 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Classification-Calibration of Gamma-Phi Losses
Feb 14, 2023Gamma-Phi losses constitute a family of multiclass classification loss functions that generalize the logistic and other common losses, and have found application in the boosting literature. We establish the first general sufficient condition for the classification-calibration of such losses. In addition, we show that a previously proposed sufficient condition is in fact not sufficient.
Consistent Interpolating Ensembles via the Manifold-Hilbert Kernel
May 19, 2022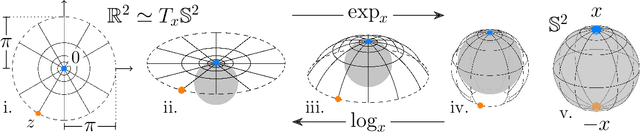
Recent research in the theory of overparametrized learning has sought to establish generalization guarantees in the interpolating regime. Such results have been established for a few common classes of methods, but so far not for ensemble methods. We devise an ensemble classification method that simultaneously interpolates the training data, and is consistent for a broad class of data distributions. To this end, we define the manifold-Hilbert kernel for data distributed on a Riemannian manifold. We prove that kernel smoothing regression using the manifold-Hilbert kernel is weakly consistent in the setting of Devroye et al. 1998. For the sphere, we show that the manifold-Hilbert kernel can be realized as a weighted random partition kernel, which arises as an infinite ensemble of partition-based classifiers.
VC dimension of partially quantized neural networks in the overparametrized regime
Oct 06, 2021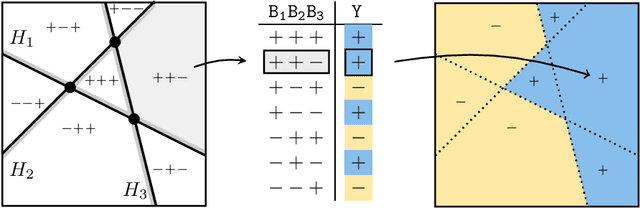

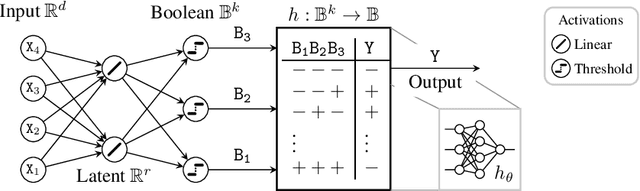

Vapnik-Chervonenkis (VC) theory has so far been unable to explain the small generalization error of overparametrized neural networks. Indeed, existing applications of VC theory to large networks obtain upper bounds on VC dimension that are proportional to the number of weights, and for a large class of networks, these upper bound are known to be tight. In this work, we focus on a class of partially quantized networks that we refer to as hyperplane arrangement neural networks (HANNs). Using a sample compression analysis, we show that HANNs can have VC dimension significantly smaller than the number of weights, while being highly expressive. In particular, empirical risk minimization over HANNs in the overparametrized regime achieves the minimax rate for classification with Lipschitz posterior class probability. We further demonstrate the expressivity of HANNs empirically. On a panel of 121 UCI datasets, overparametrized HANNs match the performance of state-of-the-art full-precision models.
An exact solver for the Weston-Watkins SVM subproblem
Feb 10, 2021
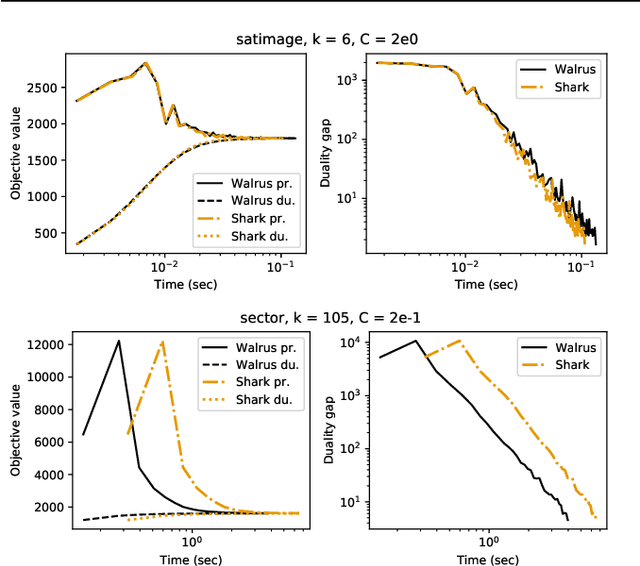
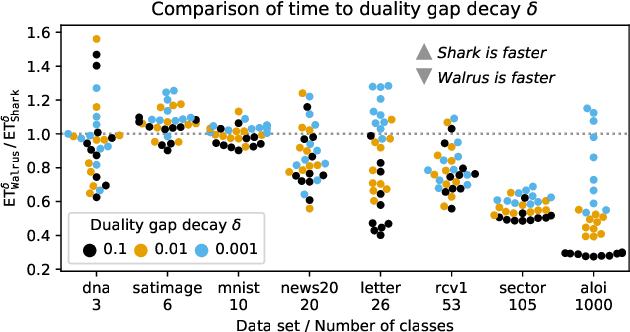
Recent empirical evidence suggests that the Weston-Watkins support vector machine is among the best performing multiclass extensions of the binary SVM. Current state-of-the-art solvers repeatedly solve a particular subproblem approximately using an iterative strategy. In this work, we propose an algorithm that solves the subproblem exactly using a novel reparametrization of the Weston-Watkins dual problem. For linear WW-SVMs, our solver shows significant speed-up over the state-of-the-art solver when the number of classes is large. Our exact subproblem solver also allows us to prove linear convergence of the overall solver.
Weston-Watkins Hinge Loss and Ordered Partitions
Jun 12, 2020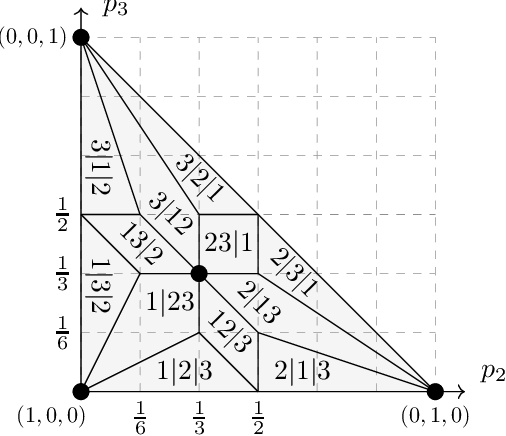
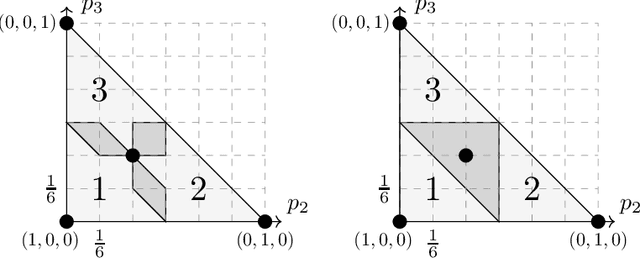
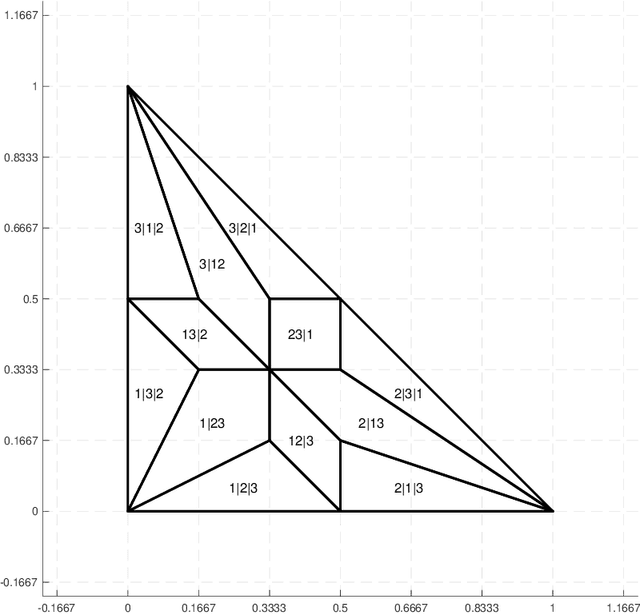
Multiclass extensions of the support vector machine (SVM) have been formulated in a variety of ways. A recent empirical comparison of nine such formulations [Do\v{g}an et al. 2016] recommends the variant proposed by Weston and Watkins (WW), despite the fact that the WW-hinge loss is not calibrated with respect to the 0-1 loss. In this work we introduce a novel discrete loss function for multiclass classification, the ordered partition loss, and prove that the WW-hinge loss is calibrated with respect to this loss. We also argue that the ordered partition loss is maximally informative among discrete losses satisfying this property. Finally, we apply our theory to justify the empirical observation made by Do\v{g}an et al. that the WW-SVM can work well even under massive label noise, a challenging setting for multiclass SVMs.
An Operator Theoretic Approach to Nonparametric Mixture Models
Oct 13, 2016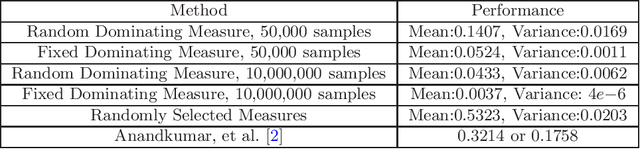
When estimating finite mixture models, it is common to make assumptions on the mixture components, such as parametric assumptions. In this work, we make no distributional assumptions on the mixture components and instead assume that observations from the mixture model are grouped, such that observations in the same group are known to be drawn from the same mixture component. We precisely characterize the number of observations $n$ per group needed for the mixture model to be identifiable, as a function of the number $m$ of mixture components. In addition to our assumption-free analysis, we also study the settings where the mixture components are either linearly independent or jointly irreducible. Furthermore, our analysis considers two kinds of identifiability -- where the mixture model is the simplest one explaining the data, and where it is the only one. As an application of these results, we precisely characterize identifiability of multinomial mixture models. Our analysis relies on an operator-theoretic framework that associates mixture models in the grouped-sample setting with certain infinite-dimensional tensors. Based on this framework, we introduce general spectral algorithms for recovering the mixture components and illustrate their use on a synthetic data set.
On The Identifiability of Mixture Models from Grouped Samples
Feb 23, 2015Finite mixture models are statistical models which appear in many problems in statistics and machine learning. In such models it is assumed that data are drawn from random probability measures, called mixture components, which are themselves drawn from a probability measure P over probability measures. When estimating mixture models, it is common to make assumptions on the mixture components, such as parametric assumptions. In this paper, we make no assumption on the mixture components, and instead assume that observations from the mixture model are grouped, such that observations in the same group are known to be drawn from the same component. We show that any mixture of m probability measures can be uniquely identified provided there are 2m-1 observations per group. Moreover we show that, for any m, there exists a mixture of m probability measures that cannot be uniquely identified when groups have 2m-2 observations. Our results hold for any sample space with more than one element.
Robust Kernel Density Estimation by Scaling and Projection in Hilbert Space
Nov 17, 2014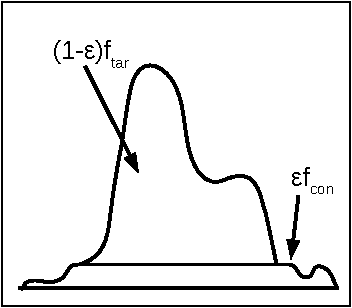
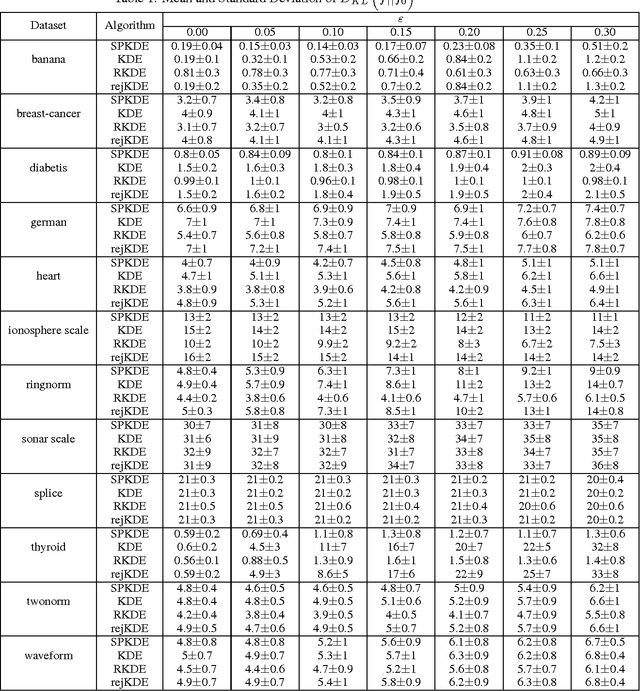
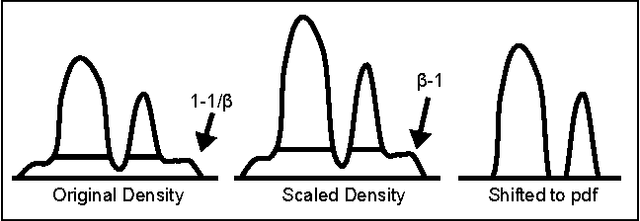
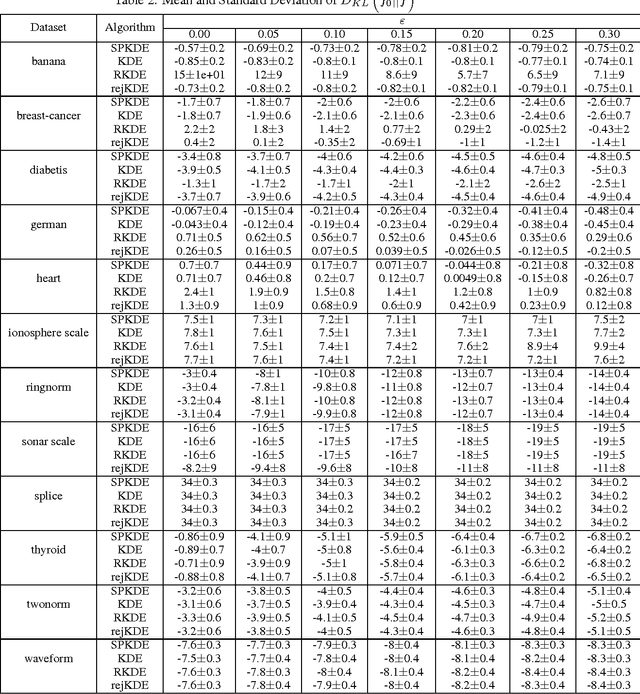
While robust parameter estimation has been well studied in parametric density estimation, there has been little investigation into robust density estimation in the nonparametric setting. We present a robust version of the popular kernel density estimator (KDE). As with other estimators, a robust version of the KDE is useful since sample contamination is a common issue with datasets. What "robustness" means for a nonparametric density estimate is not straightforward and is a topic we explore in this paper. To construct a robust KDE we scale the traditional KDE and project it to its nearest weighted KDE in the $L^2$ norm. This yields a scaled and projected KDE (SPKDE). Because the squared $L^2$ norm penalizes point-wise errors superlinearly this causes the weighted KDE to allocate more weight to high density regions. We demonstrate the robustness of the SPKDE with numerical experiments and a consistency result which shows that asymptotically the SPKDE recovers the uncontaminated density under sufficient conditions on the contamination.
Robust Kernel Density Estimation
Sep 06, 2011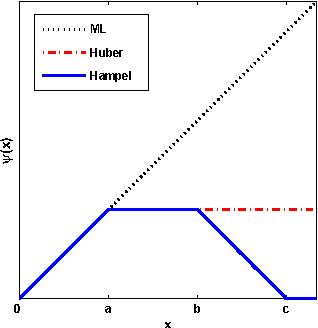
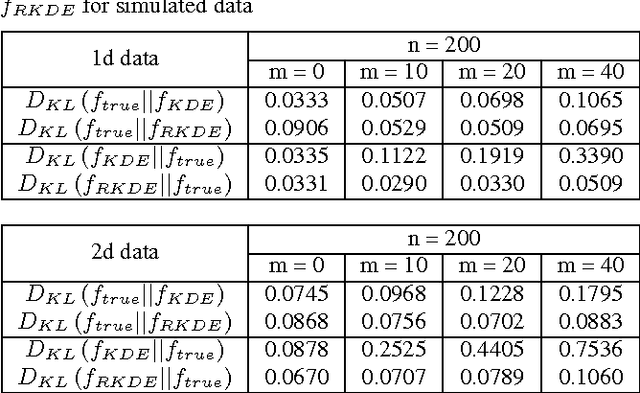
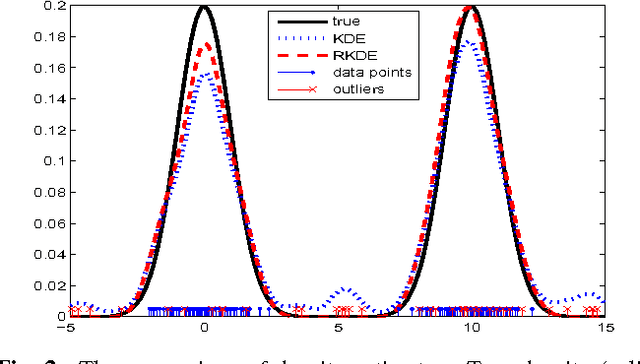
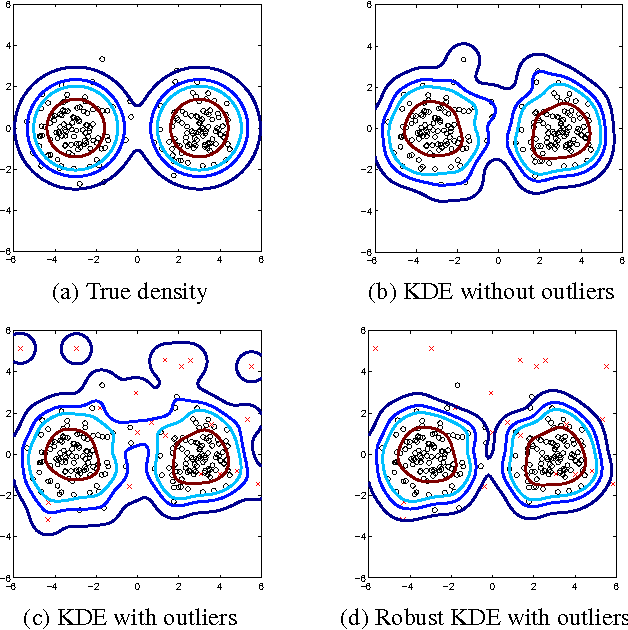
We propose a method for nonparametric density estimation that exhibits robustness to contamination of the training sample. This method achieves robustness by combining a traditional kernel density estimator (KDE) with ideas from classical $M$-estimation. We interpret the KDE based on a radial, positive semi-definite kernel as a sample mean in the associated reproducing kernel Hilbert space. Since the sample mean is sensitive to outliers, we estimate it robustly via $M$-estimation, yielding a robust kernel density estimator (RKDE). An RKDE can be computed efficiently via a kernelized iteratively re-weighted least squares (IRWLS) algorithm. Necessary and sufficient conditions are given for kernelized IRWLS to converge to the global minimizer of the $M$-estimator objective function. The robustness of the RKDE is demonstrated with a representer theorem, the influence function, and experimental results for density estimation and anomaly detection.