 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGCR: Gradient Coreset Based Replay Buffer Selection For Continual Learning
Nov 18, 2021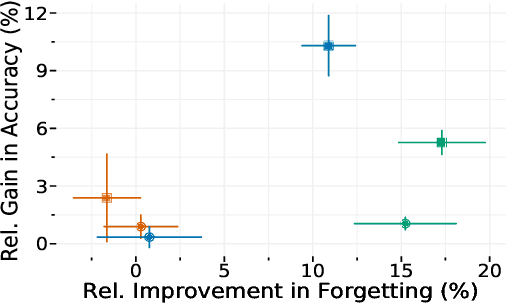
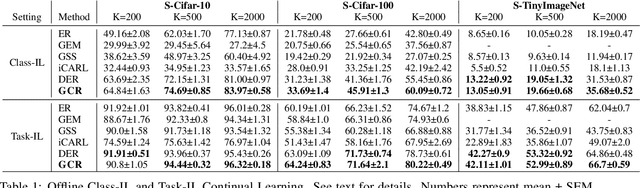
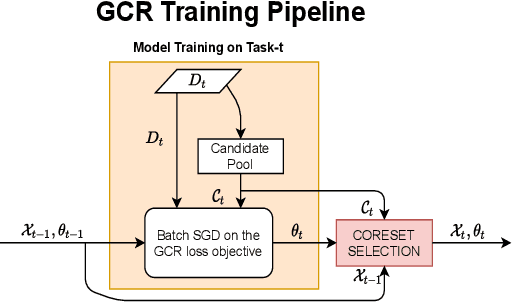

Continual learning (CL) aims to develop techniques by which a single model adapts to an increasing number of tasks encountered sequentially, thereby potentially leveraging learnings across tasks in a resource-efficient manner. A major challenge for CL systems is catastrophic forgetting, where earlier tasks are forgotten while learning a new task. To address this, replay-based CL approaches maintain and repeatedly retrain on a small buffer of data selected across encountered tasks. We propose Gradient Coreset Replay (GCR), a novel strategy for replay buffer selection and update using a carefully designed optimization criterion. Specifically, we select and maintain a "coreset" that closely approximates the gradient of all the data seen so far with respect to current model parameters, and discuss key strategies needed for its effective application to the continual learning setting. We show significant gains (2%-4% absolute) over the state-of-the-art in the well-studied offline continual learning setting. Our findings also effectively transfer to online / streaming CL settings, showing upto 5% gains over existing approaches. Finally, we demonstrate the value of supervised contrastive loss for continual learning, which yields a cumulative gain of up to 5% accuracy when combined with our subset selection strategy.
Personalizing ASR with limited data using targeted subset selection
Oct 29, 2021
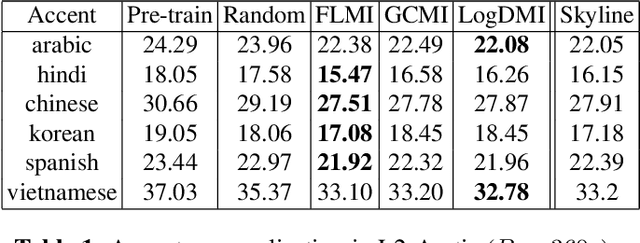
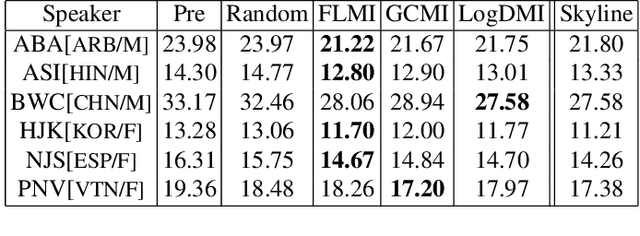
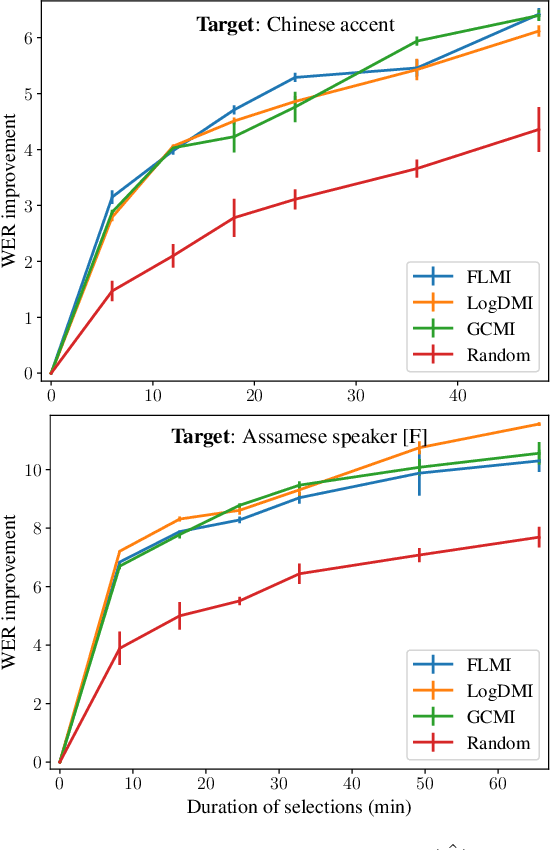
We study the task of personalizing ASR models to a target non-native speaker/accent while being constrained by a transcription budget on the duration of utterances selected from a large unlabelled corpus. We propose a subset selection approach using the recently proposed submodular mutual information functions, in which we identify a diverse set of utterances that match the target speaker/accent. This is specified through a few target utterances and achieved by modeling the relationship between the target subset and the selected subset using submodular mutual information functions. This method is applied at both the speaker and accent levels. We personalize the model by fine tuning it with utterances selected and transcribed from the unlabelled corpus. Our method is able to consistently identify utterances from the target speaker/accent using just speech features. We show that the targeted subset selection approach improves upon random sampling by as much as 2% to 5% (absolute) depending on the speaker and accent and is 2x to 4x more label-efficient compared to random sampling. We also compare with a skyline where we specifically pick from the target and our method generally outperforms the oracle in its selections.
Learning to Robustly Aggregate Labeling Functions for Semi-supervised Data Programming
Sep 23, 2021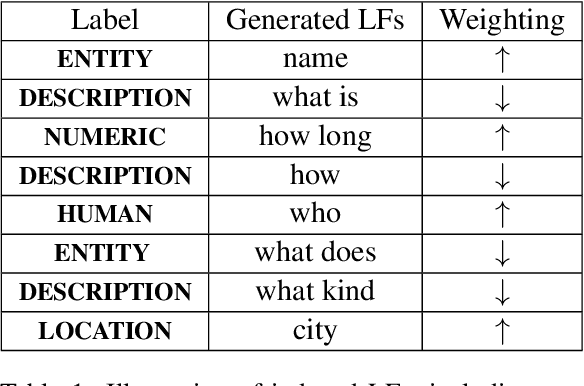
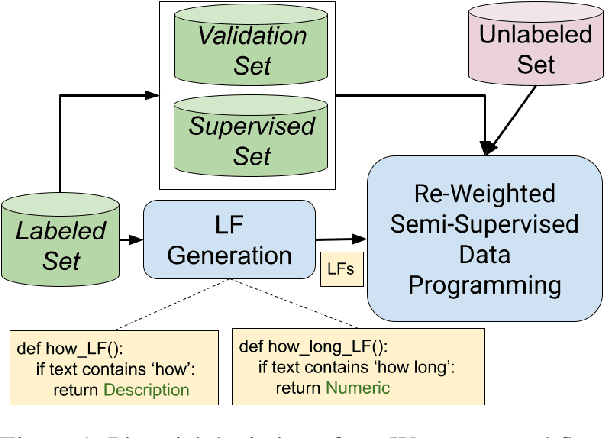
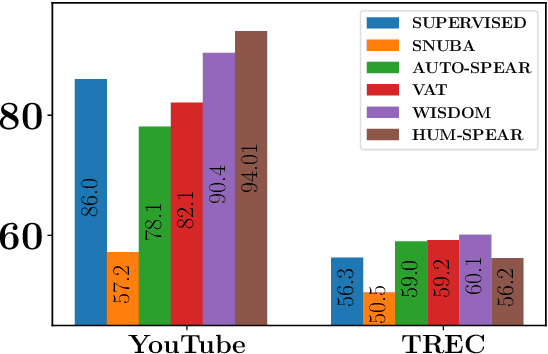
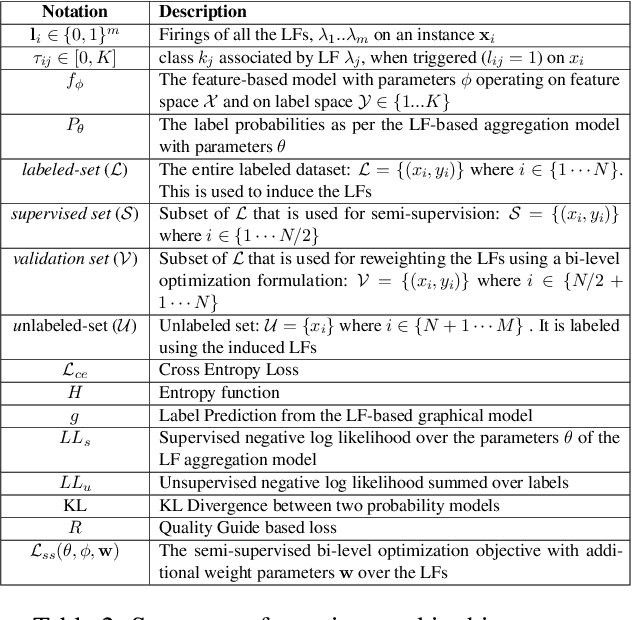
A critical bottleneck in supervised machine learning is the need for large amounts of labeled data which is expensive and time consuming to obtain. However, it has been shown that a small amount of labeled data, while insufficient to re-train a model, can be effectively used to generate human-interpretable labeling functions (LFs). These LFs, in turn, have been used to generate a large amount of additional noisy labeled data, in a paradigm that is now commonly referred to as data programming. However, previous approaches to automatically generate LFs make no attempt to further use the given labeled data for model training, thus giving up opportunities for improved performance. Moreover, since the LFs are generated from a relatively small labeled dataset, they are prone to being noisy, and naively aggregating these LFs can lead to very poor performance in practice. In this work, we propose an LF based reweighting framework \ouralgo{} to solve these two critical limitations. Our algorithm learns a joint model on the (same) labeled dataset used for LF induction along with any unlabeled data in a semi-supervised manner, and more critically, reweighs each LF according to its goodness, influencing its contribution to the semi-supervised loss using a robust bi-level optimization algorithm. We show that our algorithm significantly outperforms prior approaches on several text classification datasets.
SPEAR : Semi-supervised Data Programming in Python
Aug 01, 2021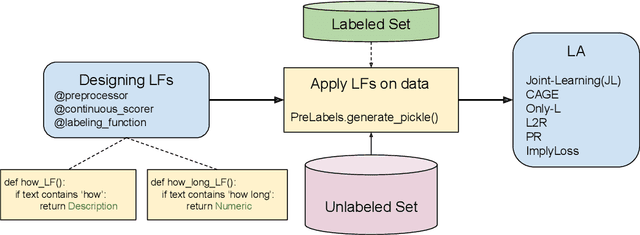

We present SPEAR, an open-source python library for data programming with semi supervision. The package implements several recent data programming approaches including facility to programmatically label and build training data. SPEAR facilitates weak supervision in the form of heuristics (or rules) and association of noisy labels to the training dataset. These noisy labels are aggregated to assign labels to the unlabeled data for downstream tasks. We have implemented several label aggregation approaches that aggregate the noisy labels and then train using the noisily labeled set in a cascaded manner. Our implementation also includes other approaches that jointly aggregate and train the model. Thus, in our python package, we integrate several cascade and joint data-programming approaches while also providing the facility of data programming by letting the user define labeling functions or rules. The code and tutorial notebooks are available at \url{https://github.com/decile-team/spear}.
SIMILAR: Submodular Information Measures Based Active Learning In Realistic Scenarios
Jul 01, 2021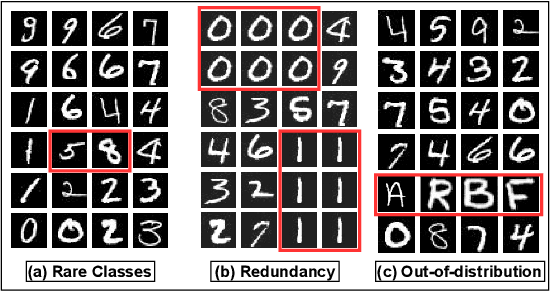

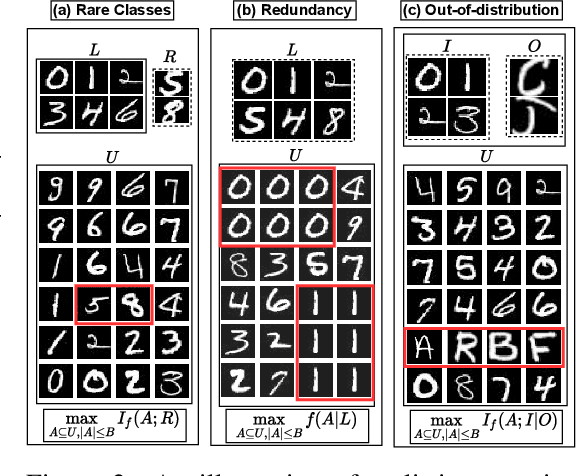
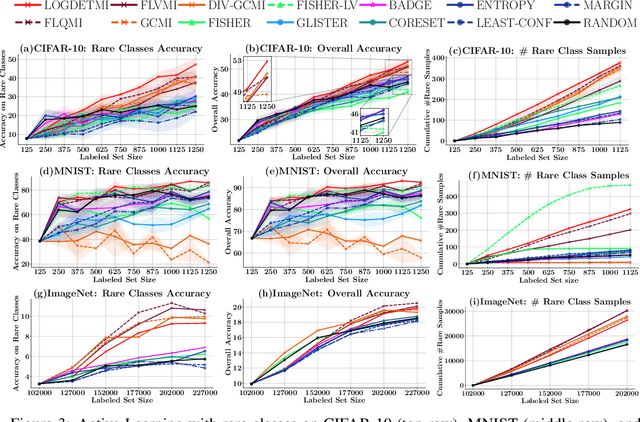
Active learning has proven to be useful for minimizing labeling costs by selecting the most informative samples. However, existing active learning methods do not work well in realistic scenarios such as imbalance or rare classes, out-of-distribution data in the unlabeled set, and redundancy. In this work, we propose SIMILAR (Submodular Information Measures based actIve LeARning), a unified active learning framework using recently proposed submodular information measures (SIM) as acquisition functions. We argue that SIMILAR not only works in standard active learning, but also easily extends to the realistic settings considered above and acts as a one-stop solution for active learning that is scalable to large real-world datasets. Empirically, we show that SIMILAR significantly outperforms existing active learning algorithms by as much as ~5% - 18% in the case of rare classes and ~5% - 10% in the case of out-of-distribution data on several image classification tasks like CIFAR-10, MNIST, and ImageNet.
Effective Evaluation of Deep Active Learning on Image Classification Tasks
Jun 30, 2021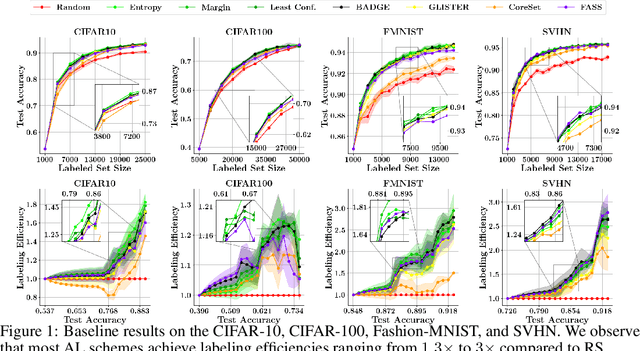
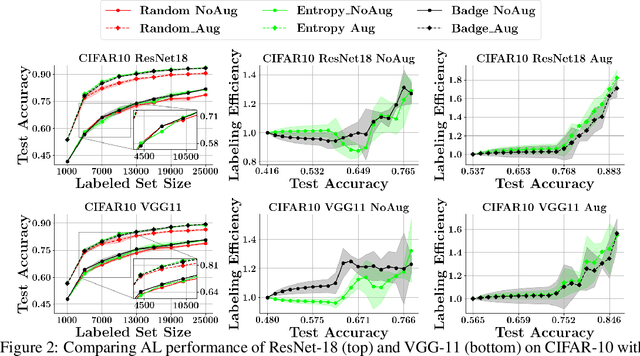
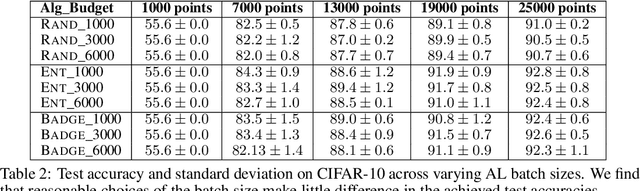
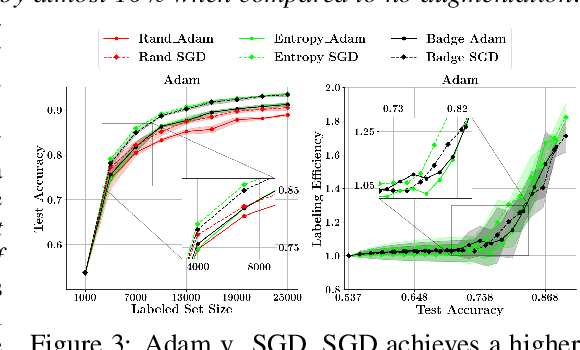
With the goal of making deep learning more label-efficient, a growing number of papers have been studying active learning (AL) for deep models. However, there are a number of issues in the prevalent experimental settings, mainly stemming from a lack of unified implementation and benchmarking. Issues in the current literature include sometimes contradictory observations on the performance of different AL algorithms, unintended exclusion of important generalization approaches such as data augmentation and SGD for optimization, a lack of study of evaluation facets like the labeling efficiency of AL, and little or no clarity on the scenarios in which AL outperforms random sampling (RS). In this work, we present a unified re-implementation of state-of-the-art AL algorithms in the context of image classification, and we carefully study these issues as facets of effective evaluation. On the positive side, we show that AL techniques are 2x to 4x more label-efficient compared to RS with the use of data augmentation. Surprisingly, when data augmentation is included, there is no longer a consistent gain in using BADGE, a state-of-the-art approach, over simple uncertainty sampling. We then do a careful analysis of how existing approaches perform with varying amounts of redundancy and number of examples per class. Finally, we provide several insights for AL practitioners to consider in future work, such as the effect of the AL batch size, the effect of initialization, the importance of retraining a new model at every round, and other insights.
Training Data Subset Selection for Regression with Controlled Generalization Error
Jun 23, 2021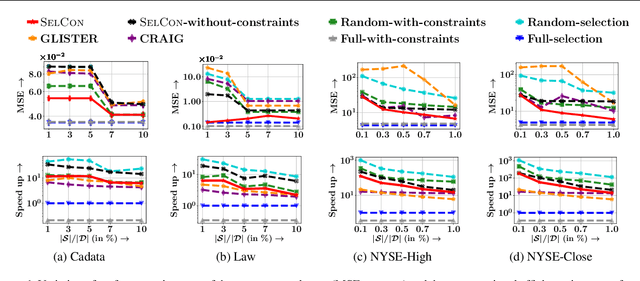
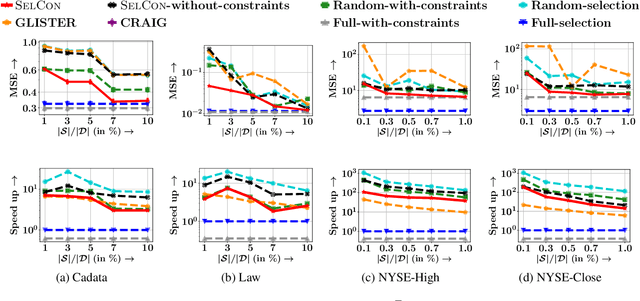
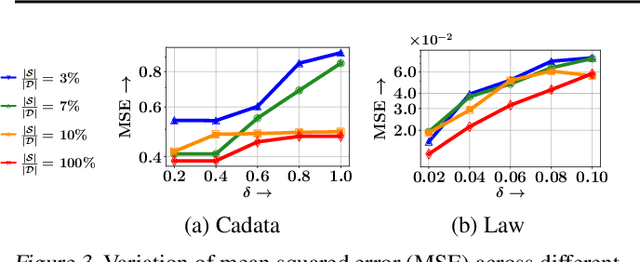
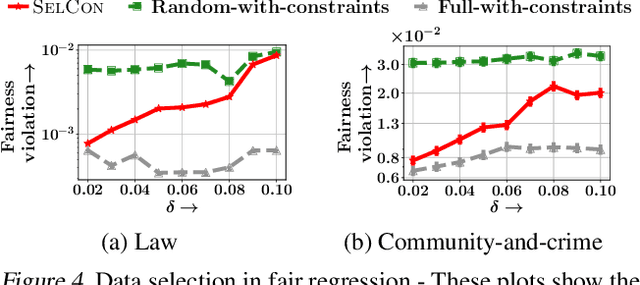
Data subset selection from a large number of training instances has been a successful approach toward efficient and cost-effective machine learning. However, models trained on a smaller subset may show poor generalization ability. In this paper, our goal is to design an algorithm for selecting a subset of the training data, so that the model can be trained quickly, without significantly sacrificing on accuracy. More specifically, we focus on data subset selection for L2 regularized regression problems and provide a novel problem formulation which seeks to minimize the training loss with respect to both the trainable parameters and the subset of training data, subject to error bounds on the validation set. We tackle this problem using several technical innovations. First, we represent this problem with simplified constraints using the dual of the original training problem and show that the objective of this new representation is a monotone and alpha-submodular function, for a wide variety of modeling choices. Such properties lead us to develop SELCON, an efficient majorization-minimization algorithm for data subset selection, that admits an approximation guarantee even when the training provides an imperfect estimate of the trained model. Finally, our experiments on several datasets show that SELCON trades off accuracy and efficiency more effectively than the current state-of-the-art.
RETRIEVE: Coreset Selection for Efficient and Robust Semi-Supervised Learning
Jun 14, 2021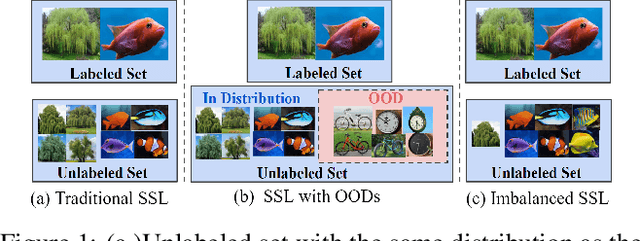
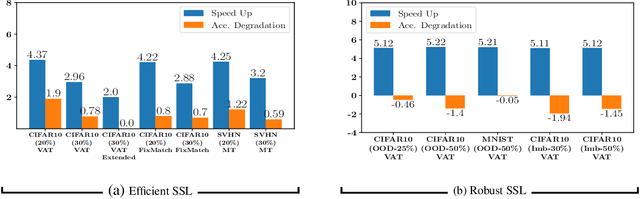


Semi-supervised learning (SSL) algorithms have had great success in recent years in limited labeled data regimes. However, the current state-of-the-art SSL algorithms are computationally expensive and entail significant compute time and energy requirements. This can prove to be a huge limitation for many smaller companies and academic groups. Our main insight is that training on a subset of unlabeled data instead of entire unlabeled data enables the current SSL algorithms to converge faster, thereby reducing the computational costs significantly. In this work, we propose RETRIEVE, a coreset selection framework for efficient and robust semi-supervised learning. RETRIEVE selects the coreset by solving a mixed discrete-continuous bi-level optimization problem such that the selected coreset minimizes the labeled set loss. We use a one-step gradient approximation and show that the discrete optimization problem is approximately submodular, thereby enabling simple greedy algorithms to obtain the coreset. We empirically demonstrate on several real-world datasets that existing SSL algorithms like VAT, Mean-Teacher, FixMatch, when used with RETRIEVE, achieve a) faster training times, b) better performance when unlabeled data consists of Out-of-Distribution(OOD) data and imbalance. More specifically, we show that with minimal accuracy degradation, RETRIEVE achieves a speedup of around 3X in the traditional SSL setting and achieves a speedup of 5X compared to state-of-the-art (SOTA) robust SSL algorithms in the case of imbalance and OOD data.
BiFair: Training Fair Models with Bilevel Optimization
Jun 03, 2021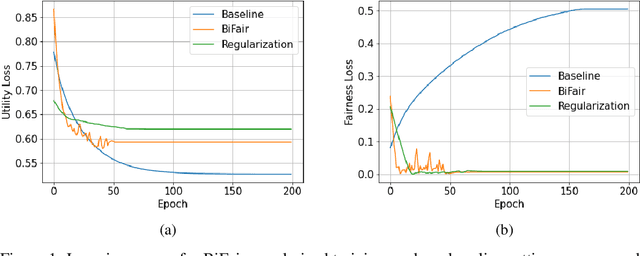
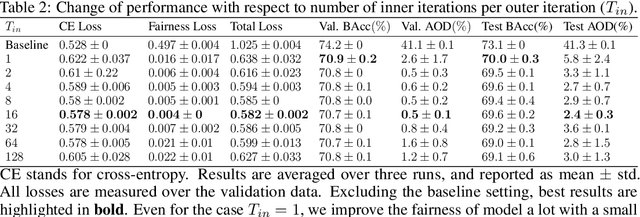
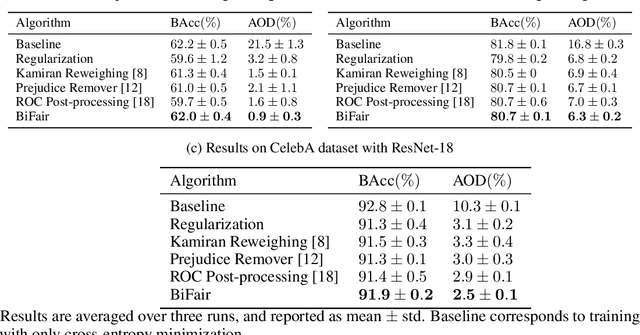
Prior studies have shown that, training machine learning models via empirical loss minimization to maximize a utility metric (e.g., accuracy), might yield models that make discriminatory predictions. To alleviate this issue, we develop a new training algorithm, named BiFair, which jointly minimizes for a utility, and a fairness loss of interest. Crucially, we do so without directly modifying the training objective, e.g., by adding regularization terms. Rather, we learn a set of weights on the training dataset, such that, training on the weighted dataset ensures both good utility, and fairness. The dataset weights are learned in concurrence to the model training, which is done by solving a bilevel optimization problem using a held-out validation dataset. Overall, this approach yields models with better fairness-utility trade-offs. Particularly, we compare our algorithm with three other state-of-the-art fair training algorithms over three real-world datasets, and demonstrate that, BiFair consistently performs better, i.e., we reach to better values of a given fairness metric under same, or higher accuracy. Further, our algorithm is scalable. It is applicable both to simple models, such as logistic regression, as well as more complex models, such as deep neural networks, as evidenced by our experimental analysis.
Rule Augmented Unsupervised Constituency Parsing
May 21, 2021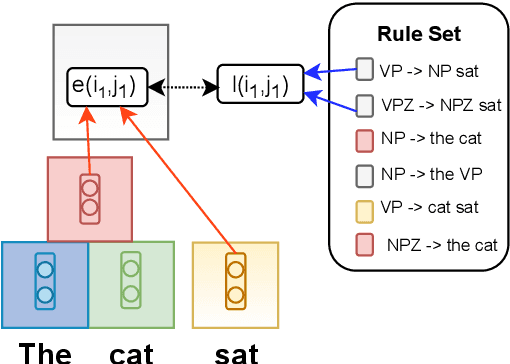
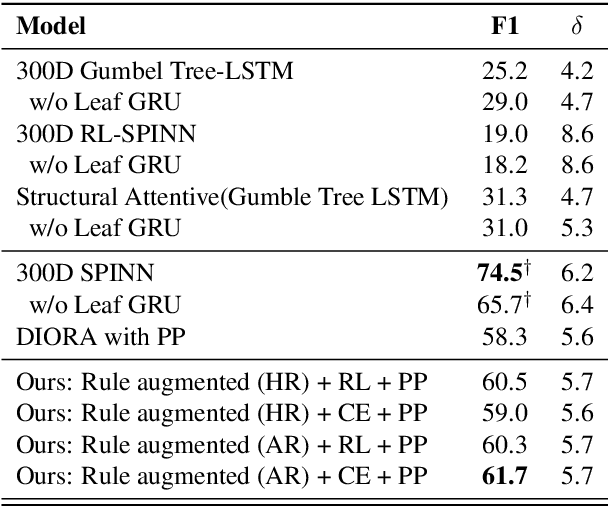
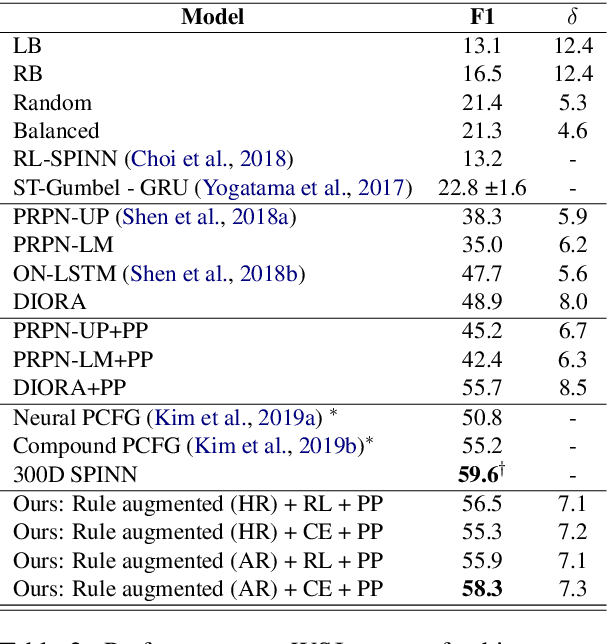
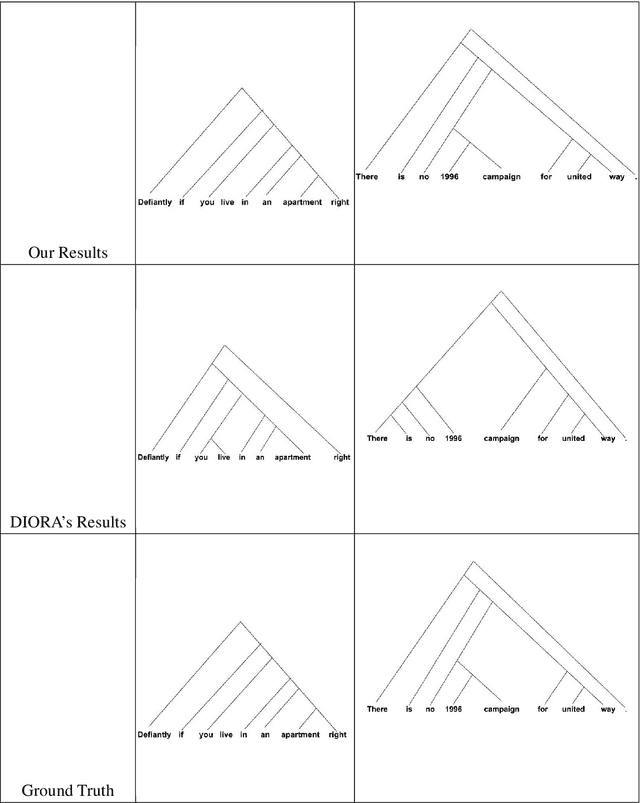
Recently, unsupervised parsing of syntactic trees has gained considerable attention. A prototypical approach to such unsupervised parsing employs reinforcement learning and auto-encoders. However, no mechanism ensures that the learnt model leverages the well-understood language grammar. We propose an approach that utilizes very generic linguistic knowledge of the language present in the form of syntactic rules, thus inducing better syntactic structures. We introduce a novel formulation that takes advantage of the syntactic grammar rules and is independent of the base system. We achieve new state-of-the-art results on two benchmarks datasets, MNLI and WSJ. The source code of the paper is available at https://github.com/anshuln/Diora_with_rules.