 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtracting Summary Knowledge Graphs from Long Documents
Sep 19, 2020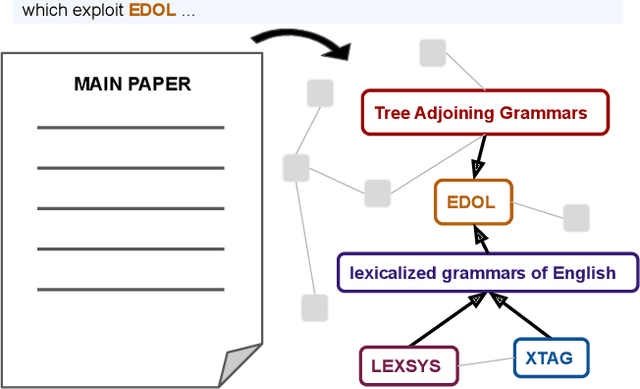
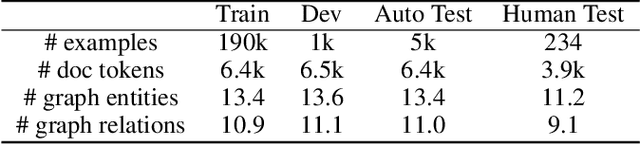

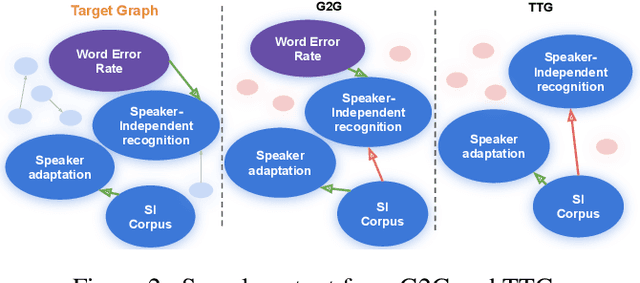
Knowledge graphs capture entities and relations from long documents and can facilitate reasoning in many downstream applications. Extracting compact knowledge graphs containing only salient entities and relations is important but challenging for understanding and summarizing long documents. We introduce a new text-to-graph task of predicting summarized knowledge graphs from long documents. We develop a dataset of 200k document/graph pairs using automatic and human annotations. We also develop strong baselines for this task based on graph learning and text summarization, and provide quantitative and qualitative studies of their effect.
A Controllable Model of Grounded Response Generation
May 01, 2020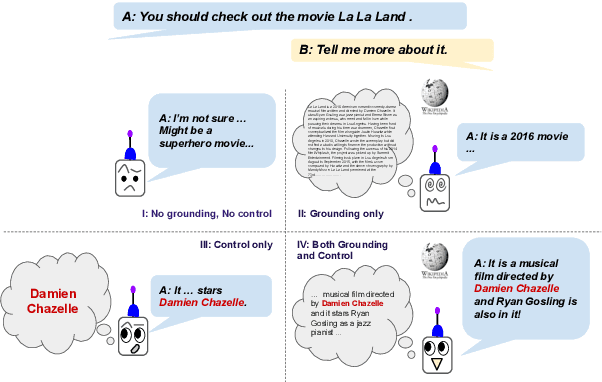
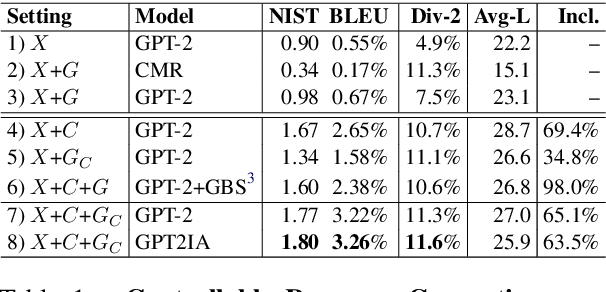
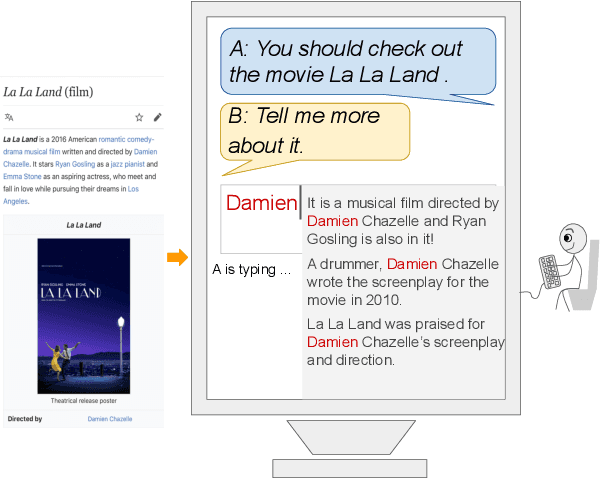
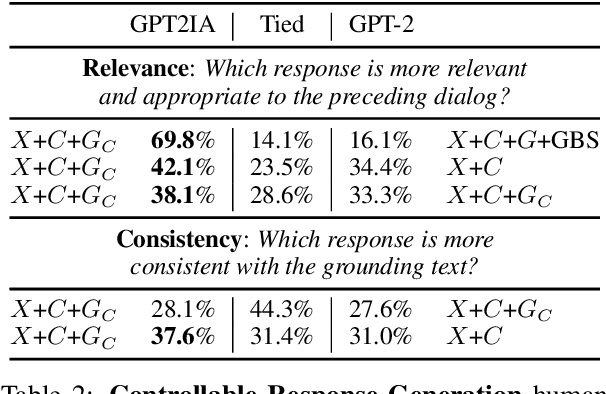
Current end-to-end neural conversation models inherently lack the flexibility to impose semantic control in the response generation process. This control is essential to ensure that users' semantic intents are satisfied and to impose a degree of specificity on generated outputs. Attempts to boost informativeness alone come at the expense of factual accuracy, as attested by GPT-2's propensity to "hallucinate" facts. While this may be mitigated by access to background knowledge, there is scant guarantee of relevance and informativeness in generated responses. We propose a framework that we call controllable grounded response generation (CGRG), in which lexical control phrases are either provided by an user or automatically extracted by a content planner from dialogue context and grounding knowledge. Quantitative and qualitative results show that, using this framework, a GPT-2 based model trained on a conversation-like Reddit dataset outperforms strong generation baselines.
Citation Text Generation
Feb 02, 2020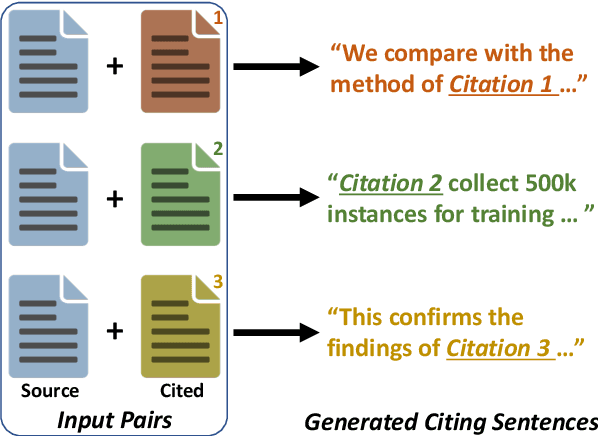
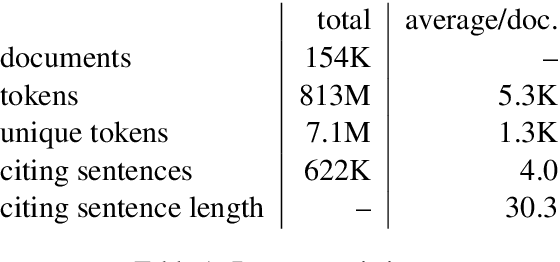
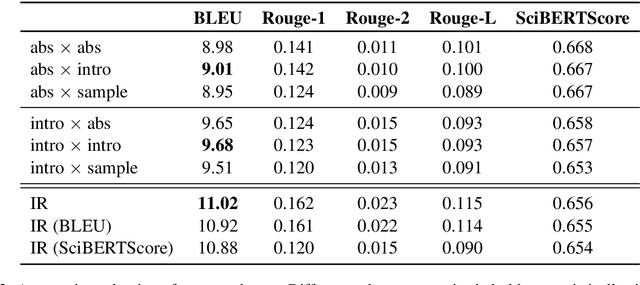
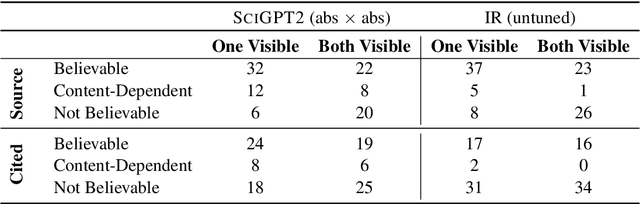
We introduce the task of citation text generation: given a pair of scientific documents, explain their relationship in natural language text in the manner of a citation from one text to the other. This task encourages systems to learn rich relationships between scientific texts and to express them concretely in natural language. Models for citation text generation will require robust document understanding including the capacity to quickly adapt to new vocabulary and to reason about document content. We believe this challenging direction of research will benefit high-impact applications such as automatic literature review or scientific writing assistance systems. In this paper we establish the task of citation text generation with a standard evaluation corpus and explore several baseline models.
DeFINE: DEep Factorized INput Word Embeddings for Neural Sequence Modeling
Nov 27, 2019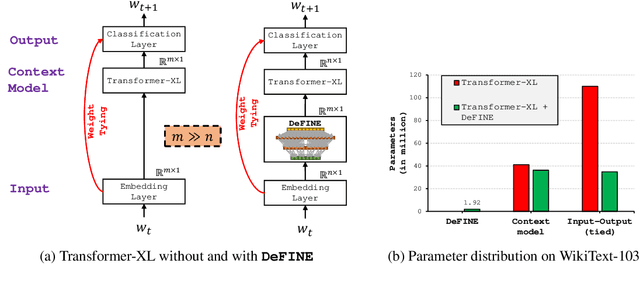
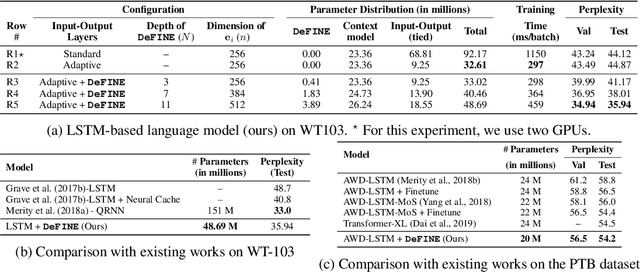
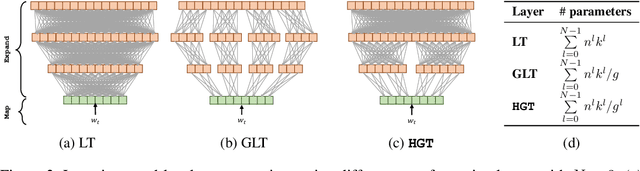
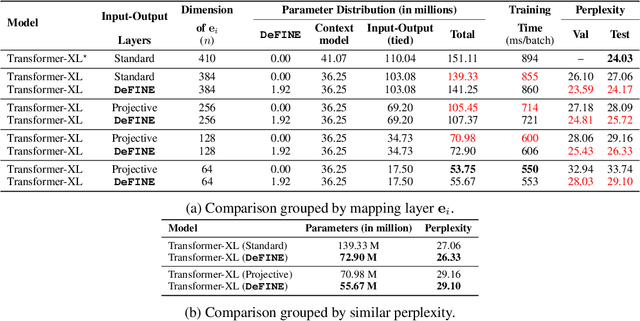
For sequence models with large word-level vocabularies, a majority of network parameters lie in the input and output layers. In this work, we describe a new method, DeFINE, for learning deep word-level representations efficiently. Our architecture uses a hierarchical structure with novel skip-connections which allows for the use of low dimensional input and output layers, reducing total parameters and training time while delivering similar or better performance versus existing methods. DeFINE can be incorporated easily in new or existing sequence models. Compared to state-of-the-art methods including adaptive input representations, this technique results in a 6% to 20% drop in perplexity. On WikiText-103, DeFINE reduces the total parameters of Transformer-XL by half with minimal impact on performance. On the Penn Treebank, DeFINE improves AWD-LSTM by 4 points with a 17% reduction in parameters, achieving comparable performance to state-of-the-art methods with fewer parameters. For machine translation, DeFINE improves the efficiency of the Transformer model by about 1.4 times while delivering similar performance.
MathQA: Towards Interpretable Math Word Problem Solving with Operation-Based Formalisms
May 30, 2019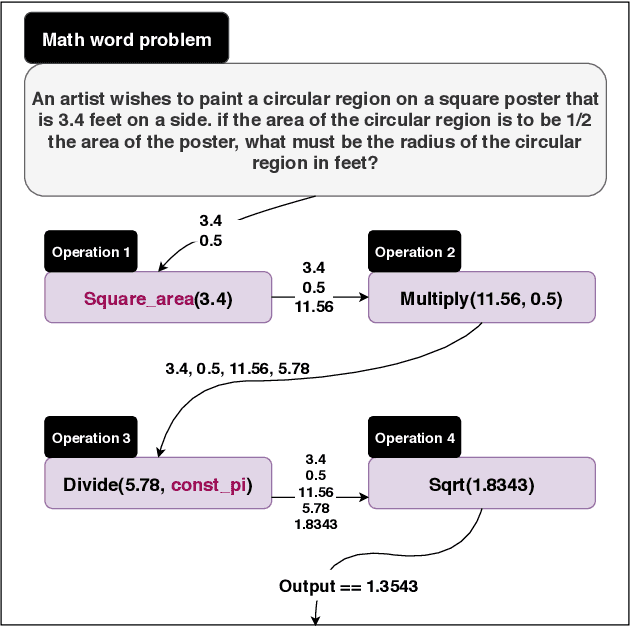
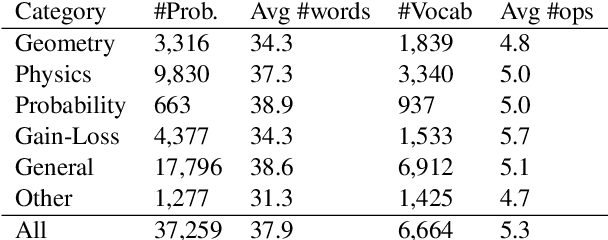

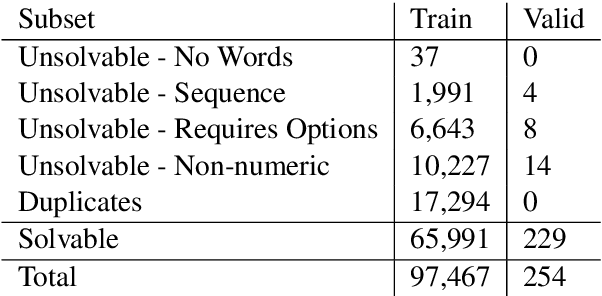
We introduce a large-scale dataset of math word problems and an interpretable neural math problem solver that learns to map problems to operation programs. Due to annotation challenges, current datasets in this domain have been either relatively small in scale or did not offer precise operational annotations over diverse problem types. We introduce a new representation language to model precise operation programs corresponding to each math problem that aim to improve both the performance and the interpretability of the learned models. Using this representation language, our new dataset, MathQA, significantly enhances the AQuA dataset with fully-specified operational programs. We additionally introduce a neural sequence-to-program model enhanced with automatic problem categorization. Our experiments show improvements over competitive baselines in our MathQA as well as the AQuA dataset. The results are still significantly lower than human performance indicating that the dataset poses new challenges for future research. Our dataset is available at: https://math-qa.github.io/math-QA/
Text Generation from Knowledge Graphs with Graph Transformers
May 18, 2019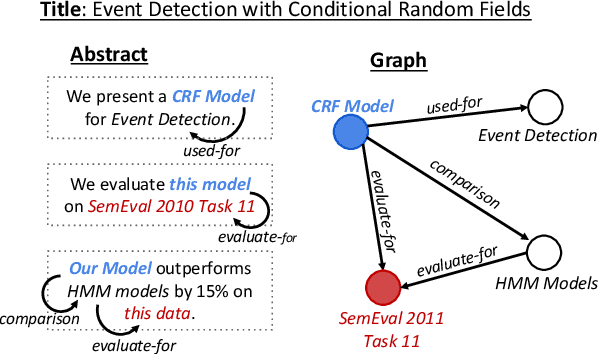
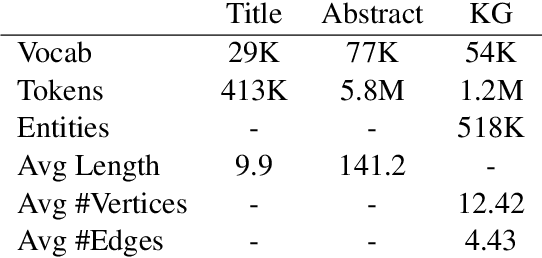
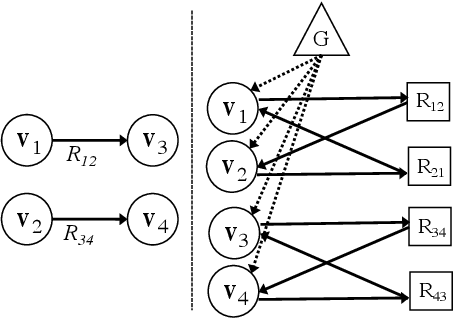

Generating texts which express complex ideas spanning multiple sentences requires a structured representation of their content (document plan), but these representations are prohibitively expensive to manually produce. In this work, we address the problem of generating coherent multi-sentence texts from the output of an information extraction system, and in particular a knowledge graph. Graphical knowledge representations are ubiquitous in computing, but pose a significant challenge for text generation techniques due to their non-hierarchical nature, collapsing of long-distance dependencies, and structural variety. We introduce a novel graph transforming encoder which can leverage the relational structure of such knowledge graphs without imposing linearization or hierarchical constraints. Incorporated into an encoder-decoder setup, we provide an end-to-end trainable system for graph-to-text generation that we apply to the domain of scientific text. Automatic and human evaluations show that our technique produces more informative texts which exhibit better document structure than competitive encoder-decoder methods.
Pyramidal Recurrent Unit for Language Modeling
Aug 27, 2018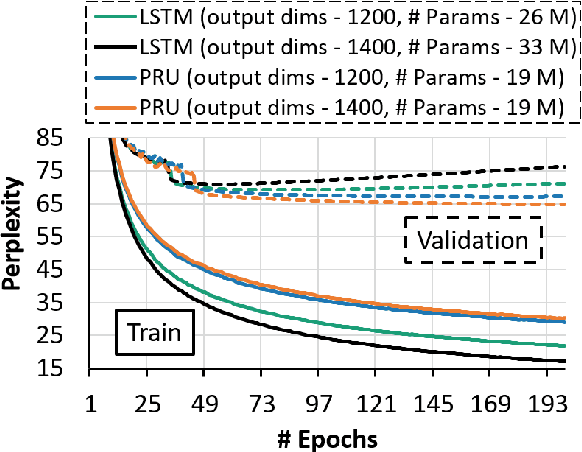
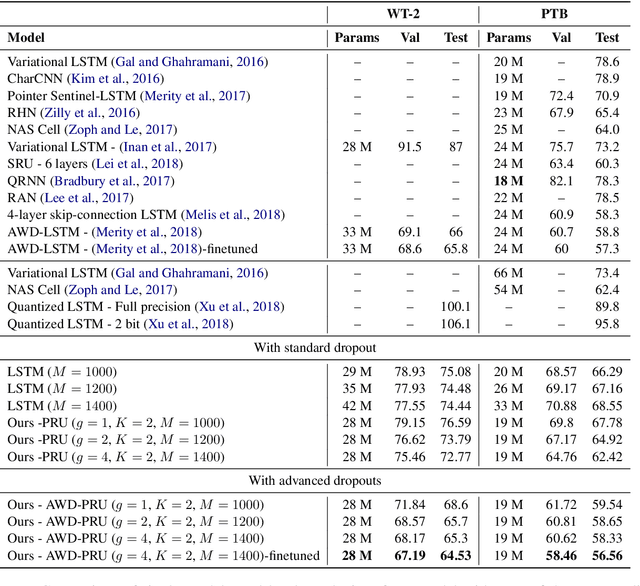
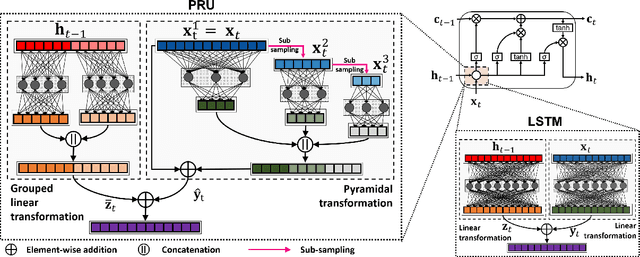
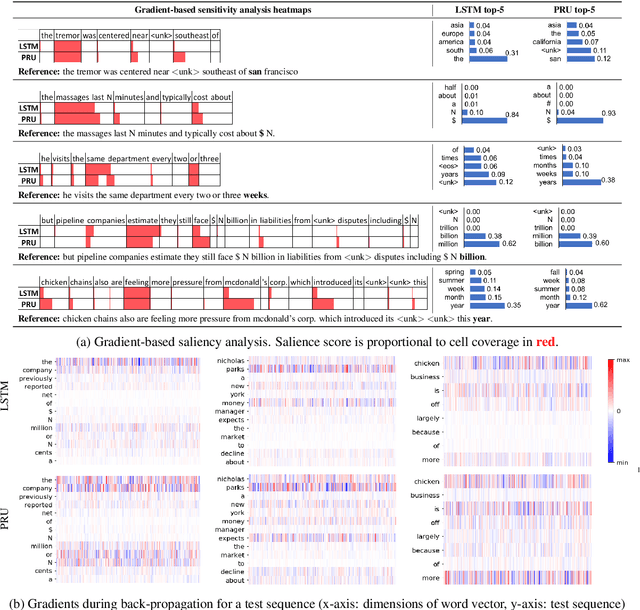
LSTMs are powerful tools for modeling contextual information, as evidenced by their success at the task of language modeling. However, modeling contexts in very high dimensional space can lead to poor generalizability. We introduce the Pyramidal Recurrent Unit (PRU), which enables learning representations in high dimensional space with more generalization power and fewer parameters. PRUs replace the linear transformation in LSTMs with more sophisticated interactions including pyramidal and grouped linear transformations. This architecture gives strong results on word-level language modeling while reducing the number of parameters significantly. In particular, PRU improves the perplexity of a recent state-of-the-art language model Merity et al. (2018) by up to 1.3 points while learning 15-20% fewer parameters. For similar number of model parameters, PRU outperforms all previous RNN models that exploit different gating mechanisms and transformations. We provide a detailed examination of the PRU and its behavior on the language modeling tasks. Our code is open-source and available at https://sacmehta.github.io/PRU/
Data-Driven Methods for Solving Algebra Word Problems
Apr 28, 2018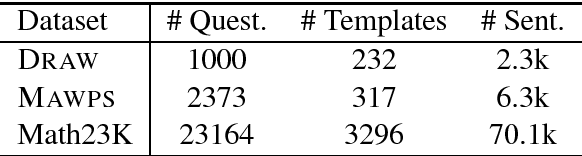
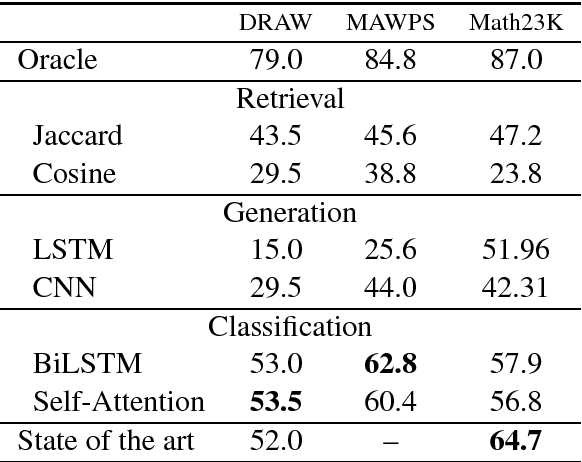
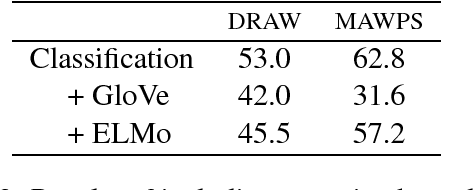

We explore contemporary, data-driven techniques for solving math word problems over recent large-scale datasets. We show that well-tuned neural equation classifiers can outperform more sophisticated models such as sequence to sequence and self-attention across these datasets. Our error analysis indicates that, while fully data driven models show some promise, semantic and world knowledge is necessary for further advances.
A Theme-Rewriting Approach for Generating Algebra Word Problems
Oct 19, 2016
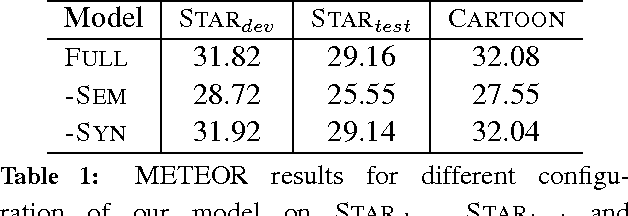
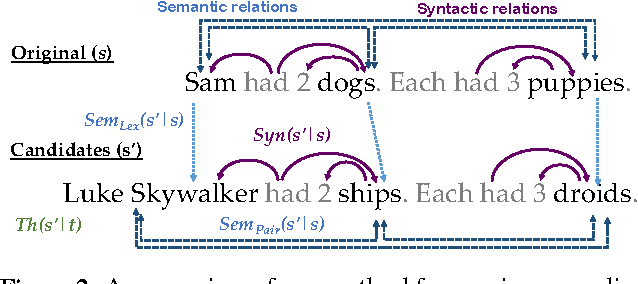
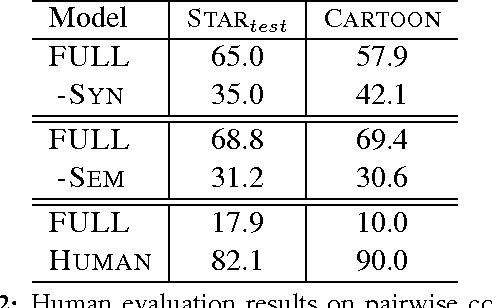
Texts present coherent stories that have a particular theme or overall setting, for example science fiction or western. In this paper, we present a text generation method called {\it rewriting} that edits existing human-authored narratives to change their theme without changing the underlying story. We apply the approach to math word problems, where it might help students stay more engaged by quickly transforming all of their homework assignments to the theme of their favorite movie without changing the math concepts that are being taught. Our rewriting method uses a two-stage decoding process, which proposes new words from the target theme and scores the resulting stories according to a number of factors defining aspects of syntactic, semantic, and thematic coherence. Experiments demonstrate that the final stories typically represent the new theme well while still testing the original math concepts, outperforming a number of baselines. We also release a new dataset of human-authored rewrites of math word problems in several themes.