 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating Reflectance Layer from A Single Image: Integrating Reflectance Guidance and Shadow/Specular Aware Learning
Nov 27, 2022Estimating reflectance layer from a single image is a challenging task. It becomes more challenging when the input image contains shadows or specular highlights, which often render an inaccurate estimate of the reflectance layer. Therefore, we propose a two-stage learning method, including reflectance guidance and a Shadow/Specular-Aware (S-Aware) network to tackle the problem. In the first stage, an initial reflectance layer free from shadows and specularities is obtained with the constraint of novel losses that are guided by prior-based shadow-free and specular-free images. To further enforce the reflectance layer to be independent from shadows and specularities in the second-stage refinement, we introduce an S-Aware network that distinguishes the reflectance image from the input image. Our network employs a classifier to categorize shadow/shadow-free, specular/specular-free classes, enabling the activation features to function as attention maps that focus on shadow/specular regions. Our quantitative and qualitative evaluations show that our method outperforms the state-of-the-art methods in the reflectance layer estimation that is free from shadows and specularities.
* Accepted to AAAI2023
Object Detection in Foggy Scenes by Embedding Depth and Reconstruction into Domain Adaptation
Nov 24, 2022Most existing domain adaptation (DA) methods align the features based on the domain feature distributions and ignore aspects related to fog, background and target objects, rendering suboptimal performance. In our DA framework, we retain the depth and background information during the domain feature alignment. A consistency loss between the generated depth and fog transmission map is introduced to strengthen the retention of the depth information in the aligned features. To address false object features potentially generated during the DA process, we propose an encoder-decoder framework to reconstruct the fog-free background image. This reconstruction loss also reinforces the encoder, i.e., our DA backbone, to minimize false object features.Moreover, we involve our target data in training both our DA module and our detection module in a semi-supervised manner, so that our detection module is also exposed to the unlabeled target data, the type of data used in the testing stage. Using these ideas, our method significantly outperforms the state-of-the-art method (47.6 mAP against the 44.3 mAP on the Foggy Cityscapes dataset), and obtains the best performance on multiple real-image public datasets. Code is available at: https://github.com/VIML-CVDL/Object-Detection-in-Foggy-Scenes
TransCC: Transformer-based Multiple Illuminant Color Constancy Using Multitask Learning
Nov 16, 2022
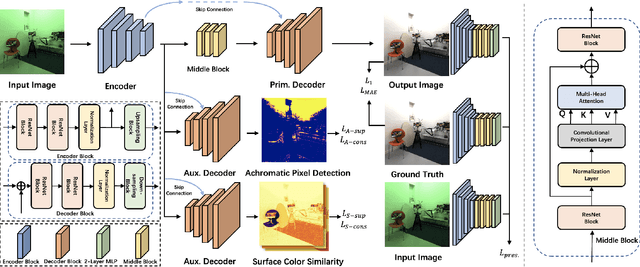

Multi-illuminant color constancy is a challenging problem with only a few existing methods. For example, one prior work used a small set of predefined white balance settings and spatially blended among them, limiting the solution to predefined illuminations. Another method proposed a generative adversarial network and an angular loss, yet the performance is suboptimal due to the lack of regularization for multi-illumination colors. This paper introduces a transformer-based multi-task learning method to estimate single and multiple light colors from a single input image. To help our deep learning model have better cues of the light colors, achromatic-pixel detection, and edge detection are used as auxiliary tasks in our multi-task learning setting. By exploiting extracted content features from the input image as tokens, illuminant color correlations between pixels are learned by leveraging contextual information in our transformer. Our transformer approach is further assisted via a contrastive loss defined between the input, output, and ground truth. We demonstrate that our proposed model achieves 40.7% improvement compared to a state-of-the-art multi-illuminant color constancy method on a multi-illuminant dataset (LSMI). Moreover, our model maintains a robust performance on the single illuminant dataset (NUS-8) and provides 22.3% improvement on the state-of-the-art single color constancy method.
Uncertainty-aware Gait Recognition via Learning from Dirichlet Distribution-based Evidence
Nov 15, 2022



Existing gait recognition frameworks retrieve an identity in the gallery based on the distance between a probe sample and the identities in the gallery. However, existing methods often neglect that the gallery may not contain identities corresponding to the probes, leading to recognition errors rather than raising an alarm. In this paper, we introduce a novel uncertainty-aware gait recognition method that models the uncertainty of identification based on learned evidence. Specifically, we treat our recognition model as an evidence collector to gather evidence from input samples and parameterize a Dirichlet distribution over the evidence. The Dirichlet distribution essentially represents the density of the probability assigned to the input samples. We utilize the distribution to evaluate the resultant uncertainty of each probe sample and then determine whether a probe has a counterpart in the gallery or not. To the best of our knowledge, our method is the first attempt to tackle gait recognition with uncertainty modelling. Moreover, our uncertain modeling significantly improves the robustness against out-of-distribution (OOD) queries. Extensive experiments demonstrate that our method achieves state-of-the-art performance on datasets with OOD queries, and can also generalize well to other identity-retrieval tasks. Importantly, our method outperforms the state-of-the-art by a large margin of 44.19% when the OOD query rate is around 50% on OUMVLP.
ShadowDiffusion: Diffusion-based Shadow Removal using Classifier-driven Attention and Structure Preservation
Nov 15, 2022



Shadow removal from a single image is challenging, particularly with the presence of soft and self shadows. Unlike hard shadows, soft shadows do not show any clear boundaries, while self shadows are shadows that cast on the object itself. Most existing methods require the detection/annotation of binary shadow masks, without taking into account the ambiguous boundaries of soft and self shadows. Most deep learning shadow removal methods are GAN-based and require statistical similarity between shadow and shadow-free domains. In contrast to these methods, in this paper, we present ShadowDiffusion, the first diffusion-based shadow removal method. ShadowDiffusion focuses on single-image shadow removal, even in the presence of soft and self shadows. To guide the diffusion process to recover semantically meaningful structures during the reverse diffusion, we introduce a structure preservation loss, where we extract features from the pre-trained Vision Transformer (DINO-ViT). Moreover, to focus on the recovery of shadow regions, we inject classifier-driven attention into the architecture of the diffusion model. To maintain the consistent colors of the regions where the shadows have been removed, we introduce a chromaticity consistency loss. Our ShadowDiffusion outperforms state-of-the-art methods on the SRD, AISTD, LRSS, USR and UIUC datasets, removing hard, soft, and self shadows robustly. Our method outperforms the SOTA method by 20% of the RMSE of the whole image on the SRD dataset.
Structure Representation Network and Uncertainty Feedback Learning for Dense Non-Uniform Fog Removal
Oct 06, 2022
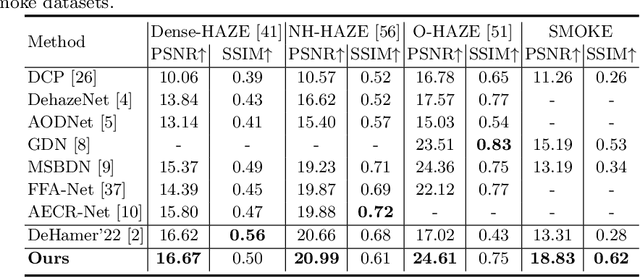
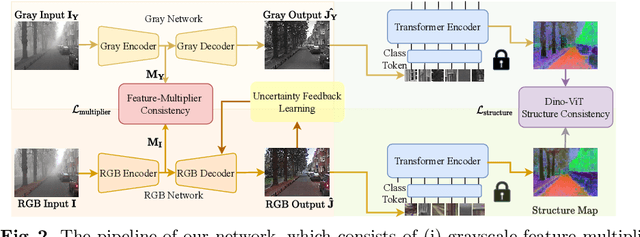

Few existing image defogging or dehazing methods consider dense and non-uniform particle distributions, which usually happen in smoke, dust and fog. Dealing with these dense and/or non-uniform distributions can be intractable, since fog's attenuation and airlight (or veiling effect) significantly weaken the background scene information in the input image. To address this problem, we introduce a structure-representation network with uncertainty feedback learning. Specifically, we extract the feature representations from a pre-trained Vision Transformer (DINO-ViT) module to recover the background information. To guide our network to focus on non-uniform fog areas, and then remove the fog accordingly, we introduce the uncertainty feedback learning, which produces the uncertainty maps, that have higher uncertainty in denser fog regions, and can be regarded as an attention map that represents fog's density and uneven distribution. Based on the uncertainty map, our feedback network refines our defogged output iteratively. Moreover, to handle the intractability of estimating the atmospheric light colors, we exploit the grayscale version of our input image, since it is less affected by varying light colors that are possibly present in the input image. The experimental results demonstrate the effectiveness of our method both quantitatively and qualitatively compared to the state-of-the-art methods in handling dense and non-uniform fog or smoke.
Bottom-Up 2D Pose Estimation via Dual Anatomical Centers for Small-Scale Persons
Aug 25, 2022

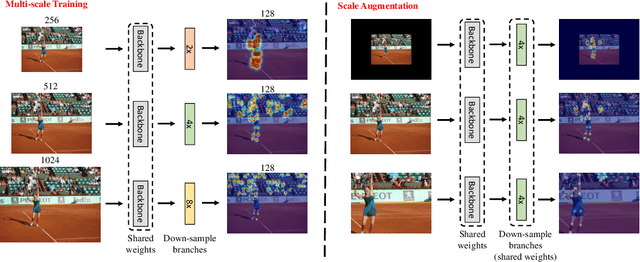

In multi-person 2D pose estimation, the bottom-up methods simultaneously predict poses for all persons, and unlike the top-down methods, do not rely on human detection. However, the SOTA bottom-up methods' accuracy is still inferior compared to the existing top-down methods. This is due to the predicted human poses being regressed based on the inconsistent human bounding box center and the lack of human-scale normalization, leading to the predicted human poses being inaccurate and small-scale persons being missed. To push the envelope of the bottom-up pose estimation, we firstly propose multi-scale training to enhance the network to handle scale variation with single-scale testing, particularly for small-scale persons. Secondly, we introduce dual anatomical centers (i.e., head and body), where we can predict the human poses more accurately and reliably, especially for small-scale persons. Moreover, existing bottom-up methods use multi-scale testing to boost the accuracy of pose estimation at the price of multiple additional forward passes, which weakens the efficiency of bottom-up methods, the core strength compared to top-down methods. By contrast, our multi-scale training enables the model to predict high-quality poses in a single forward pass (i.e., single-scale testing). Our method achieves 38.4\% improvement on bounding box precision and 39.1\% improvement on bounding box recall over the state of the art (SOTA) on the challenging small-scale persons subset of COCO. For the human pose AP evaluation, we achieve a new SOTA (71.0 AP) on the COCO test-dev set with the single-scale testing. We also achieve the top performance (40.3 AP) on OCHuman dataset in cross-dataset evaluation.
Unsupervised Night Image Enhancement: When Layer Decomposition Meets Light-Effects Suppression
Jul 21, 2022
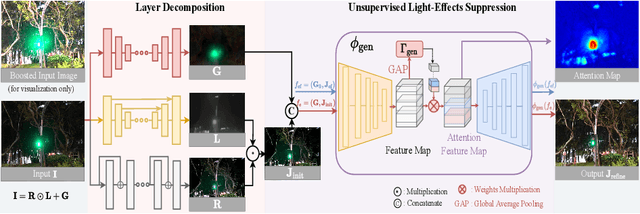
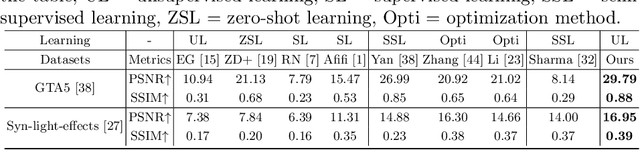

Night images suffer not only from low light, but also from uneven distributions of light. Most existing night visibility enhancement methods focus mainly on enhancing low-light regions. This inevitably leads to over enhancement and saturation in bright regions, such as those regions affected by light effects (glare, floodlight, etc). To address this problem, we need to suppress the light effects in bright regions while, at the same time, boosting the intensity of dark regions. With this idea in mind, we introduce an unsupervised method that integrates a layer decomposition network and a light-effects suppression network. Given a single night image as input, our decomposition network learns to decompose shading, reflectance and light-effects layers, guided by unsupervised layer-specific prior losses. Our light-effects suppression network further suppresses the light effects and, at the same time, enhances the illumination in dark regions. This light-effects suppression network exploits the estimated light-effects layer as the guidance to focus on the light-effects regions. To recover the background details and reduce hallucination/artefacts, we propose structure and high-frequency consistency losses. Our quantitative and qualitative evaluations on real images show that our method outperforms state-of-the-art methods in suppressing night light effects and boosting the intensity of dark regions.
* Accepted to ECCV2022
DC-ShadowNet: Single-Image Hard and Soft Shadow Removal Using Unsupervised Domain-Classifier Guided Network
Jul 21, 2022
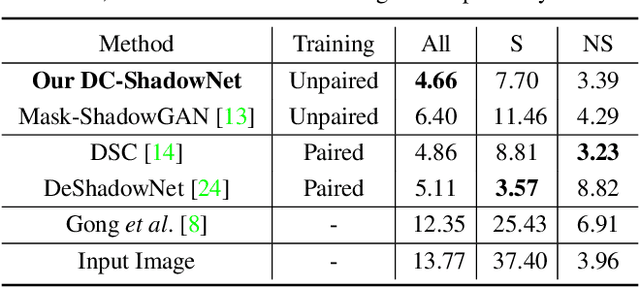
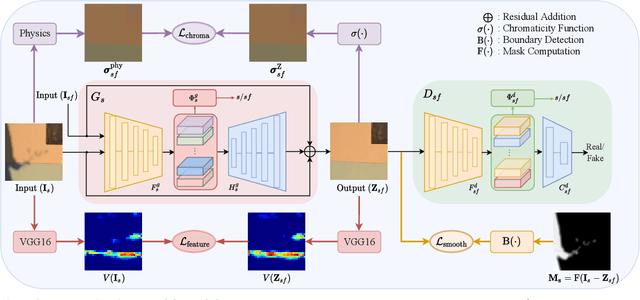
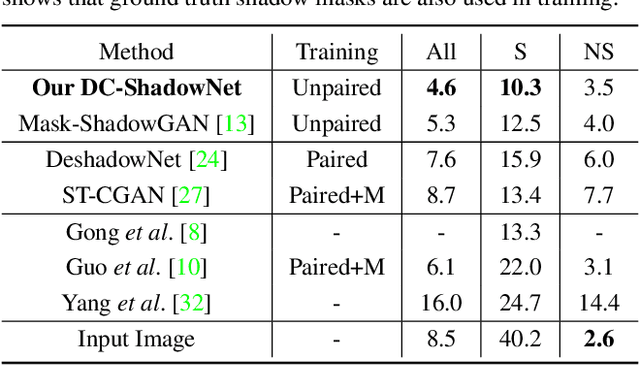
Shadow removal from a single image is generally still an open problem. Most existing learning-based methods use supervised learning and require a large number of paired images (shadow and corresponding non-shadow images) for training. A recent unsupervised method, Mask-ShadowGAN, addresses this limitation. However, it requires a binary mask to represent shadow regions, making it inapplicable to soft shadows. To address the problem, in this paper, we propose an unsupervised domain-classifier guided shadow removal network, DC-ShadowNet. Specifically, we propose to integrate a shadow/shadow-free domain classifier into a generator and its discriminator, enabling them to focus on shadow regions. To train our network, we introduce novel losses based on physics-based shadow-free chromaticity, shadow-robust perceptual features, and boundary smoothness. Moreover, we show that our unsupervised network can be used for test-time training that further improves the results. Our experiments show that all these novel components allow our method to handle soft shadows, and also to perform better on hard shadows both quantitatively and qualitatively than the existing state-of-the-art shadow removal methods.
* Accepted to ICCV2021, https://github.com/jinyeying/DC-ShadowNet-Hard-and-Soft-Shadow-Removal
Feature-Aligned Video Raindrop Removal with Temporal Constraints
May 29, 2022
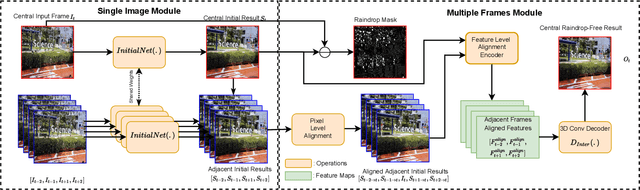
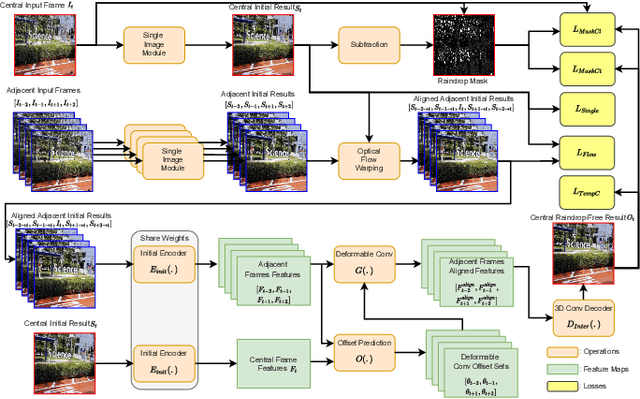

Existing adherent raindrop removal methods focus on the detection of the raindrop locations, and then use inpainting techniques or generative networks to recover the background behind raindrops. Yet, as adherent raindrops are diverse in sizes and appearances, the detection is challenging for both single image and video. Moreover, unlike rain streaks, adherent raindrops tend to cover the same area in several frames. Addressing these problems, our method employs a two-stage video-based raindrop removal method. The first stage is the single image module, which generates initial clean results. The second stage is the multiple frame module, which further refines the initial results using temporal constraints, namely, by utilizing multiple input frames in our process and applying temporal consistency between adjacent output frames. Our single image module employs a raindrop removal network to generate initial raindrop removal results, and create a mask representing the differences between the input and initial output. Once the masks and initial results for consecutive frames are obtained, our multiple-frame module aligns the frames in both the image and feature levels and then obtains the clean background. Our method initially employs optical flow to align the frames, and then utilizes deformable convolution layers further to achieve feature-level frame alignment. To remove small raindrops and recover correct backgrounds, a target frame is predicted from adjacent frames. A series of unsupervised losses are proposed so that our second stage, which is the video raindrop removal module, can self-learn from video data without ground truths. Experimental results on real videos demonstrate the state-of-art performance of our method both quantitatively and qualitatively.