 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVerifiable Natural Language to Linear Temporal Logic Translation: A Benchmark Dataset and Evaluation Suite
Jul 01, 2025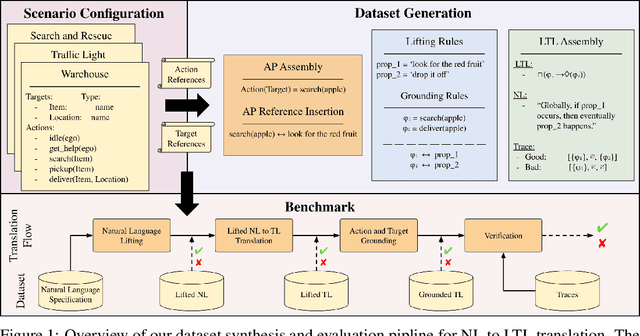
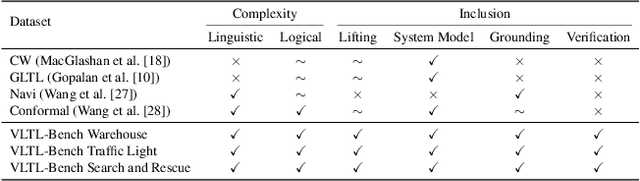


Empirical evaluation of state-of-the-art natural-language (NL) to temporal-logic (TL) translation systems reveals near-perfect performance on existing benchmarks. However, current studies measure only the accuracy of the translation of NL logic into formal TL, ignoring a system's capacity to ground atomic propositions into new scenarios or environments. This is a critical feature, necessary for the verification of resulting formulas in a concrete state space. Consequently, most NL-to-TL translation frameworks propose their own bespoke dataset in which the correct grounding is known a-priori, inflating performance metrics and neglecting the need for extensible, domain-general systems. In this paper, we introduce the Verifiable Linear Temporal Logic Benchmark ( VLTL-Bench), a unifying benchmark that measures verification and verifiability of automated NL-to-LTL translation. The dataset consists of three unique state spaces and thousands of diverse natural language specifications and corresponding formal specifications in temporal logic. Moreover, the benchmark contains sample traces to validate the temporal logic expressions. While the benchmark directly supports end-to-end evaluation, we observe that many frameworks decompose the process into i) lifting, ii) grounding, iii) translation, and iv) verification. The benchmark provides ground truths after each of these steps to enable researches to improve and evaluate different substeps of the overall problem. To encourage methodologically sound advances in verifiable NL-to-LTL translation approaches, we release VLTL-Bench here: https://www.kaggle.com/datasets/dubascudes/vltl bench.