 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsed Car Salesbots? Honesty and Credulity of LLMs as Bargaining Agents under Partial Information
May 29, 2026In this work we study agents in simulated bargaining scenarios, where a buyer and a seller communicate through a text channel and attempt to negotiate mutually beneficial trades, under different information regimes (complete information, information asymmetry or mutual uncertainty). We evaluate their performance w.r.t. game-theoretical solutions and further investigate their honesty (their tendency to disclose or withhold information or to mislead and deceive) as well as their credulity (their tendency to trust or distrust information provided by the other agent). We study zero-shot LLM agents with simple prompting scaffolding as well as fine-tuned agents, in order to investigate whether optimising the agents to maximise financial profits makes them stronger negotiators but also more dishonest and less trusting. We find that off-the-shelf LLMs all substantially deviate from game-theoretical equilibria, they attempt to lie about their private information but cannot efficiently exploit information asymmetries. Fine-tuning on financial utility makes the agents stronger at achieving better deals but also more dishonest, highlighting the risks that optimising agents for a task can have on their safety. We release our code and a dataset of bargaining scenarios.
Program Semantic Inequivalence Game with Large Language Models
May 02, 2025Large Language Models (LLMs) can achieve strong performance on everyday coding tasks, but they can fail on complex tasks that require non-trivial reasoning about program semantics. Finding training examples to teach LLMs to solve these tasks can be challenging. In this work, we explore a method to synthetically generate code reasoning training data based on a semantic inequivalence game SInQ: a generator agent creates program variants that are semantically distinct, derived from a dataset of real-world programming tasks, while an evaluator agent has to identify input examples that cause the original programs and the generated variants to diverge in their behaviour, with the agents training each other semi-adversarially. We prove that this setup enables theoretically unlimited improvement through self-play in the limit of infinite computational resources. We evaluated our approach on multiple code generation and understanding benchmarks, including cross-language vulnerability detection (Lu et al., 2021), where our method improves vulnerability detection in C/C++ code despite being trained exclusively on Python code, and the challenging Python builtin identifier swap benchmark (Miceli-Barone et al., 2023), showing that whereas modern LLMs still struggle with this benchmark, our approach yields substantial improvements. We release the code needed to replicate the experiments, as well as the generated synthetic data, which can be used to fine-tune LLMs.
Generating Driving Simulations via Conversation
Oct 13, 2024Cyber-physical systems like autonomous vehicles are tested in simulation before deployment, using domain-specific programs for scenario specification. To aid the testing of autonomous vehicles in simulation, we design a natural language interface, using an instruction-following large language model, to assist a non-coding domain expert in synthesising the desired scenarios and vehicle behaviours. We show that using it to convert utterances to the symbolic program is feasible, despite the very small training dataset. Human experiments show that dialogue is critical to successful simulation generation, leading to a 4.5 times higher success rate than a generation without engaging in extended conversation.
A test suite of prompt injection attacks for LLM-based machine translation
Oct 07, 2024LLM-based NLP systems typically work by embedding their input data into prompt templates which contain instructions and/or in-context examples, creating queries which are submitted to a LLM, and then parsing the LLM response in order to generate the system outputs. Prompt Injection Attacks (PIAs) are a type of subversion of these systems where a malicious user crafts special inputs which interfere with the prompt templates, causing the LLM to respond in ways unintended by the system designer. Recently, Sun and Miceli-Barone proposed a class of PIAs against LLM-based machine translation. Specifically, the task is to translate questions from the TruthfulQA test suite, where an adversarial prompt is prepended to the questions, instructing the system to ignore the translation instruction and answer the questions instead. In this test suite, we extend this approach to all the language pairs of the WMT 2024 General Machine Translation task. Moreover, we include additional attack formats in addition to the one originally studied.
Scaling Behavior of Machine Translation with Large Language Models under Prompt Injection Attacks
Mar 14, 2024Large Language Models (LLMs) are increasingly becoming the preferred foundation platforms for many Natural Language Processing tasks such as Machine Translation, owing to their quality often comparable to or better than task-specific models, and the simplicity of specifying the task through natural language instructions or in-context examples. Their generality, however, opens them up to subversion by end users who may embed into their requests instructions that cause the model to behave in unauthorized and possibly unsafe ways. In this work we study these Prompt Injection Attacks (PIAs) on multiple families of LLMs on a Machine Translation task, focusing on the effects of model size on the attack success rates. We introduce a new benchmark data set and we discover that on multiple language pairs and injected prompts written in English, larger models under certain conditions may become more susceptible to successful attacks, an instance of the Inverse Scaling phenomenon (McKenzie et al., 2023). To our knowledge, this is the first work to study non-trivial LLM scaling behaviour in a multi-lingual setting.
Dialogue-based generation of self-driving simulation scenarios using Large Language Models
Oct 26, 2023



Simulation is an invaluable tool for developing and evaluating controllers for self-driving cars. Current simulation frameworks are driven by highly-specialist domain specific languages, and so a natural language interface would greatly enhance usability. But there is often a gap, consisting of tacit assumptions the user is making, between a concise English utterance and the executable code that captures the user's intent. In this paper we describe a system that addresses this issue by supporting an extended multimodal interaction: the user can follow up prior instructions with refinements or revisions, in reaction to the simulations that have been generated from their utterances so far. We use Large Language Models (LLMs) to map the user's English utterances in this interaction into domain-specific code, and so we explore the extent to which LLMs capture the context sensitivity that's necessary for computing the speaker's intended message in discourse.
Knowledge Base Question Answering for Space Debris Queries
May 31, 2023



Space agencies execute complex satellite operations that need to be supported by the technical knowledge contained in their extensive information systems. Knowledge bases (KB) are an effective way of storing and accessing such information at scale. In this work we present a system, developed for the European Space Agency (ESA), that can answer complex natural language queries, to support engineers in accessing the information contained in a KB that models the orbital space debris environment. Our system is based on a pipeline which first generates a sequence of basic database operations, called a %program sketch, from a natural language question, then specializes the sketch into a concrete query program with mentions of entities, attributes and relations, and finally executes the program against the database. This pipeline decomposition approach enables us to train the system by leveraging out-of-domain data and semi-synthetic data generated by GPT-3, thus reducing overfitting and shortcut learning even with limited amount of in-domain training data. Our code can be found at \url{https://github.com/PaulDrm/DISCOSQA}.
The Larger They Are, the Harder They Fail: Language Models do not Recognize Identifier Swaps in Python
May 24, 2023



Large Language Models (LLMs) have successfully been applied to code generation tasks, raising the question of how well these models understand programming. Typical programming languages have invariances and equivariances in their semantics that human programmers intuitively understand and exploit, such as the (near) invariance to the renaming of identifiers. We show that LLMs not only fail to properly generate correct Python code when default function names are swapped, but some of them even become more confident in their incorrect predictions as the model size increases, an instance of the recently discovered phenomenon of Inverse Scaling, which runs contrary to the commonly observed trend of increasing prediction quality with increasing model size. Our findings indicate that, despite their astonishing typical-case performance, LLMs still lack a deep, abstract understanding of the content they manipulate, making them unsuitable for tasks that statistically deviate from their training data, and that mere scaling is not enough to achieve such capability.
Distributionally Robust Recurrent Decoders with Random Network Distillation
Oct 25, 2021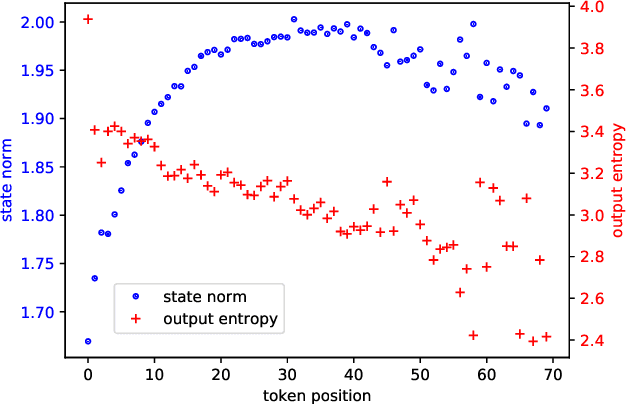
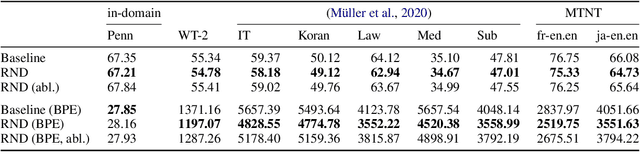
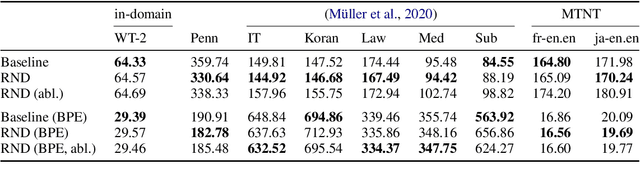
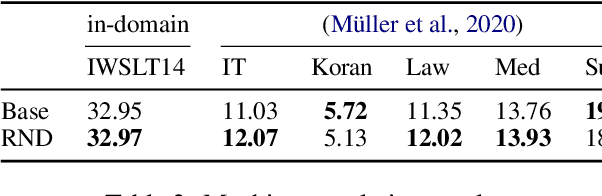
Neural machine learning models can successfully model language that is similar to their training distribution, but they are highly susceptible to degradation under distribution shift, which occurs in many practical applications when processing out-of-domain (OOD) text. This has been attributed to "shortcut learning": relying on weak correlations over arbitrary large contexts. We propose a method based on OOD detection with Random Network Distillation to allow an autoregressive language model to automatically disregard OOD context during inference, smoothly transitioning towards a less expressive but more robust model as the data becomes more OOD while retaining its full context capability when operating in-distribution. We apply our method to a GRU architecture, demonstrating improvements on multiple language modeling (LM) datasets.