 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGinSign: Grounding Natural Language Into System Signatures for Temporal Logic Translation
Dec 18, 2025Natural language (NL) to temporal logic (TL) translation enables engineers to specify, verify, and enforce system behaviors without manually crafting formal specifications-an essential capability for building trustworthy autonomous systems. While existing NL-to-TL translation frameworks have demonstrated encouraging initial results, these systems either explicitly assume access to accurate atom grounding or suffer from low grounded translation accuracy. In this paper, we propose a framework for Grounding Natural Language Into System Signatures for Temporal Logic translation called GinSign. The framework introduces a grounding model that learns the abstract task of mapping NL spans onto a given system signature: given a lifted NL specification and a system signature $\mathcal{S}$, the classifier must assign each lifted atomic proposition to an element of the set of signature-defined atoms $\mathcal{P}$. We decompose the grounding task hierarchically -- first predicting predicate labels, then selecting the appropriately typed constant arguments. Decomposing this task from a free-form generation problem into a structured classification problem permits the use of smaller masked language models and eliminates the reliance on expensive LLMs. Experiments across multiple domains show that frameworks which omit grounding tend to produce syntactically correct lifted LTL that is semantically nonequivalent to grounded target expressions, whereas our framework supports downstream model checking and achieves grounded logical-equivalence scores of $95.5\%$, a $1.4\times$ improvement over SOTA.
Explaining the Reasoning of Large Language Models Using Attribution Graphs
Dec 17, 2025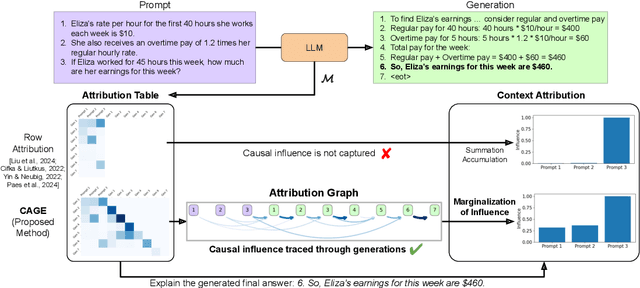
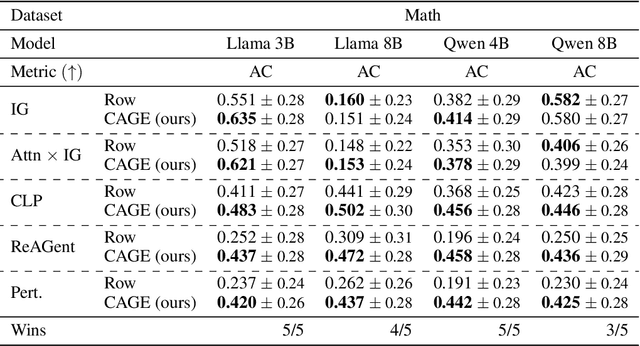
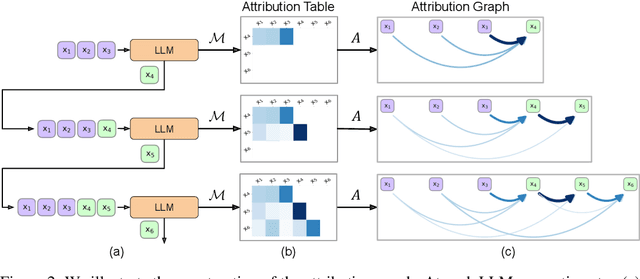
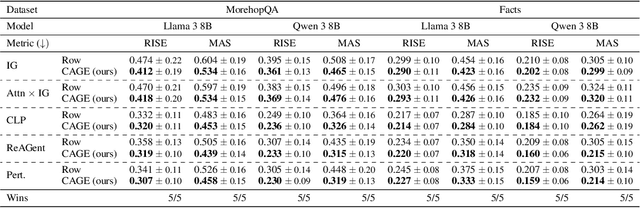
Large language models (LLMs) exhibit remarkable capabilities, yet their reasoning remains opaque, raising safety and trust concerns. Attribution methods, which assign credit to input features, have proven effective for explaining the decision making of computer vision models. From these, context attributions have emerged as a promising approach for explaining the behavior of autoregressive LLMs. However, current context attributions produce incomplete explanations by directly relating generated tokens to the prompt, discarding inter-generational influence in the process. To overcome these shortcomings, we introduce the Context Attribution via Graph Explanations (CAGE) framework. CAGE introduces an attribution graph: a directed graph that quantifies how each generation is influenced by both the prompt and all prior generations. The graph is constructed to preserve two properties-causality and row stochasticity. The attribution graph allows context attributions to be computed by marginalizing intermediate contributions along paths in the graph. Across multiple models, datasets, metrics, and methods, CAGE improves context attribution faithfulness, achieving average gains of up to 40%.
Verifiable Natural Language to Linear Temporal Logic Translation: A Benchmark Dataset and Evaluation Suite
Jul 01, 2025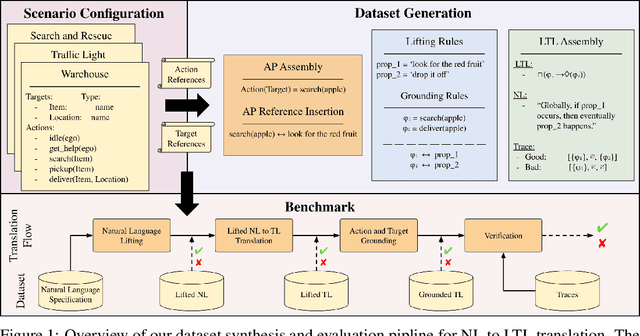
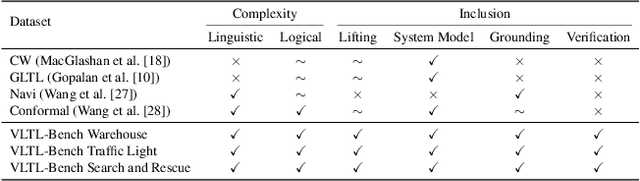


Empirical evaluation of state-of-the-art natural-language (NL) to temporal-logic (TL) translation systems reveals near-perfect performance on existing benchmarks. However, current studies measure only the accuracy of the translation of NL logic into formal TL, ignoring a system's capacity to ground atomic propositions into new scenarios or environments. This is a critical feature, necessary for the verification of resulting formulas in a concrete state space. Consequently, most NL-to-TL translation frameworks propose their own bespoke dataset in which the correct grounding is known a-priori, inflating performance metrics and neglecting the need for extensible, domain-general systems. In this paper, we introduce the Verifiable Linear Temporal Logic Benchmark ( VLTL-Bench), a unifying benchmark that measures verification and verifiability of automated NL-to-LTL translation. The dataset consists of three unique state spaces and thousands of diverse natural language specifications and corresponding formal specifications in temporal logic. Moreover, the benchmark contains sample traces to validate the temporal logic expressions. While the benchmark directly supports end-to-end evaluation, we observe that many frameworks decompose the process into i) lifting, ii) grounding, iii) translation, and iv) verification. The benchmark provides ground truths after each of these steps to enable researches to improve and evaluate different substeps of the overall problem. To encourage methodologically sound advances in verifiable NL-to-LTL translation approaches, we release VLTL-Bench here: https://www.kaggle.com/datasets/dubascudes/vltl bench.
Integrated Decision Gradients: Compute Your Attributions Where the Model Makes Its Decision
May 31, 2023



Attribution algorithms are frequently employed to explain the decisions of neural network models. Integrated Gradients (IG) is an influential attribution method due to its strong axiomatic foundation. The algorithm is based on integrating the gradients along a path from a reference image to the input image. Unfortunately, it can be observed that gradients computed from regions where the output logit changes minimally along the path provide poor explanations for the model decision, which is called the saturation effect problem. In this paper, we propose an attribution algorithm called integrated decision gradients (IDG). The algorithm focuses on integrating gradients from the region of the path where the model makes its decision, i.e., the portion of the path where the output logit rapidly transitions from zero to its final value. This is practically realized by scaling each gradient by the derivative of the output logit with respect to the path. The algorithm thereby provides a principled solution to the saturation problem. Additionally, we minimize the errors within the Riemann sum approximation of the path integral by utilizing non-uniform subdivisions determined by adaptive sampling. In the evaluation on ImageNet, it is demonstrated that IDG outperforms IG, left-IG, guided IG, and adversarial gradient integration both qualitatively and quantitatively using standard insertion and deletion metrics across three common models.