In this paper, we give the problem a more fundamental theoretical treatment. We explore a number of novel loss functions for learning camera pose which are based on geometry and scene reprojection error. Additionally we show how to automatically learn an optimal weighting to simultaneously regress position and orientation. By leveraging geometry, we demonstrate that our technique significantly improves PoseNet's performance across datasets ranging from indoor rooms to a small city.
Deep Roots: Improving CNN Efficiency with Hierarchical Filter Groups
Nov 30, 2016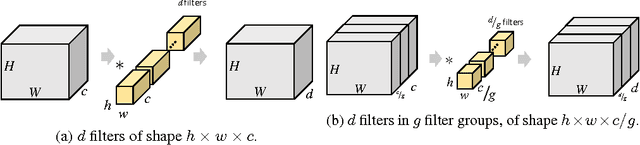

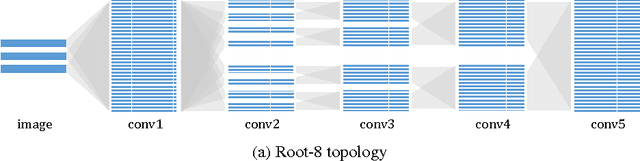
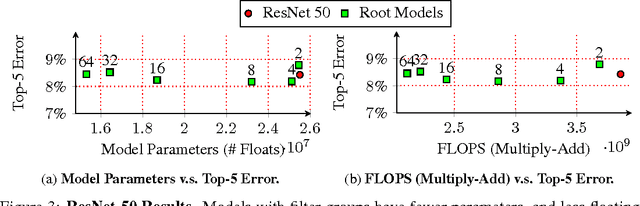
We propose a new method for creating computationally efficient and compact convolutional neural networks (CNNs) using a novel sparse connection structure that resembles a tree root. This allows a significant reduction in computational cost and number of parameters compared to state-of-the-art deep CNNs, without compromising accuracy, by exploiting the sparsity of inter-layer filter dependencies. We validate our approach by using it to train more efficient variants of state-of-the-art CNN architectures, evaluated on the CIFAR10 and ILSVRC datasets. Our results show similar or higher accuracy than the baseline architectures with much less computation, as measured by CPU and GPU timings. For example, for ResNet 50, our model has 40% fewer parameters, 45% fewer floating point operations, and is 31% (12%) faster on a CPU (GPU). For the deeper ResNet 200 our model has 25% fewer floating point operations and 44% fewer parameters, while maintaining state-of-the-art accuracy. For GoogLeNet, our model has 7% fewer parameters and is 21% (16%) faster on a CPU (GPU).
Bayesian SegNet: Model Uncertainty in Deep Convolutional Encoder-Decoder Architectures for Scene Understanding
Oct 10, 2016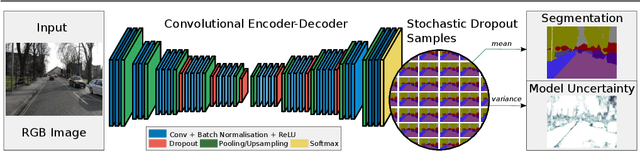

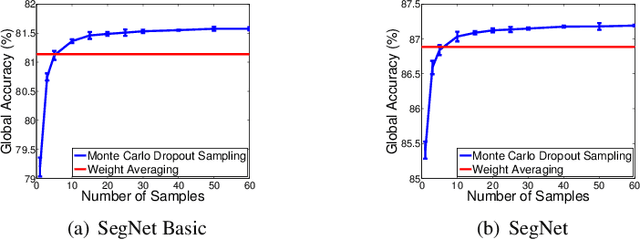

We present a deep learning framework for probabilistic pixel-wise semantic segmentation, which we term Bayesian SegNet. Semantic segmentation is an important tool for visual scene understanding and a meaningful measure of uncertainty is essential for decision making. Our contribution is a practical system which is able to predict pixel-wise class labels with a measure of model uncertainty. We achieve this by Monte Carlo sampling with dropout at test time to generate a posterior distribution of pixel class labels. In addition, we show that modelling uncertainty improves segmentation performance by 2-3% across a number of state of the art architectures such as SegNet, FCN and Dilation Network, with no additional parametrisation. We also observe a significant improvement in performance for smaller datasets where modelling uncertainty is more effective. We benchmark Bayesian SegNet on the indoor SUN Scene Understanding and outdoor CamVid driving scenes datasets.
SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
Oct 10, 2016
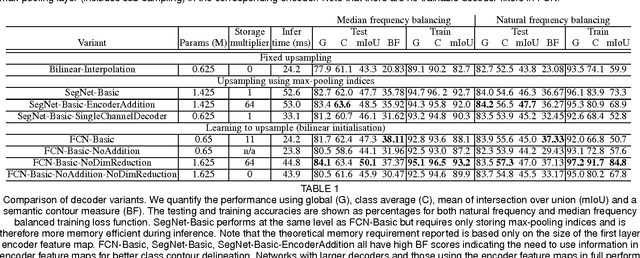
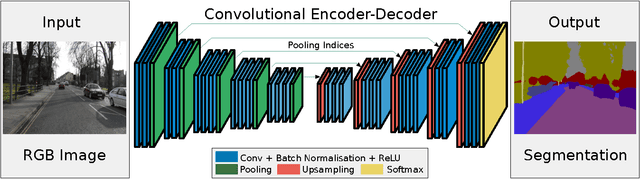
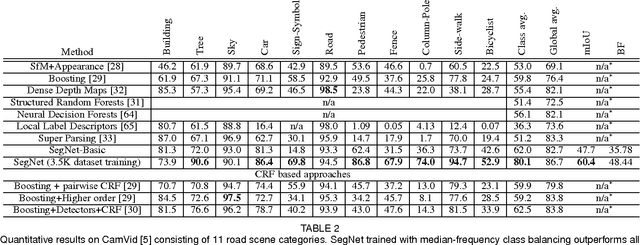
We present a novel and practical deep fully convolutional neural network architecture for semantic pixel-wise segmentation termed SegNet. This core trainable segmentation engine consists of an encoder network, a corresponding decoder network followed by a pixel-wise classification layer. The architecture of the encoder network is topologically identical to the 13 convolutional layers in the VGG16 network. The role of the decoder network is to map the low resolution encoder feature maps to full input resolution feature maps for pixel-wise classification. The novelty of SegNet lies is in the manner in which the decoder upsamples its lower resolution input feature map(s). Specifically, the decoder uses pooling indices computed in the max-pooling step of the corresponding encoder to perform non-linear upsampling. This eliminates the need for learning to upsample. The upsampled maps are sparse and are then convolved with trainable filters to produce dense feature maps. We compare our proposed architecture with the widely adopted FCN and also with the well known DeepLab-LargeFOV, DeconvNet architectures. This comparison reveals the memory versus accuracy trade-off involved in achieving good segmentation performance. SegNet was primarily motivated by scene understanding applications. Hence, it is designed to be efficient both in terms of memory and computational time during inference. It is also significantly smaller in the number of trainable parameters than other competing architectures. We also performed a controlled benchmark of SegNet and other architectures on both road scenes and SUN RGB-D indoor scene segmentation tasks. We show that SegNet provides good performance with competitive inference time and more efficient inference memory-wise as compared to other architectures. We also provide a Caffe implementation of SegNet and a web demo at http://mi.eng.cam.ac.uk/projects/segnet/.
Spatio-temporal video autoencoder with differentiable memory
Sep 01, 2016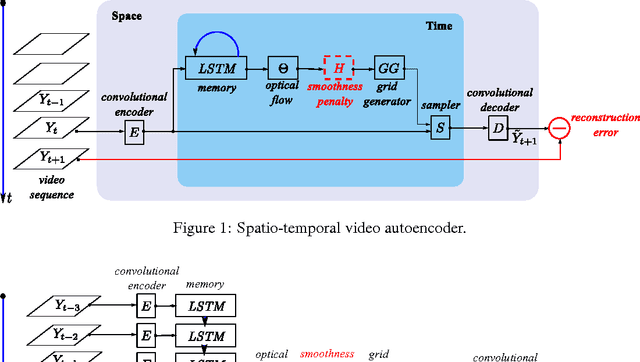
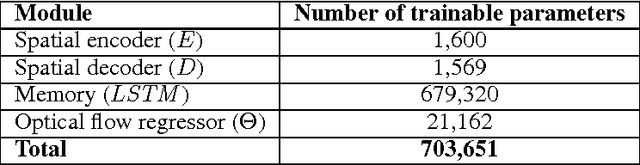


We describe a new spatio-temporal video autoencoder, based on a classic spatial image autoencoder and a novel nested temporal autoencoder. The temporal encoder is represented by a differentiable visual memory composed of convolutional long short-term memory (LSTM) cells that integrate changes over time. Here we target motion changes and use as temporal decoder a robust optical flow prediction module together with an image sampler serving as built-in feedback loop. The architecture is end-to-end differentiable. At each time step, the system receives as input a video frame, predicts the optical flow based on the current observation and the LSTM memory state as a dense transformation map, and applies it to the current frame to generate the next frame. By minimising the reconstruction error between the predicted next frame and the corresponding ground truth next frame, we train the whole system to extract features useful for motion estimation without any supervision effort. We present one direct application of the proposed framework in weakly-supervised semantic segmentation of videos through label propagation using optical flow.