 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting End-to-End Speech-to-Text Translation From Scratch
Jun 09, 2022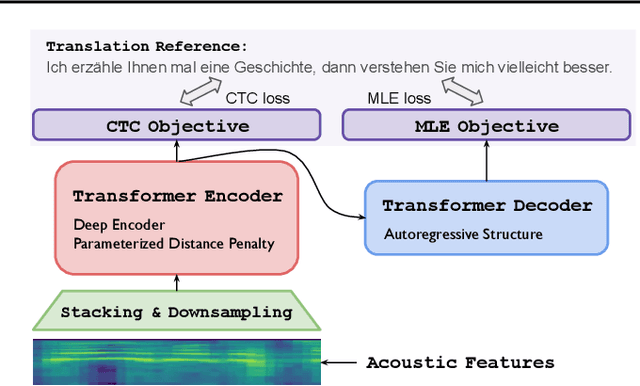
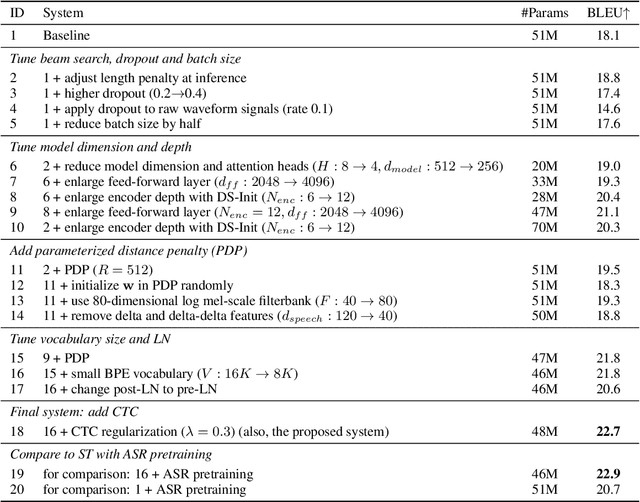
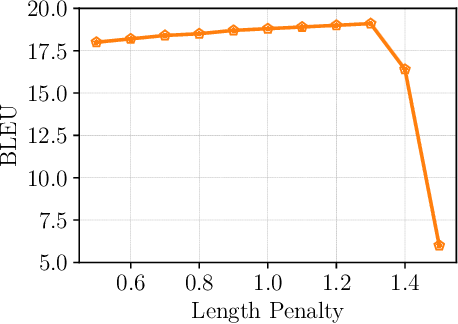
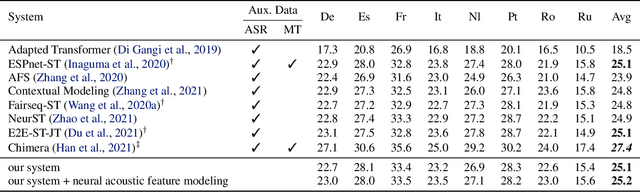
End-to-end (E2E) speech-to-text translation (ST) often depends on pretraining its encoder and/or decoder using source transcripts via speech recognition or text translation tasks, without which translation performance drops substantially. However, transcripts are not always available, and how significant such pretraining is for E2E ST has rarely been studied in the literature. In this paper, we revisit this question and explore the extent to which the quality of E2E ST trained on speech-translation pairs alone can be improved. We reexamine several techniques proven beneficial to ST previously, and offer a set of best practices that biases a Transformer-based E2E ST system toward training from scratch. Besides, we propose parameterized distance penalty to facilitate the modeling of locality in the self-attention model for speech. On four benchmarks covering 23 languages, our experiments show that, without using any transcripts or pretraining, the proposed system reaches and even outperforms previous studies adopting pretraining, although the gap remains in (extremely) low-resource settings. Finally, we discuss neural acoustic feature modeling, where a neural model is designed to extract acoustic features from raw speech signals directly, with the goal to simplify inductive biases and add freedom to the model in describing speech. For the first time, we demonstrate its feasibility and show encouraging results on ST tasks.
NusaX: Multilingual Parallel Sentiment Dataset for 10 Indonesian Local Languages
May 31, 2022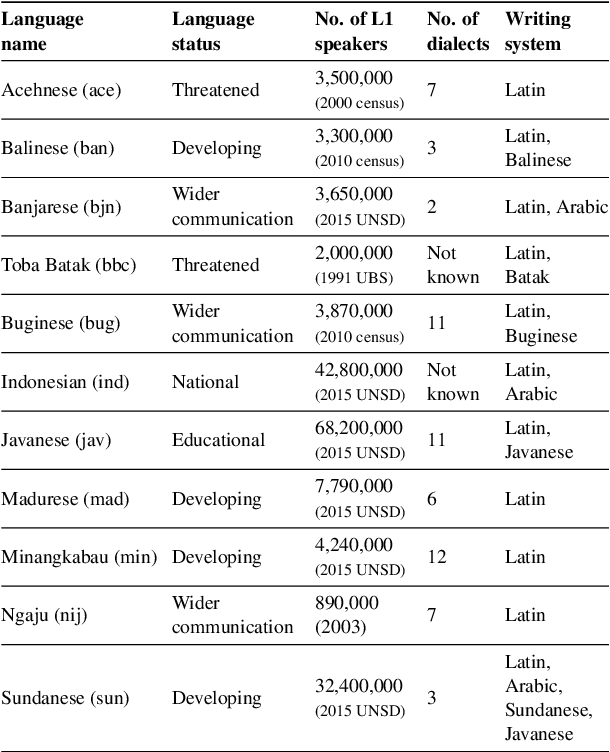
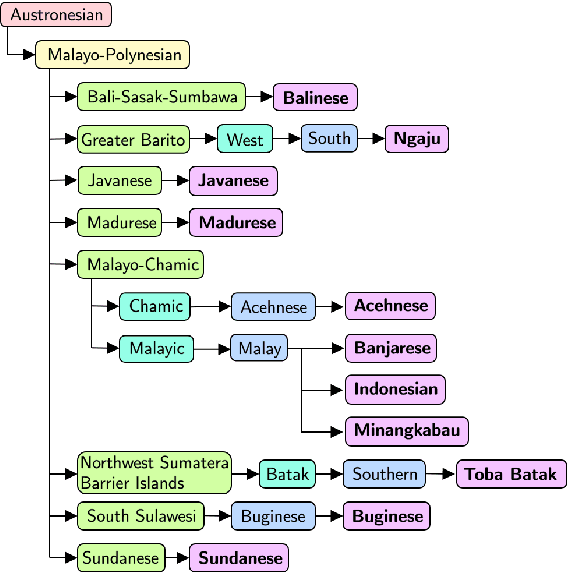
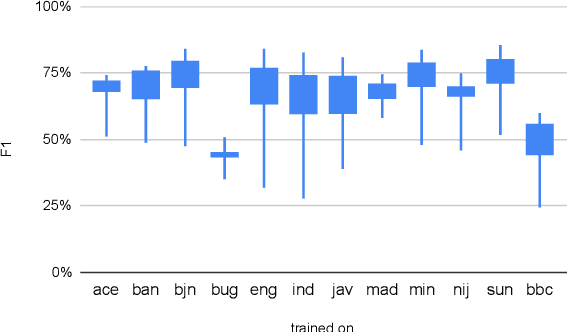
Natural language processing (NLP) has a significant impact on society via technologies such as machine translation and search engines. Despite its success, NLP technology is only widely available for high-resource languages such as English and Chinese, while it remains inaccessible to many languages due to the unavailability of data resources and benchmarks. In this work, we focus on developing resources for languages in Indonesia. Despite being the second most linguistically diverse country, most languages in Indonesia are categorized as endangered and some are even extinct. We develop the first-ever parallel resource for 10 low-resource languages in Indonesia. Our resource includes datasets, a multi-task benchmark, and lexicons, as well as a parallel Indonesian-English dataset. We provide extensive analyses and describe the challenges when creating such resources. We hope that our work can spark NLP research on Indonesian and other underrepresented languages.
NMTScore: A Multilingual Analysis of Translation-based Text Similarity Measures
Apr 28, 2022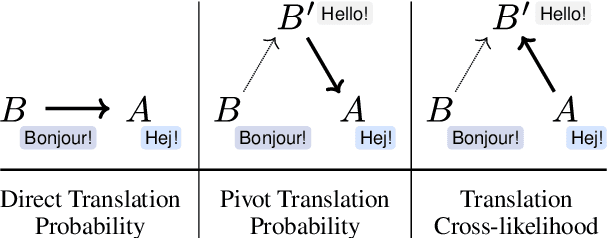
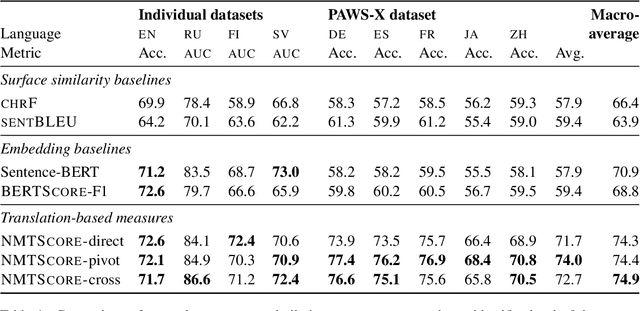
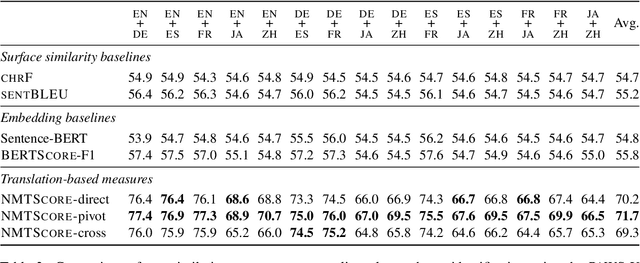
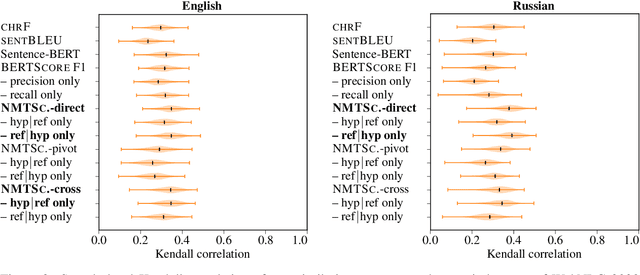
Being able to rank the similarity of short text segments is an interesting bonus feature of neural machine translation. Translation-based similarity measures include direct and pivot translation probability, as well as translation cross-likelihood, which has not been studied so far. We analyze these measures in the common framework of multilingual NMT, releasing the NMTScore library (available at https://github.com/ZurichNLP/nmtscore). Compared to baselines such as sentence embeddings, translation-based measures prove competitive in paraphrase identification and are more robust against adversarial or multilingual input, especially if proper normalization is applied. When used for reference-based evaluation of data-to-text generation in 2 tasks and 17 languages, translation-based measures show a relatively high correlation to human judgments.
As Little as Possible, as Much as Necessary: Detecting Over- and Undertranslations with Contrastive Conditioning
Mar 03, 2022
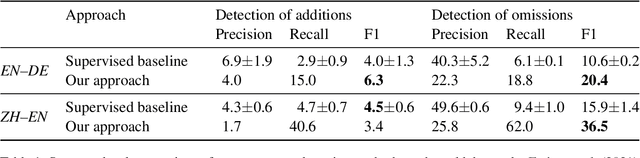
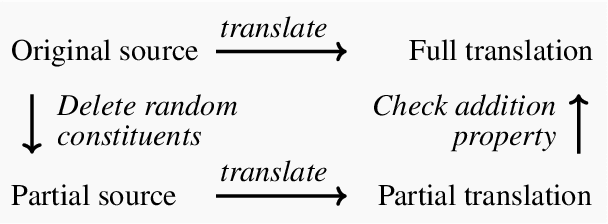
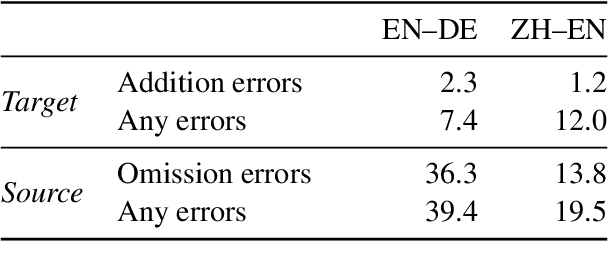
Omission and addition of content is a typical issue in neural machine translation. We propose a method for detecting such phenomena with off-the-shelf translation models. Using contrastive conditioning, we compare the likelihood of a full sequence under a translation model to the likelihood of its parts, given the corresponding source or target sequence. This allows to pinpoint superfluous words in the translation and untranslated words in the source even in the absence of a reference translation. The accuracy of our method is comparable to a supervised method that requires a custom quality estimation model.
Identifying Weaknesses in Machine Translation Metrics Through Minimum Bayes Risk Decoding: A Case Study for COMET
Feb 10, 2022
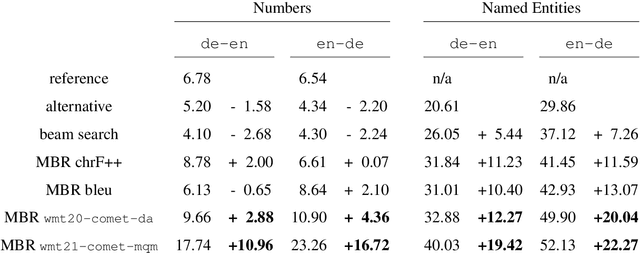
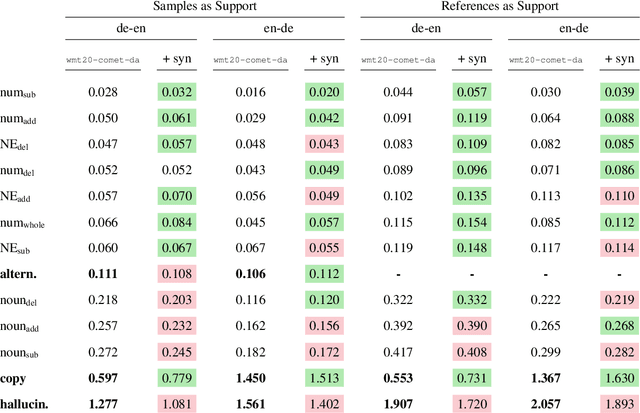

Neural metrics have achieved impressive correlation with human judgements in the evaluation of machine translation systems, but before we can safely optimise towards such metrics, we should be aware of (and ideally eliminate) biases towards bad translations that receive high scores. Our experiments show that sample-based Minimum Bayes Risk decoding can be used to explore and quantify such weaknesses. When applying this strategy to COMET for en-de and de-en, we find that COMET models are not sensitive enough to discrepancies in numbers and named entities. We further show that these biases cannot be fully removed by simply training on additional synthetic data.
Distributionally Robust Recurrent Decoders with Random Network Distillation
Oct 25, 2021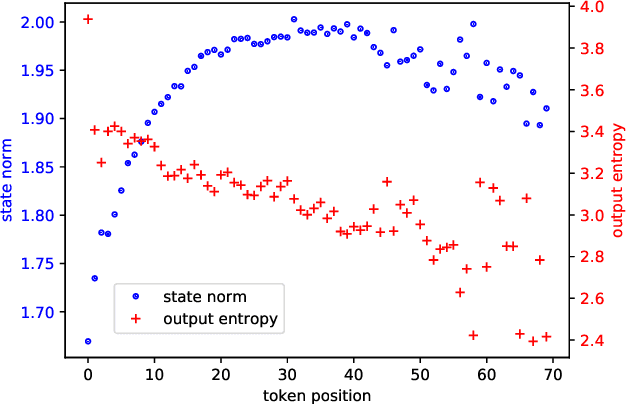
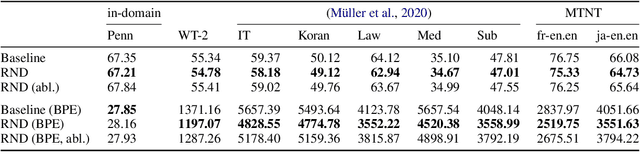
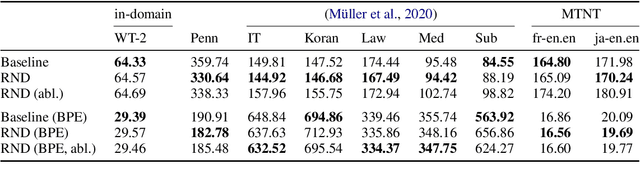
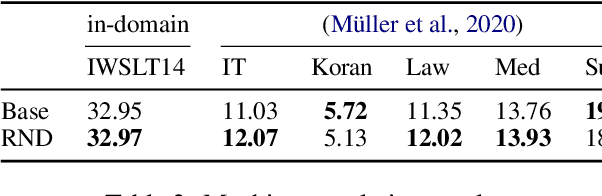
Neural machine learning models can successfully model language that is similar to their training distribution, but they are highly susceptible to degradation under distribution shift, which occurs in many practical applications when processing out-of-domain (OOD) text. This has been attributed to "shortcut learning": relying on weak correlations over arbitrary large contexts. We propose a method based on OOD detection with Random Network Distillation to allow an autoregressive language model to automatically disregard OOD context during inference, smoothly transitioning towards a less expressive but more robust model as the data becomes more OOD while retaining its full context capability when operating in-distribution. We apply our method to a GRU architecture, demonstrating improvements on multiple language modeling (LM) datasets.
On the Limits of Minimal Pairs in Contrastive Evaluation
Sep 15, 2021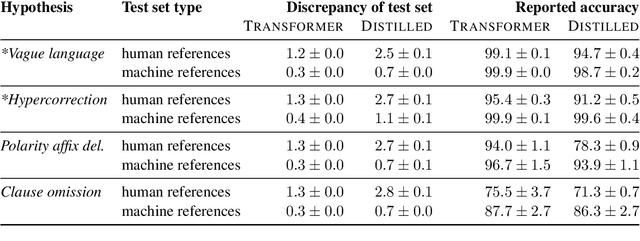
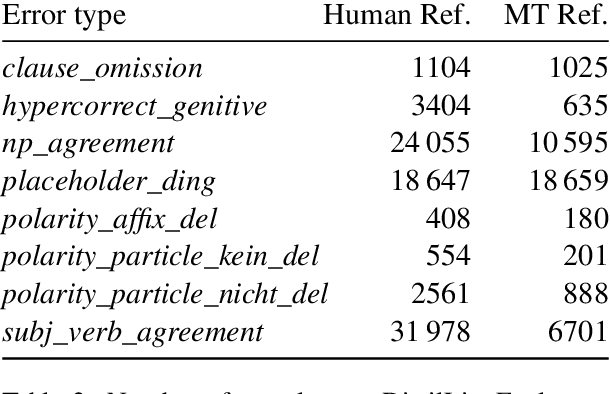
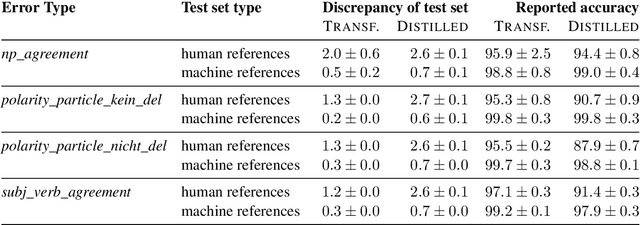

Minimal sentence pairs are frequently used to analyze the behavior of language models. It is often assumed that model behavior on contrastive pairs is predictive of model behavior at large. We argue that two conditions are necessary for this assumption to hold: First, a tested hypothesis should be well-motivated, since experiments show that contrastive evaluation can lead to false positives. Secondly, test data should be chosen such as to minimize distributional discrepancy between evaluation time and deployment time. For a good approximation of deployment-time decoding, we recommend that minimal pairs are created based on machine-generated text, as opposed to human-written references. We present a contrastive evaluation suite for English-German MT that implements this recommendation.
Improving Zero-shot Cross-lingual Transfer between Closely Related Languages by injecting Character-level Noise
Sep 14, 2021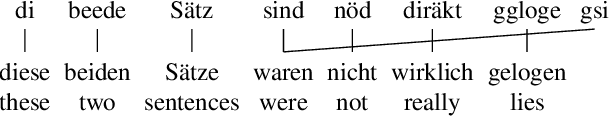
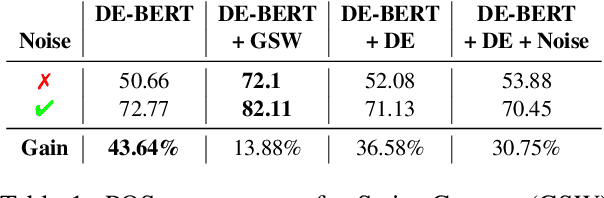
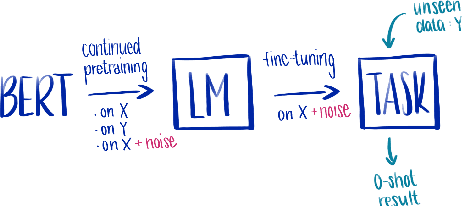
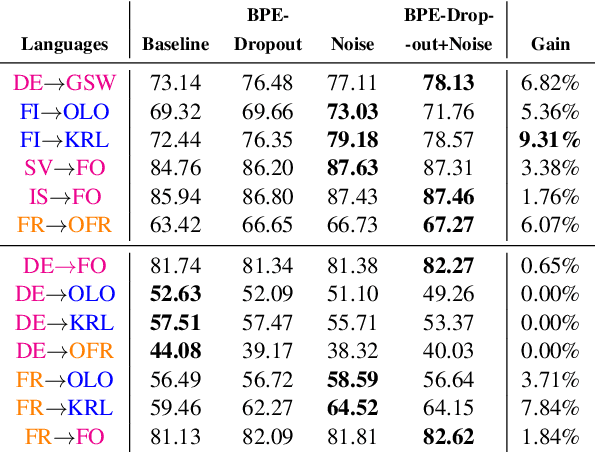
Cross-lingual transfer between a high-resource language and its dialects or closely related language varieties should be facilitated by their similarity, but current approaches that operate in the embedding space do not take surface similarity into account. In this work, we present a simple yet effective strategy to improve cross-lingual transfer between closely related varieties by augmenting the data of the high-resource parent language with character-level noise to make the model more robust towards spelling variations. Our strategy shows consistent improvements over several languages and tasks: Zero-shot transfer of POS tagging and topic identification between language varieties from the Germanic, Uralic, and Romance language genera. Our work provides evidence for the usefulness of simple surface-level noise in improving transfer between language varieties.
Vision Matters When It Should: Sanity Checking Multimodal Machine Translation Models
Sep 08, 2021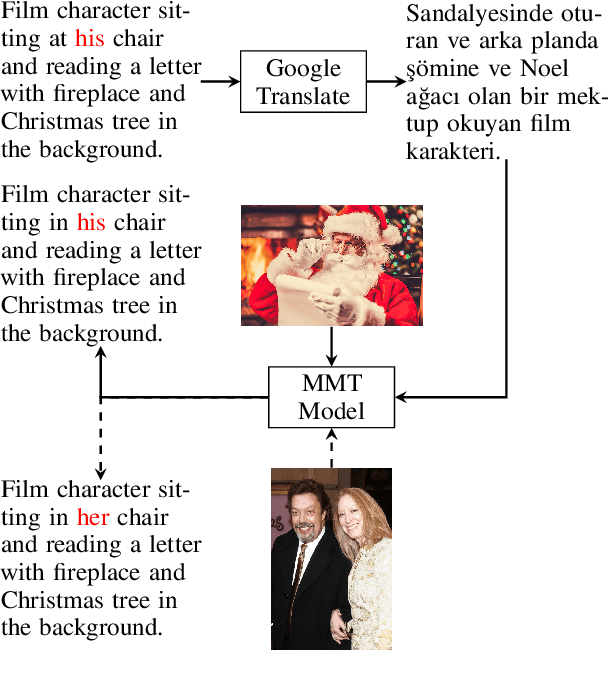
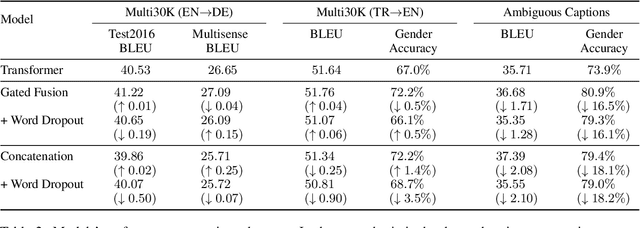
Multimodal machine translation (MMT) systems have been shown to outperform their text-only neural machine translation (NMT) counterparts when visual context is available. However, recent studies have also shown that the performance of MMT models is only marginally impacted when the associated image is replaced with an unrelated image or noise, which suggests that the visual context might not be exploited by the model at all. We hypothesize that this might be caused by the nature of the commonly used evaluation benchmark, also known as Multi30K, where the translations of image captions were prepared without actually showing the images to human translators. In this paper, we present a qualitative study that examines the role of datasets in stimulating the leverage of visual modality and we propose methods to highlight the importance of visual signals in the datasets which demonstrate improvements in reliance of models on the source images. Our findings suggest the research on effective MMT architectures is currently impaired by the lack of suitable datasets and careful consideration must be taken in creation of future MMT datasets, for which we also provide useful insights.
Language Modeling, Lexical Translation, Reordering: The Training Process of NMT through the Lens of Classical SMT
Sep 03, 2021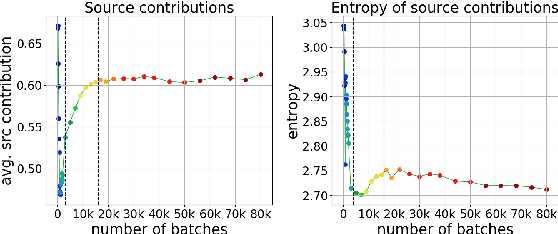
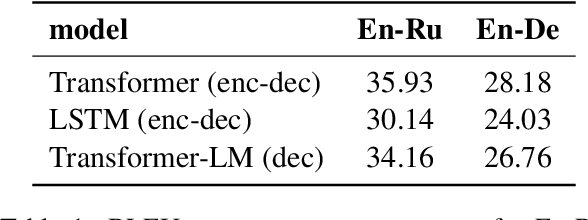
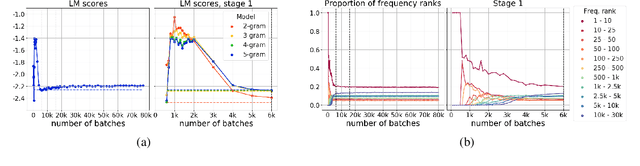

Differently from the traditional statistical MT that decomposes the translation task into distinct separately learned components, neural machine translation uses a single neural network to model the entire translation process. Despite neural machine translation being de-facto standard, it is still not clear how NMT models acquire different competences over the course of training, and how this mirrors the different models in traditional SMT. In this work, we look at the competences related to three core SMT components and find that during training, NMT first focuses on learning target-side language modeling, then improves translation quality approaching word-by-word translation, and finally learns more complicated reordering patterns. We show that this behavior holds for several models and language pairs. Additionally, we explain how such an understanding of the training process can be useful in practice and, as an example, show how it can be used to improve vanilla non-autoregressive neural machine translation by guiding teacher model selection.