 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGinSign: Grounding Natural Language Into System Signatures for Temporal Logic Translation
Dec 18, 2025Natural language (NL) to temporal logic (TL) translation enables engineers to specify, verify, and enforce system behaviors without manually crafting formal specifications-an essential capability for building trustworthy autonomous systems. While existing NL-to-TL translation frameworks have demonstrated encouraging initial results, these systems either explicitly assume access to accurate atom grounding or suffer from low grounded translation accuracy. In this paper, we propose a framework for Grounding Natural Language Into System Signatures for Temporal Logic translation called GinSign. The framework introduces a grounding model that learns the abstract task of mapping NL spans onto a given system signature: given a lifted NL specification and a system signature $\mathcal{S}$, the classifier must assign each lifted atomic proposition to an element of the set of signature-defined atoms $\mathcal{P}$. We decompose the grounding task hierarchically -- first predicting predicate labels, then selecting the appropriately typed constant arguments. Decomposing this task from a free-form generation problem into a structured classification problem permits the use of smaller masked language models and eliminates the reliance on expensive LLMs. Experiments across multiple domains show that frameworks which omit grounding tend to produce syntactically correct lifted LTL that is semantically nonequivalent to grounded target expressions, whereas our framework supports downstream model checking and achieves grounded logical-equivalence scores of $95.5\%$, a $1.4\times$ improvement over SOTA.
Grammar-Forced Translation of Natural Language to Temporal Logic using LLMs
Dec 18, 2025
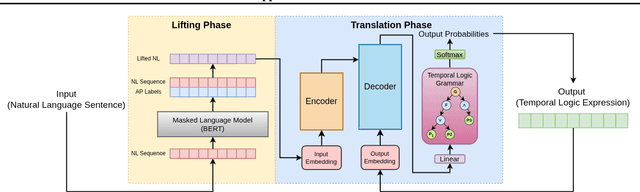

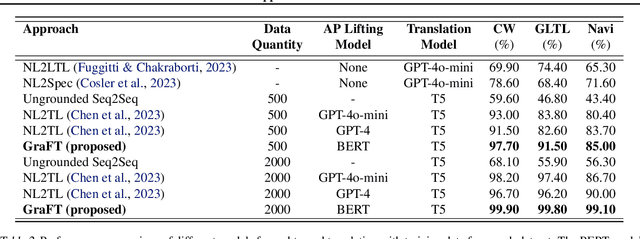
Translating natural language (NL) into a formal language such as temporal logic (TL) is integral for human communication with robots and autonomous systems. State-of-the-art approaches decompose the task into a lifting of atomic propositions (APs) phase and a translation phase. However, existing methods struggle with accurate lifting, the existence of co-references, and learning from limited data. In this paper, we propose a framework for NL to TL translation called Grammar Forced Translation (GraFT). The framework is based on the observation that previous work solves both the lifting and translation steps by letting a language model iteratively predict tokens from its full vocabulary. In contrast, GraFT reduces the complexity of both tasks by restricting the set of valid output tokens from the full vocabulary to only a handful in each step. The solution space reduction is obtained by exploiting the unique properties of each problem. We also provide a theoretical justification for why the solution space reduction leads to more efficient learning. We evaluate the effectiveness of GraFT using the CW, GLTL, and Navi benchmarks. Compared with state-of-the-art translation approaches, it can be observed that GraFT the end-to-end translation accuracy by 5.49% and out-of-domain translation accuracy by 14.06% on average.
Verifiable Natural Language to Linear Temporal Logic Translation: A Benchmark Dataset and Evaluation Suite
Jul 01, 2025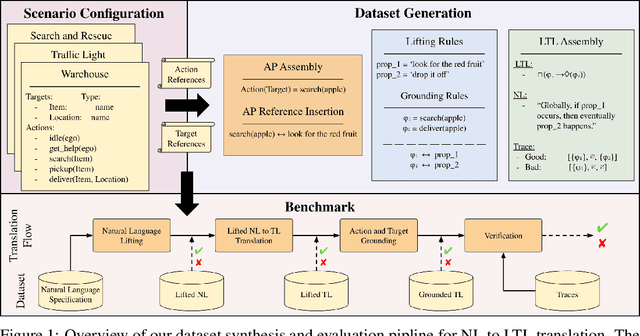
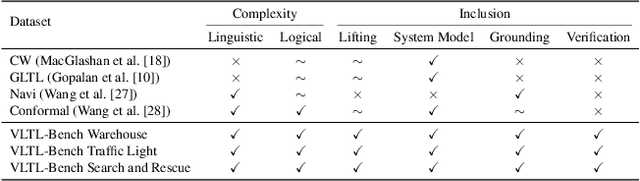


Empirical evaluation of state-of-the-art natural-language (NL) to temporal-logic (TL) translation systems reveals near-perfect performance on existing benchmarks. However, current studies measure only the accuracy of the translation of NL logic into formal TL, ignoring a system's capacity to ground atomic propositions into new scenarios or environments. This is a critical feature, necessary for the verification of resulting formulas in a concrete state space. Consequently, most NL-to-TL translation frameworks propose their own bespoke dataset in which the correct grounding is known a-priori, inflating performance metrics and neglecting the need for extensible, domain-general systems. In this paper, we introduce the Verifiable Linear Temporal Logic Benchmark ( VLTL-Bench), a unifying benchmark that measures verification and verifiability of automated NL-to-LTL translation. The dataset consists of three unique state spaces and thousands of diverse natural language specifications and corresponding formal specifications in temporal logic. Moreover, the benchmark contains sample traces to validate the temporal logic expressions. While the benchmark directly supports end-to-end evaluation, we observe that many frameworks decompose the process into i) lifting, ii) grounding, iii) translation, and iv) verification. The benchmark provides ground truths after each of these steps to enable researches to improve and evaluate different substeps of the overall problem. To encourage methodologically sound advances in verifiable NL-to-LTL translation approaches, we release VLTL-Bench here: https://www.kaggle.com/datasets/dubascudes/vltl bench.
NSP: A Neuro-Symbolic Natural Language Navigational Planner
Sep 10, 2024



Path planners that can interpret free-form natural language instructions hold promise to automate a wide range of robotics applications. These planners simplify user interactions and enable intuitive control over complex semi-autonomous systems. While existing symbolic approaches offer guarantees on the correctness and efficiency, they struggle to parse free-form natural language inputs. Conversely, neural approaches based on pre-trained Large Language Models (LLMs) can manage natural language inputs but lack performance guarantees. In this paper, we propose a neuro-symbolic framework for path planning from natural language inputs called NSP. The framework leverages the neural reasoning abilities of LLMs to i) craft symbolic representations of the environment and ii) a symbolic path planning algorithm. Next, a solution to the path planning problem is obtained by executing the algorithm on the environment representation. The framework uses a feedback loop from the symbolic execution environment to the neural generation process to self-correct syntax errors and satisfy execution time constraints. We evaluate our neuro-symbolic approach using a benchmark suite with 1500 path-planning problems. The experimental evaluation shows that our neuro-symbolic approach produces 90.1% valid paths that are on average 19-77% shorter than state-of-the-art neural approaches.