 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Nonparametric Density Estimation with Tensor Decompositions
Oct 06, 2020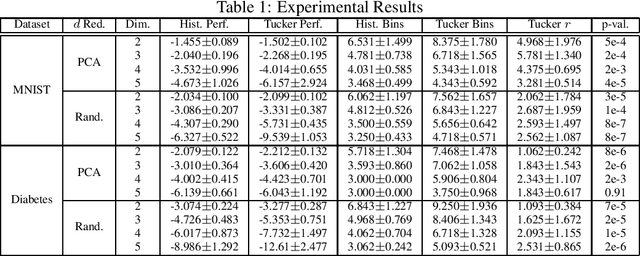
While nonparametric density estimators often perform well on low dimensional data, their performance can suffer when applied to higher dimensional data, owing presumably to the curse of dimensionality. One technique for avoiding this is to assume no dependence between features and that the data are sampled from a separable density. This allows one to estimate each marginal distribution independently thereby avoiding the slow rates associated with estimating the full joint density. This is a strategy employed in naive Bayes models and is analogous to estimating a rank-one tensor. In this paper we investigate whether these improvements can be extended to other simplified dependence assumptions which we model via nonnegative tensor decompositions. In our central theoretical results we prove that restricting estimation to low-rank nonnegative PARAFAC or Tucker decompositions removes the dimensionality exponent on bin width rates for multidimensional histograms. These results are validated experimentally with high statistical significance via direct application of existing nonnegative tensor factorization to histogram estimators.
Deep Anomaly Detection by Residual Adaptation
Oct 05, 2020
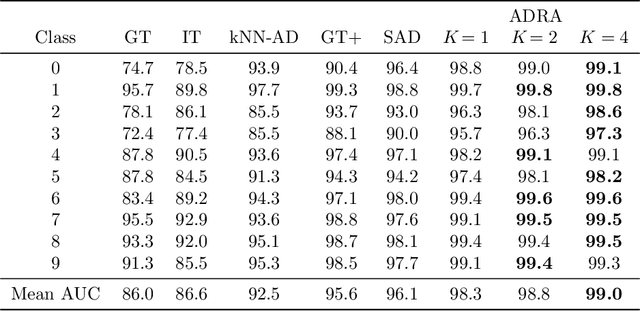
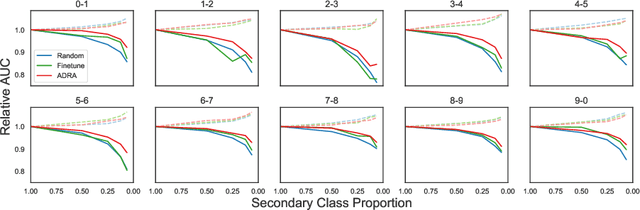
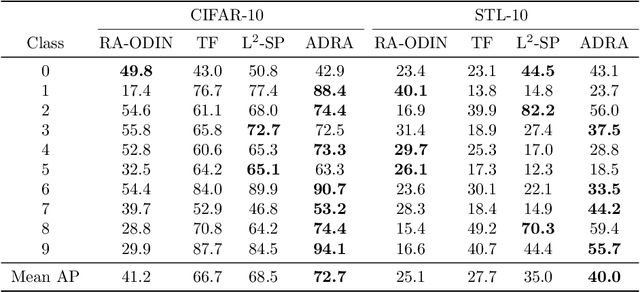
Deep anomaly detection is a difficult task since, in high dimensions, it is hard to completely characterize a notion of "differentness" when given only examples of normality. In this paper we propose a novel approach to deep anomaly detection based on augmenting large pretrained networks with residual corrections that adjusts them to the task of anomaly detection. Our method gives rise to a highly parameter-efficient learning mechanism, enhances disentanglement of representations in the pretrained model, and outperforms all existing anomaly detection methods including other baselines utilizing pretrained networks. On the CIFAR-10 one-versus-rest benchmark, for example, our technique raises the state of the art from 96.1 to 99.0 mean AUC.
A Unifying Review of Deep and Shallow Anomaly Detection
Sep 28, 2020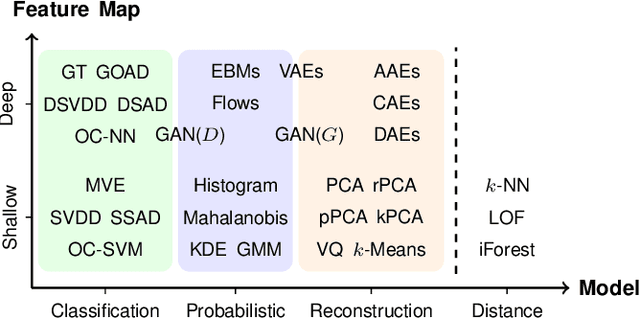

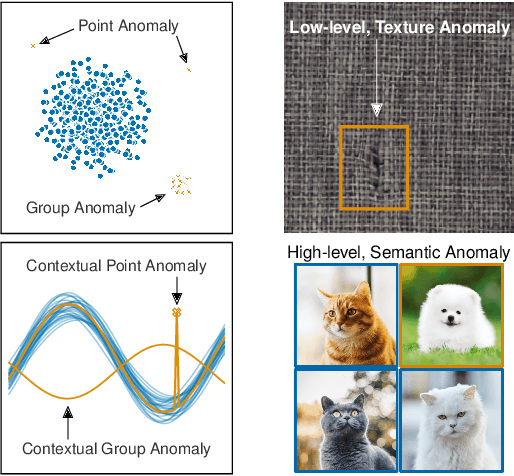
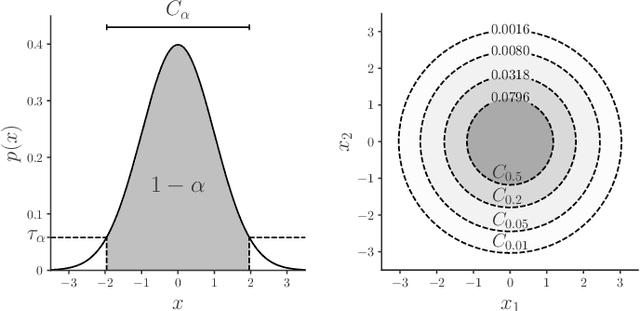
Deep learning approaches to anomaly detection have recently improved the state of the art in detection performance on complex datasets such as large collections of images or text. These results have sparked a renewed interest in the anomaly detection problem and led to the introduction of a great variety of new methods. With the emergence of numerous such methods, including approaches based on generative models, one-class classification, and reconstruction, there is a growing need to bring methods of this field into a systematic and unified perspective. In this review we aim to identify the common underlying principles as well as the assumptions that are often made implicitly by various methods. In particular, we draw connections between classic 'shallow' and novel deep approaches and show how this relation might cross-fertilize or extend both directions. We further provide an empirical assessment of major existing methods that is enriched by the use of recent explainability techniques, and present specific worked-through examples together with practical advice. Finally, we outline critical open challenges and identify specific paths for future research in anomaly detection.
Input Hessian Regularization of Neural Networks
Sep 14, 2020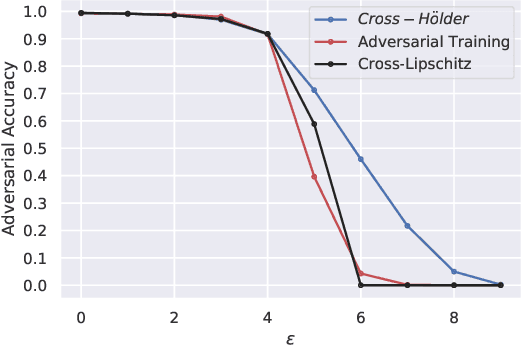
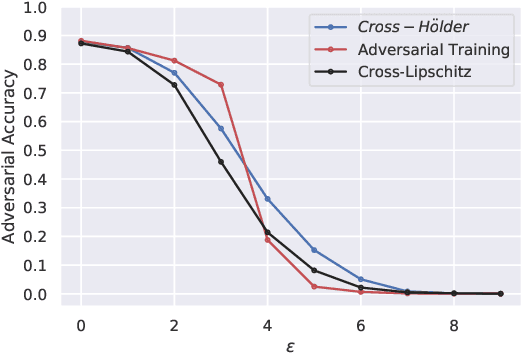
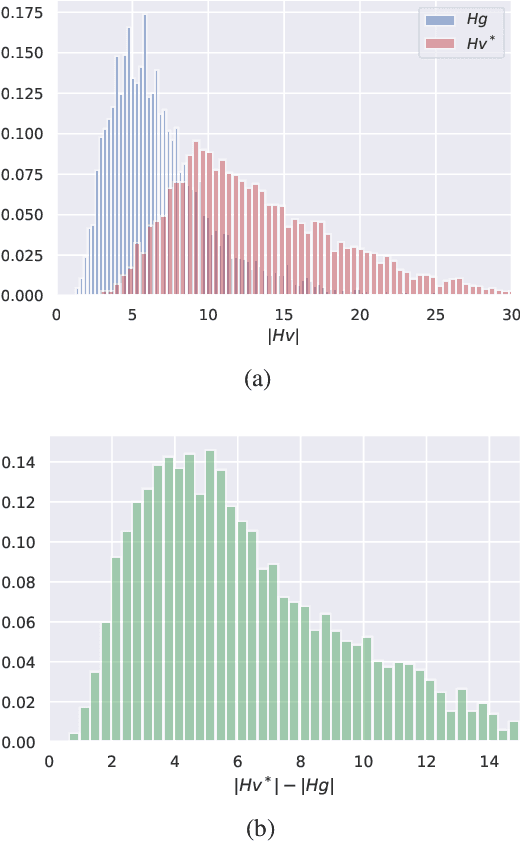
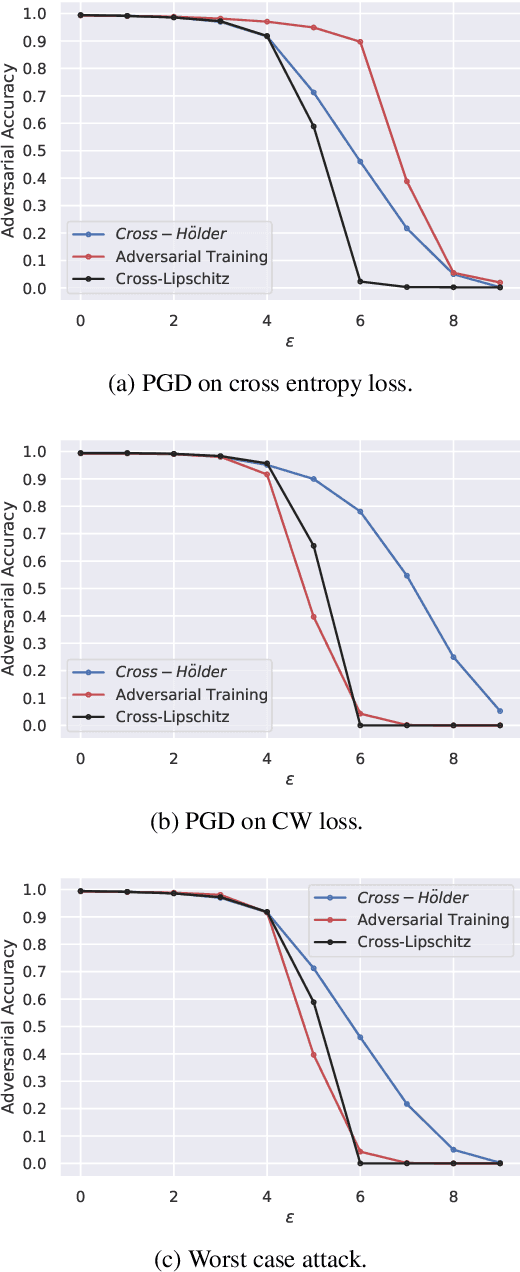
Regularizing the input gradient has shown to be effective in promoting the robustness of neural networks. The regularization of the input's Hessian is therefore a natural next step. A key challenge here is the computational complexity. Computing the Hessian of inputs is computationally infeasible. In this paper we propose an efficient algorithm to train deep neural networks with Hessian operator-norm regularization. We analyze the approach theoretically and prove that the Hessian operator norm relates to the ability of a neural network to withstand an adversarial attack. We give a preliminary experimental evaluation on the MNIST and FMNIST datasets, which demonstrates that the new regularizer can, indeed, be feasible and, furthermore, that it increases the robustness of neural networks over input gradient regularization.
Explainable Deep One-Class Classification
Jul 03, 2020

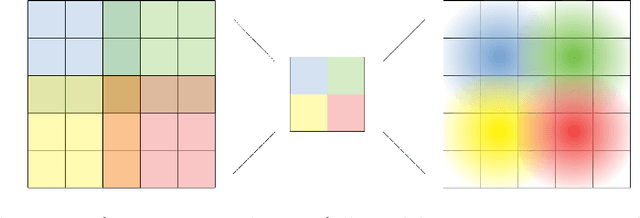
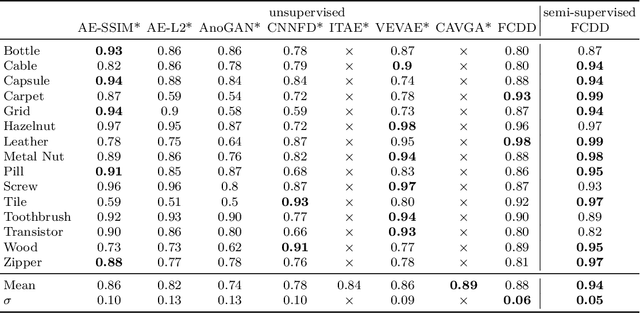
Deep one-class classification variants for anomaly detection learn a mapping that concentrates nominal samples in feature space causing anomalies to be mapped away. Because this transformation is highly non-linear, finding interpretations poses a significant challenge. In this paper we present an explainable deep one-class classification method, Fully Convolutional Data Description (FCDD), where the mapped samples are themselves also an explanation heatmap. FCDD yields competitive detection performance and provides reasonable explanations on common anomaly detection benchmarks with CIFAR-10 and ImageNet. On MVTec-AD, a recent manufacturing dataset offering ground-truth anomaly maps, FCDD meets the state of the art in an unsupervised setting, and outperforms its competitors in a semi-supervised setting. Finally, using FCDD's explanations we demonstrate the vulnerability of deep one-class classification models to spurious image features such as image watermarks.
Consistent Estimation of Identifiable Nonparametric Mixture Models from Grouped Observations
Jun 12, 2020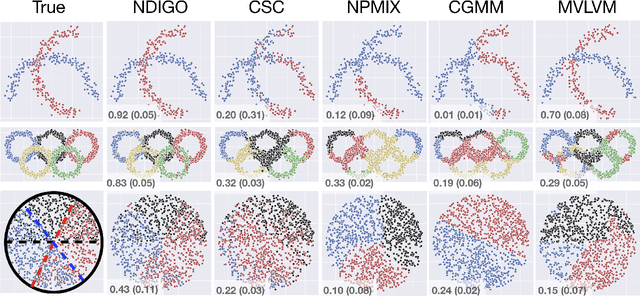
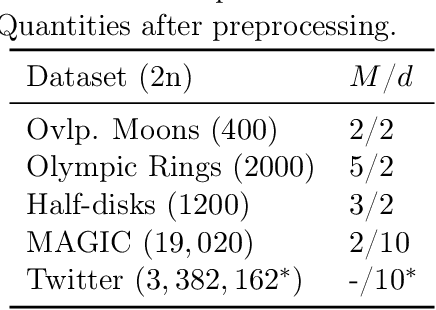


Recent research has established sufficient conditions for finite mixture models to be identifiable from grouped observations. These conditions allow the mixture components to be nonparametric and have substantial (or even total) overlap. This work proposes an algorithm that consistently estimates any identifiable mixture model from grouped observations. Our analysis leverages an oracle inequality for weighted kernel density estimators of the distribution on groups, together with a general result showing that consistent estimation of the distribution on groups implies consistent estimation of mixture components. A practical implementation is provided for paired observations, and the approach is shown to outperform existing methods, especially when mixture components overlap significantly.
Rethinking Assumptions in Deep Anomaly Detection
May 30, 2020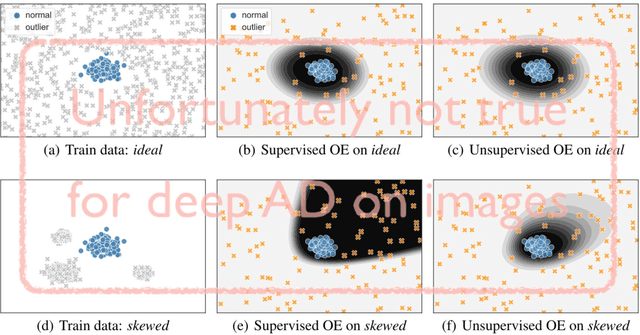
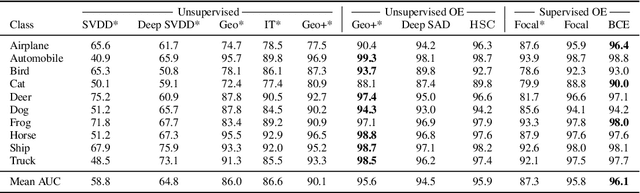
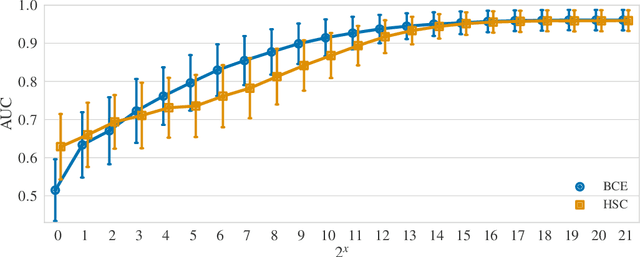
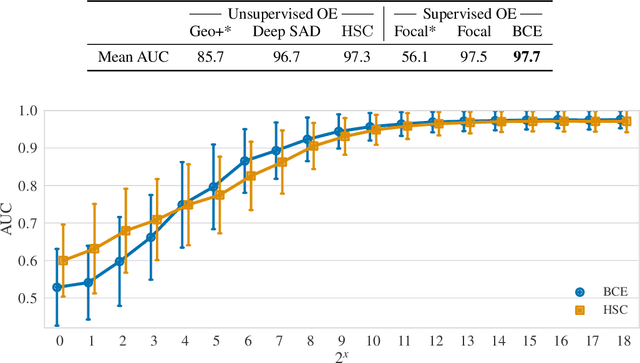
Though anomaly detection (AD) can be viewed as a classification problem (nominal vs. anomalous) it is usually treated in an unsupervised manner since one typically does not have access to, or it is infeasible to utilize, a dataset that sufficiently characterizes what it means to be "anomalous." In this paper we present results demonstrating that this intuition surprisingly does not extend to deep AD on images. For a recent AD benchmark on ImageNet, classifiers trained to discern between normal samples and just a few (64) random natural images are able to outperform the current state of the art in deep AD. We find that this approach is also very effective at other common image AD benchmarks. Experimentally we discover that the multiscale structure of image data makes example anomalies exceptionally informative.
Machine Learning in Thermodynamics: Prediction of Activity Coefficients by Matrix Completion
Jan 29, 2020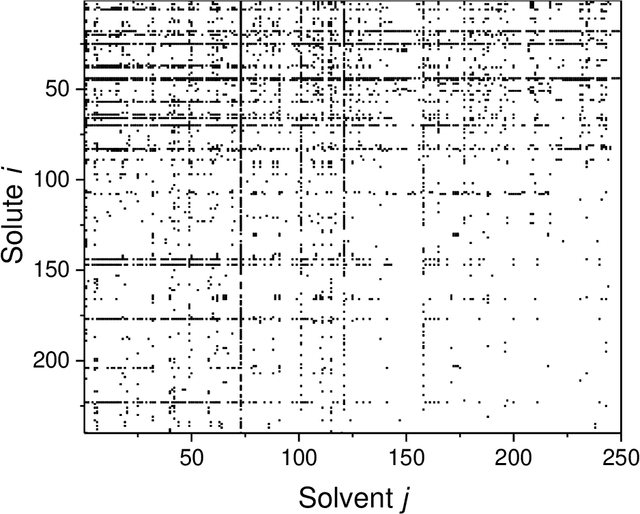
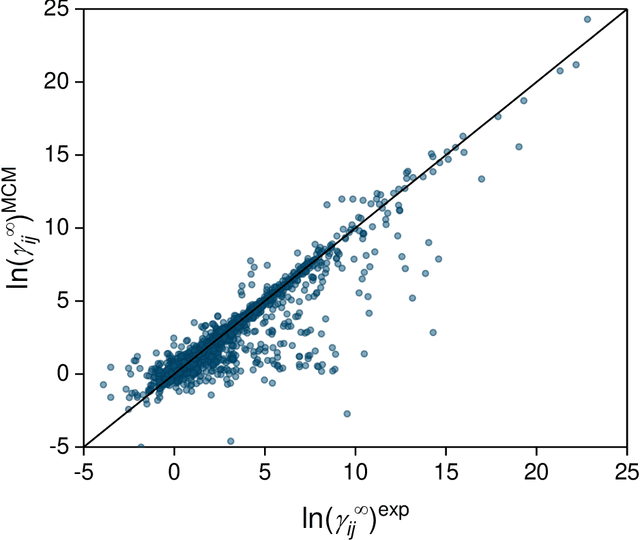
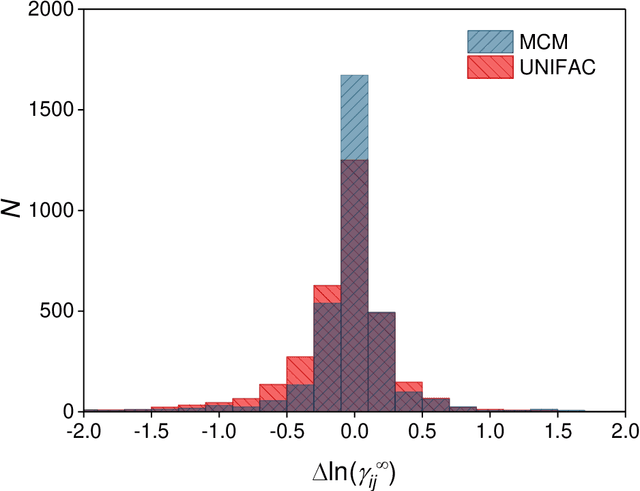
Activity coefficients, which are a measure of the non-ideality of liquid mixtures, are a key property in chemical engineering with relevance to modeling chemical and phase equilibria as well as transport processes. Although experimental data on thousands of binary mixtures are available, prediction methods are needed to calculate the activity coefficients in many relevant mixtures that have not been explored to-date. In this report, we propose a probabilistic matrix factorization model for predicting the activity coefficients in arbitrary binary mixtures. Although no physical descriptors for the considered components were used, our method outperforms the state-of-the-art method that has been refined over three decades while requiring much less training effort. This opens perspectives to novel methods for predicting physico-chemical properties of binary mixtures with the potential to revolutionize modeling and simulation in chemical engineering.
* Published version: J. Phys. Chem. Lett. 11 (2020) 981-985; https://pubs.acs.org/doi/full/10.1021/acs.jpclett.9b03657
Deep Semi-Supervised Anomaly Detection
Jun 06, 2019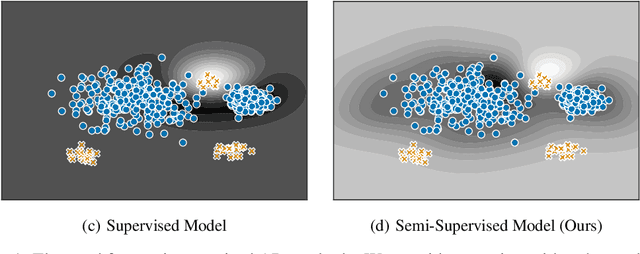
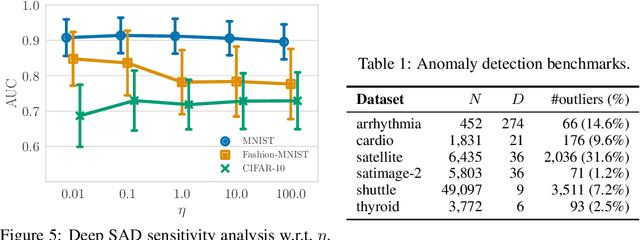
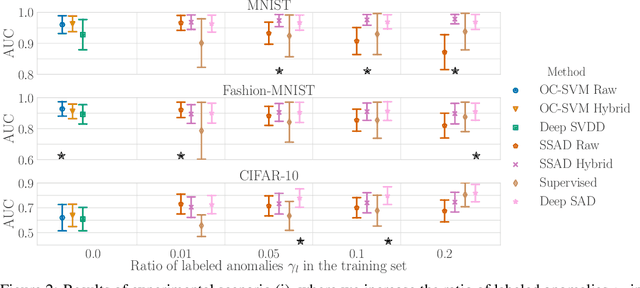
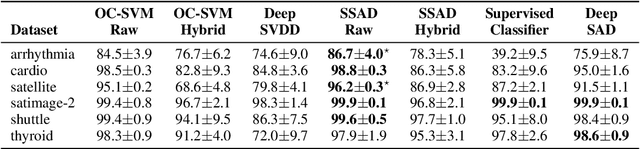
Deep approaches to anomaly detection have recently shown promising results over shallow approaches on high-dimensional data. Typically anomaly detection is treated as an unsupervised learning problem. In practice however, one may have---in addition to a large set of unlabeled samples---access to a small pool of labeled samples, e.g. a subset verified by some domain expert as being normal or anomalous. Semi-supervised approaches to anomaly detection make use of such labeled data to improve detection performance. Few deep semi-supervised approaches to anomaly detection have been proposed so far and those that exist are domain-specific. In this work, we present Deep SAD, an end-to-end methodology for deep semi-supervised anomaly detection. Using an information-theoretic perspective on anomaly detection, we derive a loss motivated by the idea that the entropy for the latent distribution of normal data should be lower than the entropy of the anomalous distribution. We demonstrate in extensive experiments on MNIST, Fashion-MNIST, and CIFAR-10 along with other anomaly detection benchmark datasets that our approach is on par or outperforms shallow, hybrid, and deep competitors, even when provided with only few labeled training data.
An Operator Theoretic Approach to Nonparametric Mixture Models
Oct 13, 2016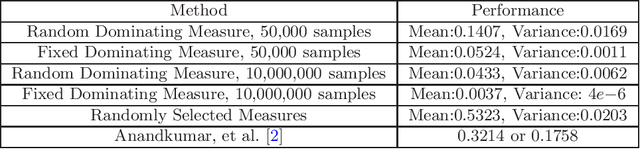
When estimating finite mixture models, it is common to make assumptions on the mixture components, such as parametric assumptions. In this work, we make no distributional assumptions on the mixture components and instead assume that observations from the mixture model are grouped, such that observations in the same group are known to be drawn from the same mixture component. We precisely characterize the number of observations $n$ per group needed for the mixture model to be identifiable, as a function of the number $m$ of mixture components. In addition to our assumption-free analysis, we also study the settings where the mixture components are either linearly independent or jointly irreducible. Furthermore, our analysis considers two kinds of identifiability -- where the mixture model is the simplest one explaining the data, and where it is the only one. As an application of these results, we precisely characterize identifiability of multinomial mixture models. Our analysis relies on an operator-theoretic framework that associates mixture models in the grouped-sample setting with certain infinite-dimensional tensors. Based on this framework, we introduce general spectral algorithms for recovering the mixture components and illustrate their use on a synthetic data set.