 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvances in Neural Rendering
Nov 10, 2021Synthesizing photo-realistic images and videos is at the heart of computer graphics and has been the focus of decades of research. Traditionally, synthetic images of a scene are generated using rendering algorithms such as rasterization or ray tracing, which take specifically defined representations of geometry and material properties as input. Collectively, these inputs define the actual scene and what is rendered, and are referred to as the scene representation (where a scene consists of one or more objects). Example scene representations are triangle meshes with accompanied textures (e.g., created by an artist), point clouds (e.g., from a depth sensor), volumetric grids (e.g., from a CT scan), or implicit surface functions (e.g., truncated signed distance fields). The reconstruction of such a scene representation from observations using differentiable rendering losses is known as inverse graphics or inverse rendering. Neural rendering is closely related, and combines ideas from classical computer graphics and machine learning to create algorithms for synthesizing images from real-world observations. Neural rendering is a leap forward towards the goal of synthesizing photo-realistic image and video content. In recent years, we have seen immense progress in this field through hundreds of publications that show different ways to inject learnable components into the rendering pipeline. This state-of-the-art report on advances in neural rendering focuses on methods that combine classical rendering principles with learned 3D scene representations, often now referred to as neural scene representations. A key advantage of these methods is that they are 3D-consistent by design, enabling applications such as novel viewpoint synthesis of a captured scene. In addition to methods that handle static scenes, we cover neural scene representations for modeling non-rigidly deforming objects...
HyperNeRF: A Higher-Dimensional Representation for Topologically Varying Neural Radiance Fields
Jun 24, 2021
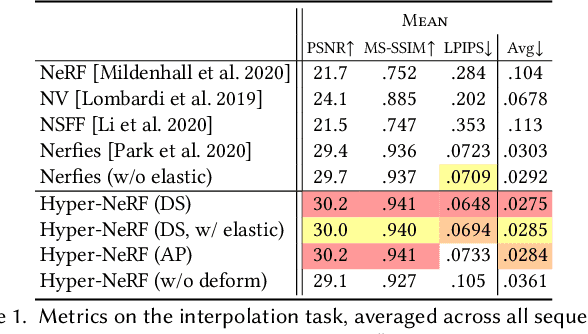
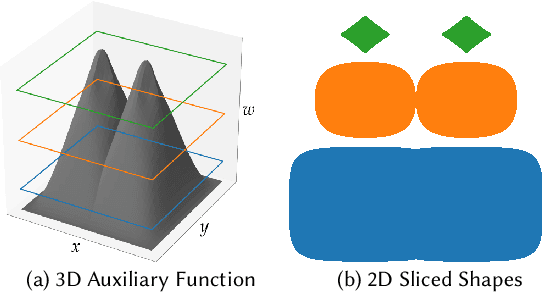
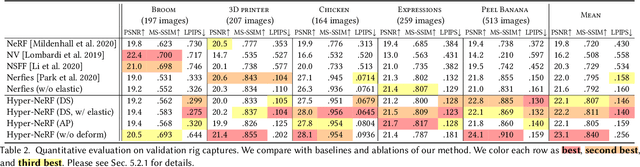
Neural Radiance Fields (NeRF) are able to reconstruct scenes with unprecedented fidelity, and various recent works have extended NeRF to handle dynamic scenes. A common approach to reconstruct such non-rigid scenes is through the use of a learned deformation field mapping from coordinates in each input image into a canonical template coordinate space. However, these deformation-based approaches struggle to model changes in topology, as topological changes require a discontinuity in the deformation field, but these deformation fields are necessarily continuous. We address this limitation by lifting NeRFs into a higher dimensional space, and by representing the 5D radiance field corresponding to each individual input image as a slice through this "hyper-space". Our method is inspired by level set methods, which model the evolution of surfaces as slices through a higher dimensional surface. We evaluate our method on two tasks: (i) interpolating smoothly between "moments", i.e., configurations of the scene, seen in the input images while maintaining visual plausibility, and (ii) novel-view synthesis at fixed moments. We show that our method, which we dub HyperNeRF, outperforms existing methods on both tasks by significant margins. Compared to Nerfies, HyperNeRF reduces average error rates by 8.6% for interpolation and 8.8% for novel-view synthesis, as measured by LPIPS.
FiG-NeRF: Figure-Ground Neural Radiance Fields for 3D Object Category Modelling
Apr 17, 2021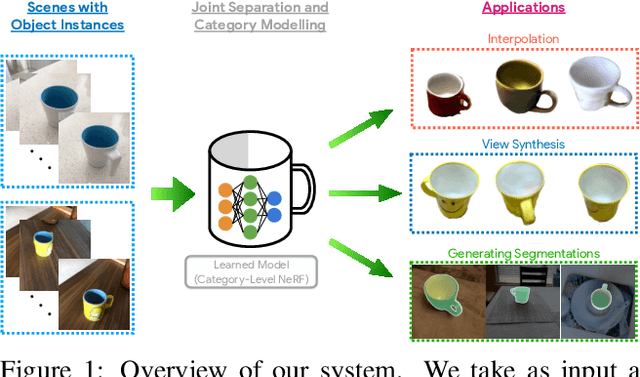

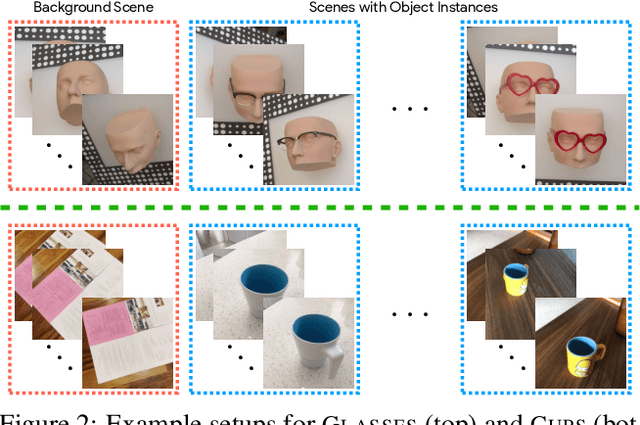
We investigate the use of Neural Radiance Fields (NeRF) to learn high quality 3D object category models from collections of input images. In contrast to previous work, we are able to do this whilst simultaneously separating foreground objects from their varying backgrounds. We achieve this via a 2-component NeRF model, FiG-NeRF, that prefers explanation of the scene as a geometrically constant background and a deformable foreground that represents the object category. We show that this method can learn accurate 3D object category models using only photometric supervision and casually captured images of the objects. Additionally, our 2-part decomposition allows the model to perform accurate and crisp amodal segmentation. We quantitatively evaluate our method with view synthesis and image fidelity metrics, using synthetic, lab-captured, and in-the-wild data. Our results demonstrate convincing 3D object category modelling that exceed the performance of existing methods.
Neural RGB-D Surface Reconstruction
Apr 09, 2021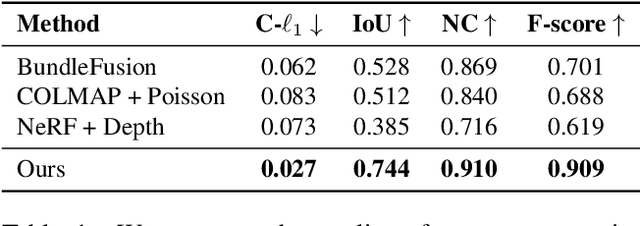
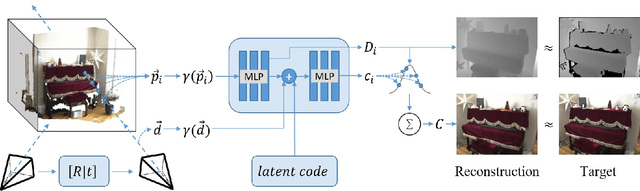
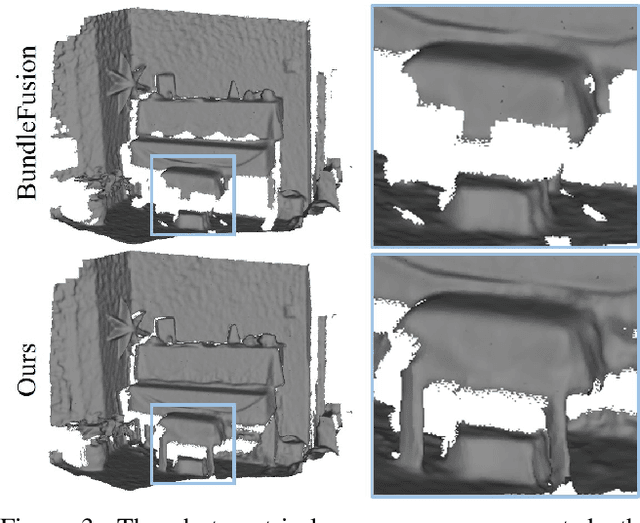
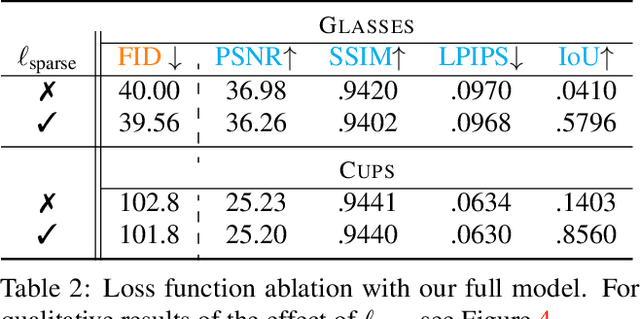
In this work, we explore how to leverage the success of implicit novel view synthesis methods for surface reconstruction. Methods which learn a neural radiance field have shown amazing image synthesis results, but the underlying geometry representation is only a coarse approximation of the real geometry. We demonstrate how depth measurements can be incorporated into the radiance field formulation to produce more detailed and complete reconstruction results than using methods based on either color or depth data alone. In contrast to a density field as the underlying geometry representation, we propose to learn a deep neural network which stores a truncated signed distance field. Using this representation, we show that one can still leverage differentiable volume rendering to estimate color values of the observed images during training to compute a reconstruction loss. This is beneficial for learning the signed distance field in regions with missing depth measurements. Furthermore, we correct misalignment errors of the camera, improving the overall reconstruction quality. In several experiments, we showcase our method and compare to existing works on classical RGB-D fusion and learned representations.
Mip-NeRF: A Multiscale Representation for Anti-Aliasing Neural Radiance Fields
Mar 24, 2021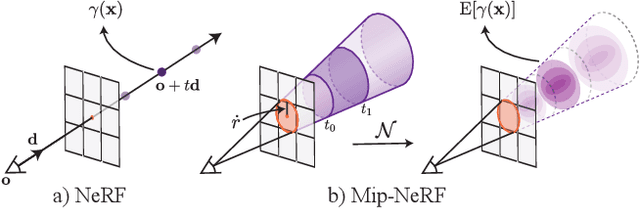


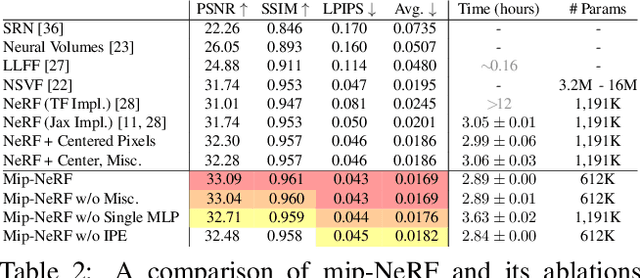
The rendering procedure used by neural radiance fields (NeRF) samples a scene with a single ray per pixel and may therefore produce renderings that are excessively blurred or aliased when training or testing images observe scene content at different resolutions. The straightforward solution of supersampling by rendering with multiple rays per pixel is impractical for NeRF, because rendering each ray requires querying a multilayer perceptron hundreds of times. Our solution, which we call "mip-NeRF" (a la "mipmap"), extends NeRF to represent the scene at a continuously-valued scale. By efficiently rendering anti-aliased conical frustums instead of rays, mip-NeRF reduces objectionable aliasing artifacts and significantly improves NeRF's ability to represent fine details, while also being 7% faster than NeRF and half the size. Compared to NeRF, mip-NeRF reduces average error rates by 16% on the dataset presented with NeRF and by 60% on a challenging multiscale variant of that dataset that we present. Mip-NeRF is also able to match the accuracy of a brute-force supersampled NeRF on our multiscale dataset while being 22x faster.
IBRNet: Learning Multi-View Image-Based Rendering
Feb 25, 2021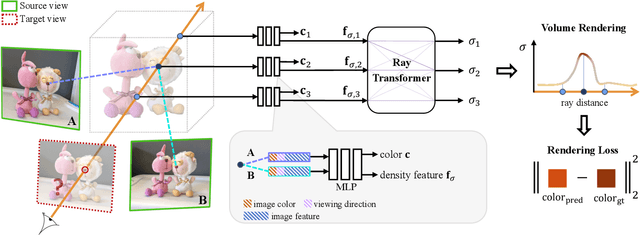
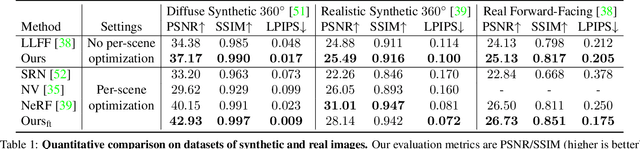
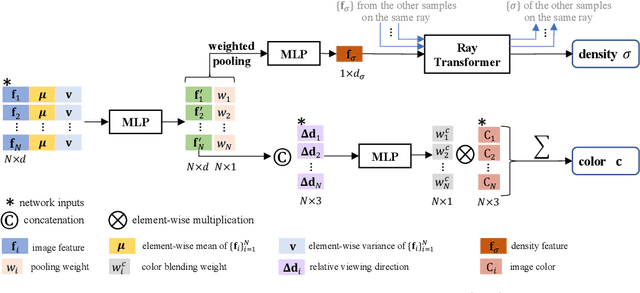
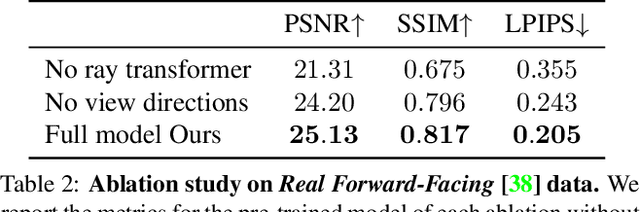
We present a method that synthesizes novel views of complex scenes by interpolating a sparse set of nearby views. The core of our method is a network architecture that includes a multilayer perceptron and a ray transformer that estimates radiance and volume density at continuous 5D locations (3D spatial locations and 2D viewing directions), drawing appearance information on the fly from multiple source views. By drawing on source views at render time, our method hearkens back to classic work on image-based rendering (IBR), and allows us to render high-resolution imagery. Unlike neural scene representation work that optimizes per-scene functions for rendering, we learn a generic view interpolation function that generalizes to novel scenes. We render images using classic volume rendering, which is fully differentiable and allows us to train using only multi-view posed images as supervision. Experiments show that our method outperforms recent novel view synthesis methods that also seek to generalize to novel scenes. Further, if fine-tuned on each scene, our method is competitive with state-of-the-art single-scene neural rendering methods.
ShaRF: Shape-conditioned Radiance Fields from a Single View
Feb 17, 2021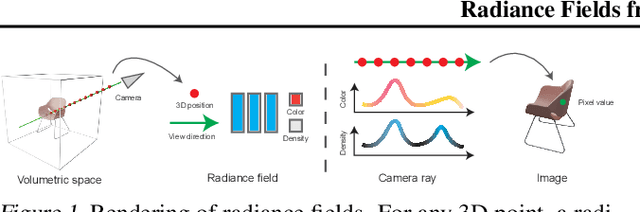
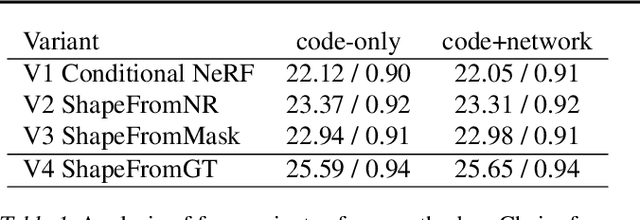
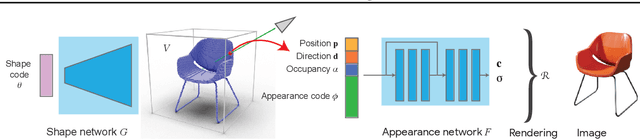
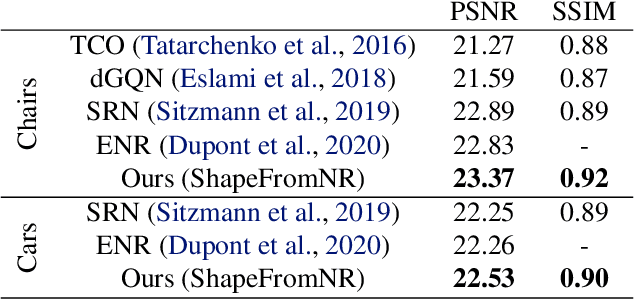
We present a method for estimating neural scenes representations of objects given only a single image. The core of our method is the estimation of a geometric scaffold for the object and its use as a guide for the reconstruction of the underlying radiance field. Our formulation is based on a generative process that first maps a latent code to a voxelized shape, and then renders it to an image, with the object appearance being controlled by a second latent code. During inference, we optimize both the latent codes and the networks to fit a test image of a new object. The explicit disentanglement of shape and appearance allows our model to be fine-tuned given a single image. We can then render new views in a geometrically consistent manner and they represent faithfully the input object. Additionally, our method is able to generalize to images outside of the training domain (more realistic renderings and even real photographs). Finally, the inferred geometric scaffold is itself an accurate estimate of the object's 3D shape. We demonstrate in several experiments the effectiveness of our approach in both synthetic and real images.
Time-Travel Rephotography
Dec 22, 2020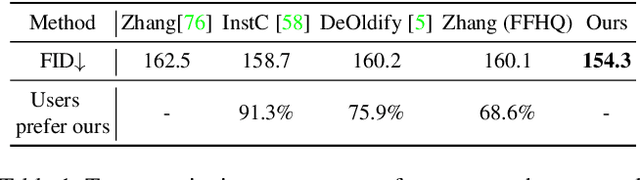
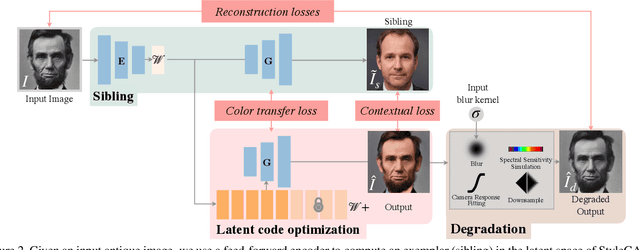


Many historical people are captured only in old, faded, black and white photos, that have been distorted by the limitations of early cameras and the passage of time. This paper simulates traveling back in time with a modern camera to rephotograph famous subjects. Unlike conventional image restoration filters which apply independent operations like denoising, colorization, and superresolution, we leverage the StyleGAN2 framework to project old photos into the space of modern high-resolution photos, achieving all of these effects in a unified framework. A unique challenge with this approach is capturing the identity and pose of the photo's subject and not the many artifacts in low-quality antique photos. Our comparisons to current state-of-the-art restoration filters show significant improvements and compelling results for a variety of important historical people.
No Shadow Left Behind: Removing Objects and their Shadows using Approximate Lighting and Geometry
Dec 19, 2020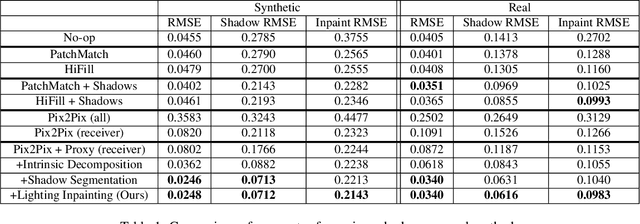
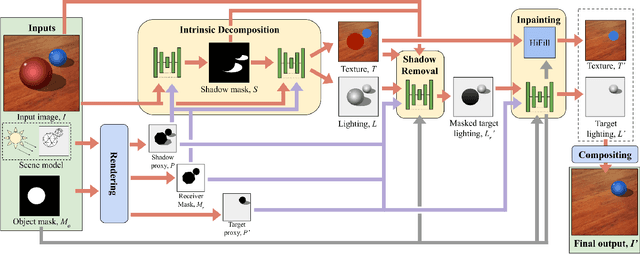


Removing objects from images is a challenging problem that is important for many applications, including mixed reality. For believable results, the shadows that the object casts should also be removed. Current inpainting-based methods only remove the object itself, leaving shadows behind, or at best require specifying shadow regions to inpaint. We introduce a deep learning pipeline for removing a shadow along with its caster. We leverage rough scene models in order to remove a wide variety of shadows (hard or soft, dark or subtle, large or thin) from surfaces with a wide variety of textures. We train our pipeline on synthetically rendered data, and show qualitative and quantitative results on both synthetic and real scenes.
Deformable Neural Radiance Fields
Nov 26, 2020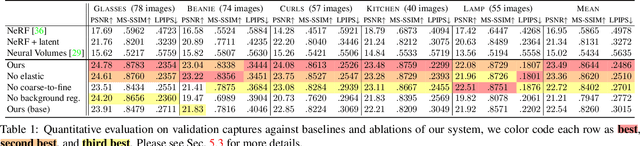

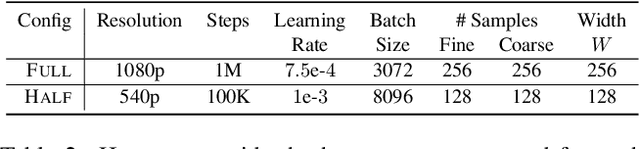

We present the first method capable of photorealistically reconstructing a non-rigidly deforming scene using photos/videos captured casually from mobile phones. Our approach -- D-NeRF -- augments neural radiance fields (NeRF) by optimizing an additional continuous volumetric deformation field that warps each observed point into a canonical 5D NeRF. We observe that these NeRF-like deformation fields are prone to local minima, and propose a coarse-to-fine optimization method for coordinate-based models that allows for more robust optimization. By adapting principles from geometry processing and physical simulation to NeRF-like models, we propose an elastic regularization of the deformation field that further improves robustness. We show that D-NeRF can turn casually captured selfie photos/videos into deformable NeRF models that allow for photorealistic renderings of the subject from arbitrary viewpoints, which we dub "nerfies." We evaluate our method by collecting data using a rig with two mobile phones that take time-synchronized photos, yielding train/validation images of the same pose at different viewpoints. We show that our method faithfully reconstructs non-rigidly deforming scenes and reproduces unseen views with high fidelity.