 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-lingual Evaluation of Code Generation Models
Oct 26, 2022



We present MBXP, an execution-based code completion benchmark in 10+ programming languages. This collection of datasets is generated by our conversion framework that translates prompts and test cases from the original MBPP dataset to the corresponding data in a target language. Based on this benchmark, we are able to evaluate code generation models in a multi-lingual fashion, and in particular discover generalization ability of language models on out-of-domain languages, advantages of large multi-lingual models over mono-lingual, benefits of few-shot prompting, and zero-shot translation abilities. In addition, we use our code generation model to perform large-scale bootstrapping to obtain synthetic canonical solutions in several languages. These solutions can be used for other code-related evaluations such as insertion-based, summarization, or code translation tasks where we demonstrate results and release as part of our benchmark.
Gradient Boosted Flows
Feb 27, 2020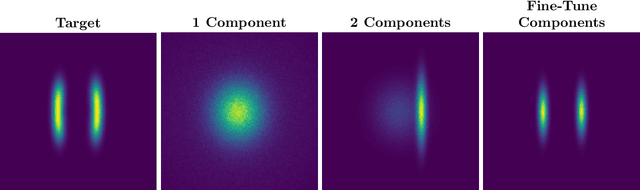
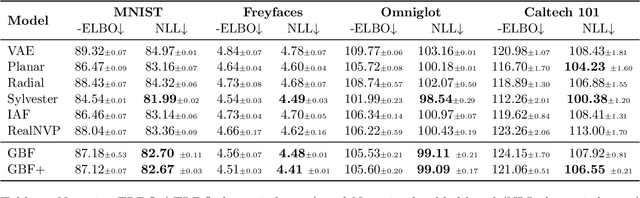
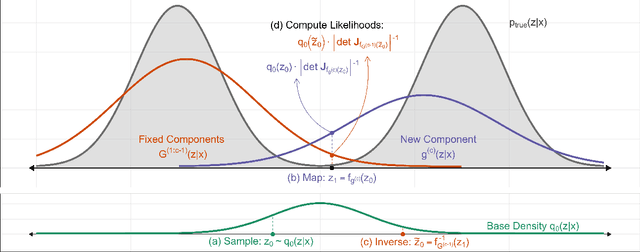
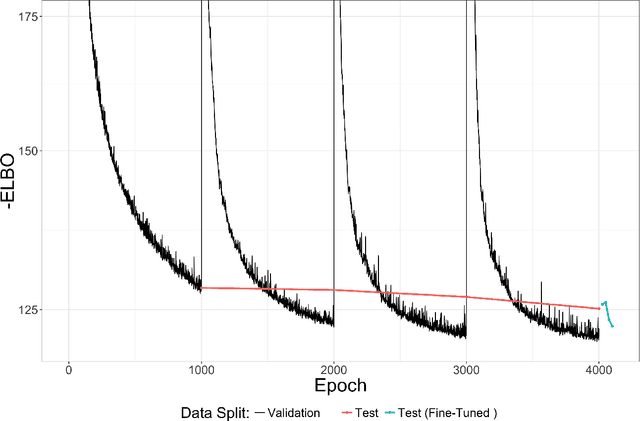
Normalizing flows (NF) are a powerful framework for approximating posteriors. By mapping a simple base density through invertible transformations, flows provide an exact method of density evaluation and sampling. The trend in normalizing flow literature has been to devise deeper, more complex transformations to achieve greater flexibility. We propose an alternative: Gradient Boosted Flows (GBF) model a variational posterior by successively adding new NF components by gradient boosting so that each new NF component is fit to the residuals of the previously trained components. The GBF formulation results in a variational posterior that is a mixture model, whose flexibility increases as more components are added. Moreover, GBFs offer a wider, not deeper, approach that can be incorporated to improve the results of many existing NFs. We demonstrate the effectiveness of this technique for density estimation and, by coupling GBF with a variational autoencoder, generative modeling of images.
DAPPER: Scaling Dynamic Author Persona Topic Model to Billion Word Corpora
Nov 03, 2018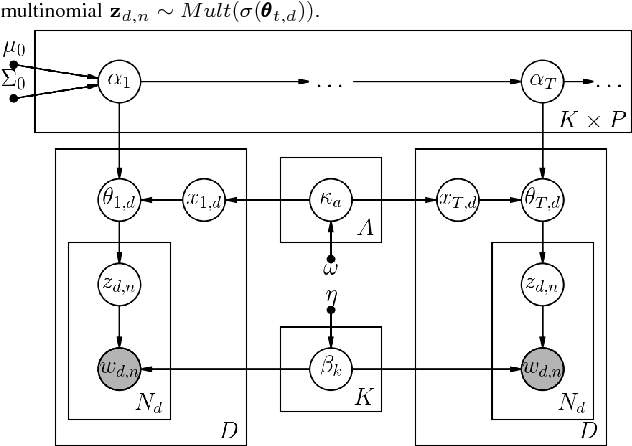
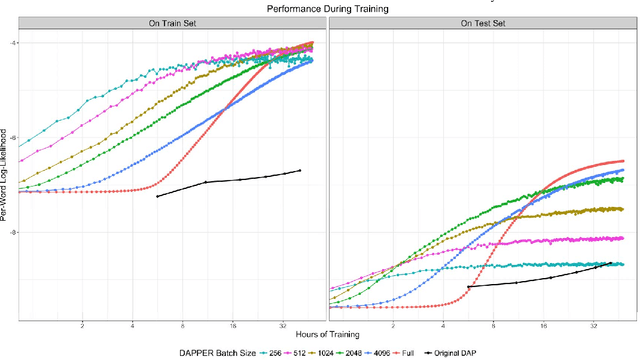
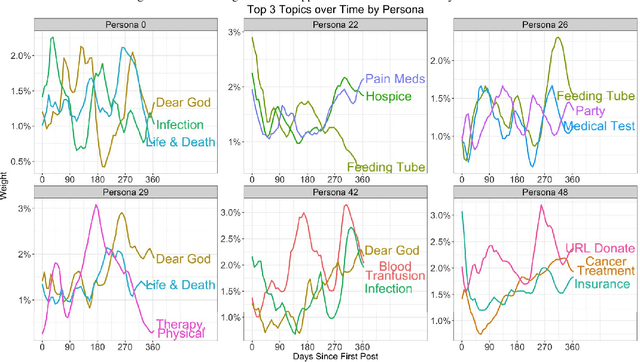
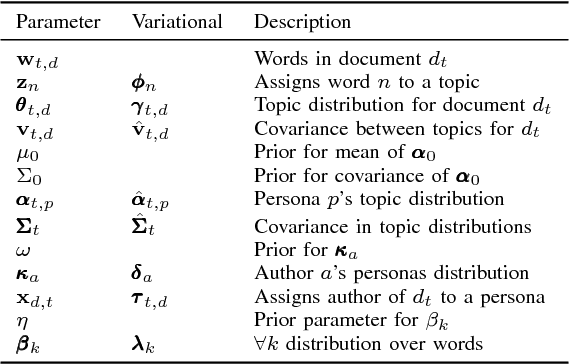
Extracting common narratives from multi-author dynamic text corpora requires complex models, such as the Dynamic Author Persona (DAP) topic model. However, such models are complex and can struggle to scale to large corpora, often because of challenging non-conjugate terms. To overcome such challenges, in this paper we adapt new ideas in approximate inference to the DAP model, resulting in the DAP Performed Exceedingly Rapidly (DAPPER) topic model. Specifically, we develop Conjugate-Computation Variational Inference (CVI) based variational Expectation-Maximization (EM) for learning the model, yielding fast, closed form updates for each document, replacing iterative optimization in earlier work. Our results show significant improvements in model fit and training time without needing to compromise the model's temporal structure or the application of Regularized Variation Inference (RVI). We demonstrate the scalability and effectiveness of the DAPPER model by extracting health journeys from the CaringBridge corpus --- a collection of 9 million journals written by 200,000 authors during health crises.
Topic Modeling on Health Journals with Regularized Variational Inference
Jan 15, 2018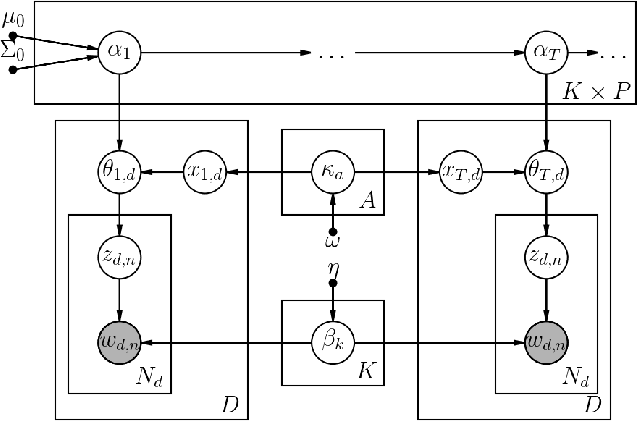

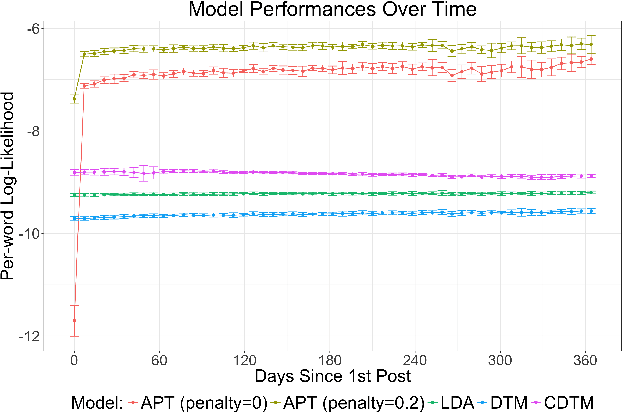
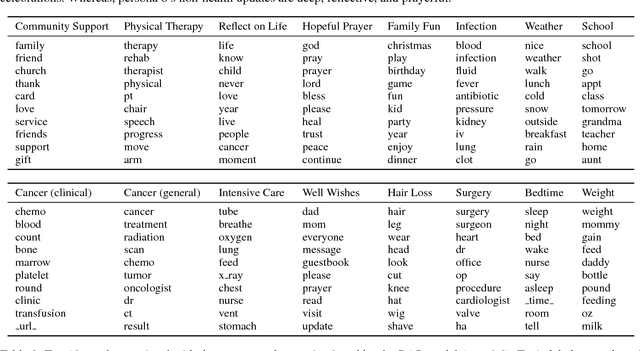
Topic modeling enables exploration and compact representation of a corpus. The CaringBridge (CB) dataset is a massive collection of journals written by patients and caregivers during a health crisis. Topic modeling on the CB dataset, however, is challenging due to the asynchronous nature of multiple authors writing about their health journeys. To overcome this challenge we introduce the Dynamic Author-Persona topic model (DAP), a probabilistic graphical model designed for temporal corpora with multiple authors. The novelty of the DAP model lies in its representation of authors by a persona --- where personas capture the propensity to write about certain topics over time. Further, we present a regularized variational inference algorithm, which we use to encourage the DAP model's personas to be distinct. Our results show significant improvements over competing topic models --- particularly after regularization, and highlight the DAP model's unique ability to capture common journeys shared by different authors.