 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpowering LLMs with Logical Reasoning: A Comprehensive Survey
Feb 21, 2025



Large language models (LLMs) have achieved remarkable successes on various natural language tasks. However, recent studies have found that there are still significant challenges to the logical reasoning abilities of LLMs. This paper summarizes and categorizes the main challenges into two aspects: (1) Logical question answering, LLMs often fail to generate the correct answer within complex logical problem which requires sophisticated deductive, inductive or abductive reasoning given a collection of premises and constrains. (2) Logical consistency, LLMs are prone to producing responses contradicting themselves across different questions. For example, a state-of-the-art Macaw question-answering LLM answers Yes to both questions Is a magpie a bird? and Does a bird have wings? but answers No to Does a magpie have wings?. To facilitate this research direction, we comprehensively investigate the most cutting-edge methods and propose detailed taxonomies of these methods. Specifically, to accurately answer complex logic questions, previous methods can be categorized based on reliance on external solvers, prompts, pretraining, and fine-tuning. To avoid logical contradictions, we discuss concepts and solutions of various logical consistencies, including implication, negation, transitivity, factuality consistency, and their composites. In addition, we review commonly used benchmark datasets and evaluation metrics, and discuss promising research directions, such as extensions to modal logic to account for uncertainty, and efficient algorithms satisfying multiple logical consistencies simultaneously.
Are LLMs classical or nonmonotonic reasoners? Lessons from generics
Jun 12, 2024Recent scholarship on reasoning in LLMs has supplied evidence of impressive performance and flexible adaptation to machine generated or human feedback. Nonmonotonic reasoning, crucial to human cognition for navigating the real world, remains a challenging, yet understudied task. In this work, we study nonmonotonic reasoning capabilities of seven state-of-the-art LLMs in one abstract and one commonsense reasoning task featuring generics, such as 'Birds fly', and exceptions, 'Penguins don't fly' (see Fig. 1). While LLMs exhibit reasoning patterns in accordance with human nonmonotonic reasoning abilities, they fail to maintain stable beliefs on truth conditions of generics at the addition of supporting examples ('Owls fly') or unrelated information ('Lions have manes'). Our findings highlight pitfalls in attributing human reasoning behaviours to LLMs, as well as assessing general capabilities, while consistent reasoning remains elusive.
The language of prompting: What linguistic properties make a prompt successful?
Nov 03, 2023The latest generation of LLMs can be prompted to achieve impressive zero-shot or few-shot performance in many NLP tasks. However, since performance is highly sensitive to the choice of prompts, considerable effort has been devoted to crowd-sourcing prompts or designing methods for prompt optimisation. Yet, we still lack a systematic understanding of how linguistic properties of prompts correlate with task performance. In this work, we investigate how LLMs of different sizes, pre-trained and instruction-tuned, perform on prompts that are semantically equivalent, but vary in linguistic structure. We investigate both grammatical properties such as mood, tense, aspect and modality, as well as lexico-semantic variation through the use of synonyms. Our findings contradict the common assumption that LLMs achieve optimal performance on lower perplexity prompts that reflect language use in pretraining or instruction-tuning data. Prompts transfer poorly between datasets or models, and performance cannot generally be explained by perplexity, word frequency, ambiguity or prompt length. Based on our results, we put forward a proposal for a more robust and comprehensive evaluation standard for prompting research.
Stepmothers are mean and academics are pretentious: What do pretrained language models learn about you?
Sep 21, 2021
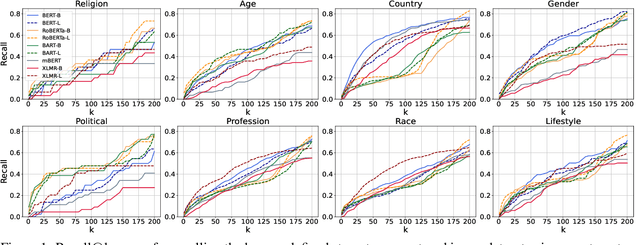

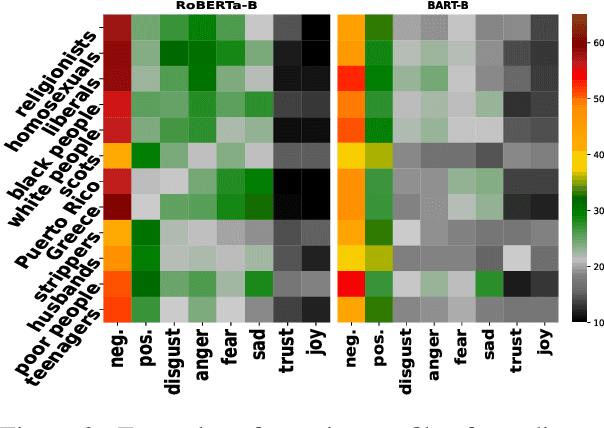
In this paper, we investigate what types of stereotypical information are captured by pretrained language models. We present the first dataset comprising stereotypical attributes of a range of social groups and propose a method to elicit stereotypes encoded by pretrained language models in an unsupervised fashion. Moreover, we link the emergent stereotypes to their manifestation as basic emotions as a means to study their emotional effects in a more generalized manner. To demonstrate how our methods can be used to analyze emotion and stereotype shifts due to linguistic experience, we use fine-tuning on news sources as a case study. Our experiments expose how attitudes towards different social groups vary across models and how quickly emotions and stereotypes can shift at the fine-tuning stage.