 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Hallucinations: Correctness, Consistency, and Prompt Multiplicity
Jan 31, 2026Large language models (LLMs) are known to "hallucinate" by generating false or misleading outputs. Hallucinations pose various harms, from erosion of trust to widespread misinformation. Existing hallucination evaluation, however, focuses only on correctness and often overlooks consistency, necessary to distinguish and address these harms. To bridge this gap, we introduce prompt multiplicity, a framework for quantifying consistency in LLM evaluations. Our analysis reveals significant multiplicity (over 50% inconsistency in benchmarks like Med-HALT), suggesting that hallucination-related harms have been severely misunderstood. Furthermore, we study the role of consistency in hallucination detection and mitigation. We find that: (a) detection techniques detect consistency, not correctness, and (b) mitigation techniques like RAG, while beneficial, can introduce additional inconsistencies. By integrating prompt multiplicity into hallucination evaluation, we provide an improved framework of potential harms and uncover critical limitations in current detection and mitigation strategies.
The Canary's Echo: Auditing Privacy Risks of LLM-Generated Synthetic Text
Feb 19, 2025



How much information about training samples can be gleaned from synthetic data generated by Large Language Models (LLMs)? Overlooking the subtleties of information flow in synthetic data generation pipelines can lead to a false sense of privacy. In this paper, we design membership inference attacks (MIAs) that target data used to fine-tune pre-trained LLMs that are then used to synthesize data, particularly when the adversary does not have access to the fine-tuned model but only to the synthetic data. We show that such data-based MIAs do significantly better than a random guess, meaning that synthetic data leaks information about the training data. Further, we find that canaries crafted to maximize vulnerability to model-based MIAs are sub-optimal for privacy auditing when only synthetic data is released. Such out-of-distribution canaries have limited influence on the model's output when prompted to generate useful, in-distribution synthetic data, which drastically reduces their vulnerability. To tackle this problem, we leverage the mechanics of auto-regressive models to design canaries with an in-distribution prefix and a high-perplexity suffix that leave detectable traces in synthetic data. This enhances the power of data-based MIAs and provides a better assessment of the privacy risks of releasing synthetic data generated by LLMs.
Minerva: A Programmable Memory Test Benchmark for Language Models
Feb 05, 2025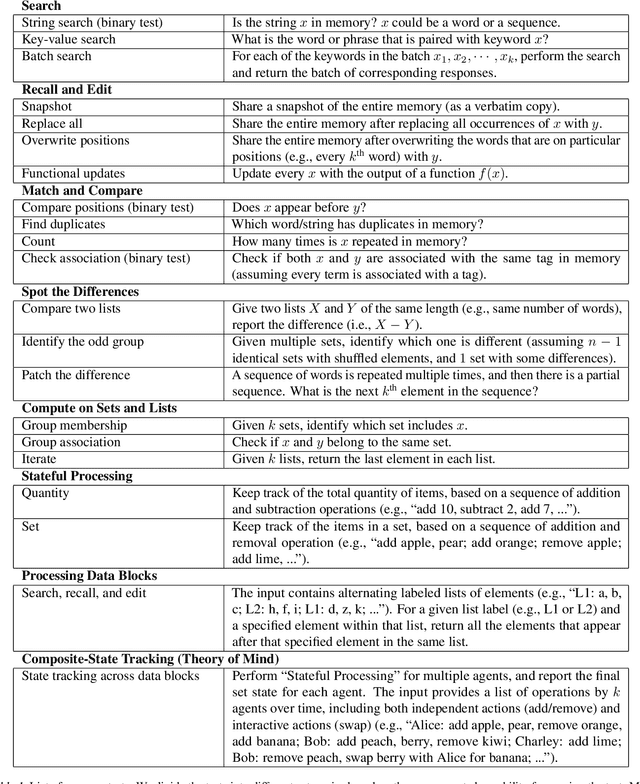



How effectively can LLM-based AI assistants utilize their memory (context) to perform various tasks? Traditional data benchmarks, which are often manually crafted, suffer from several limitations: they are static, susceptible to overfitting, difficult to interpret, and lack actionable insights--failing to pinpoint the specific capabilities a model lacks when it does not pass a test. In this paper, we present a framework for automatically generating a comprehensive set of tests to evaluate models' abilities to use their memory effectively. Our framework extends the range of capability tests beyond the commonly explored (passkey, key-value, needle in the haystack) search, a dominant focus in the literature. Specifically, we evaluate models on atomic tasks such as searching, recalling, editing, matching, comparing information in context memory, and performing basic operations when inputs are structured into distinct blocks, simulating real-world data. Additionally, we design composite tests to investigate the models' ability to maintain state while operating on memory. Our benchmark enables an interpretable, detailed assessment of memory capabilities of LLMs.
Range Membership Inference Attacks
Aug 09, 2024



Machine learning models can leak private information about their training data, but the standard methods to measure this risk, based on membership inference attacks (MIAs), have a major limitation. They only check if a given data point \textit{exactly} matches a training point, neglecting the potential of similar or partially overlapping data revealing the same private information. To address this issue, we introduce the class of range membership inference attacks (RaMIAs), testing if the model was trained on any data in a specified range (defined based on the semantics of privacy). We formulate the RaMIAs game and design a principled statistical test for its complex hypotheses. We show that RaMIAs can capture privacy loss more accurately and comprehensively than MIAs on various types of data, such as tabular, image, and language. RaMIA paves the way for a more comprehensive and meaningful privacy auditing of machine learning algorithms.
Watermark Smoothing Attacks against Language Models
Jul 19, 2024



Watermarking is a technique used to embed a hidden signal in the probability distribution of text generated by large language models (LLMs), enabling attribution of the text to the originating model. We introduce smoothing attacks and show that existing watermarking methods are not robust against minor modifications of text. An adversary can use weaker language models to smooth out the distribution perturbations caused by watermarks without significantly compromising the quality of the generated text. The modified text resulting from the smoothing attack remains close to the distribution of text that the original model (without watermark) would have produced. Our attack reveals a fundamental limitation of a wide range of watermarking techniques.
The Data Minimization Principle in Machine Learning
May 29, 2024



The principle of data minimization aims to reduce the amount of data collected, processed or retained to minimize the potential for misuse, unauthorized access, or data breaches. Rooted in privacy-by-design principles, data minimization has been endorsed by various global data protection regulations. However, its practical implementation remains a challenge due to the lack of a rigorous formulation. This paper addresses this gap and introduces an optimization framework for data minimization based on its legal definitions. It then adapts several optimization algorithms to perform data minimization and conducts a comprehensive evaluation in terms of their compliance with minimization objectives as well as their impact on user privacy. Our analysis underscores the mismatch between the privacy expectations of data minimization and the actual privacy benefits, emphasizing the need for approaches that account for multiple facets of real-world privacy risks.
Low-Cost High-Power Membership Inference by Boosting Relativity
Dec 06, 2023



We present a robust membership inference attack (RMIA) that amplifies the distinction between population data and the training data on any target model, by effectively leveraging both reference models and reference data in our likelihood ratio test. Our algorithm exhibits superior test power (true-positive rate) when compared to prior methods, even at extremely low false-positive error rates (as low as 0). Also, under computation constraints, where only a limited number of reference models (as few as 1) are available, our method performs exceptionally well, unlike some prior attacks that approach random guessing in such scenarios. Our method lays the groundwork for cost-effective and practical yet powerful and robust privacy risk analysis of machine learning algorithms.
Unified Enhancement of Privacy Bounds for Mixture Mechanisms via $f$-Differential Privacy
Nov 01, 2023Differentially private (DP) machine learning algorithms incur many sources of randomness, such as random initialization, random batch subsampling, and shuffling. However, such randomness is difficult to take into account when proving differential privacy bounds because it induces mixture distributions for the algorithm's output that are difficult to analyze. This paper focuses on improving privacy bounds for shuffling models and one-iteration differentially private gradient descent (DP-GD) with random initializations using $f$-DP. We derive a closed-form expression of the trade-off function for shuffling models that outperforms the most up-to-date results based on $(\epsilon,\delta)$-DP. Moreover, we investigate the effects of random initialization on the privacy of one-iteration DP-GD. Our numerical computations of the trade-off function indicate that random initialization can enhance the privacy of DP-GD. Our analysis of $f$-DP guarantees for these mixture mechanisms relies on an inequality for trade-off functions introduced in this paper. This inequality implies the joint convexity of $F$-divergences. Finally, we study an $f$-DP analog of the advanced joint convexity of the hockey-stick divergence related to $(\epsilon,\delta)$-DP and apply it to analyze the privacy of mixture mechanisms.
Initialization Matters: Privacy-Utility Analysis of Overparameterized Neural Networks
Oct 31, 2023We analytically investigate how over-parameterization of models in randomized machine learning algorithms impacts the information leakage about their training data. Specifically, we prove a privacy bound for the KL divergence between model distributions on worst-case neighboring datasets, and explore its dependence on the initialization, width, and depth of fully connected neural networks. We find that this KL privacy bound is largely determined by the expected squared gradient norm relative to model parameters during training. Notably, for the special setting of linearized network, our analysis indicates that the squared gradient norm (and therefore the escalation of privacy loss) is tied directly to the per-layer variance of the initialization distribution. By using this analysis, we demonstrate that privacy bound improves with increasing depth under certain initializations (LeCun and Xavier), while degrades with increasing depth under other initializations (He and NTK). Our work reveals a complex interplay between privacy and depth that depends on the chosen initialization distribution. We further prove excess empirical risk bounds under a fixed KL privacy budget, and show that the interplay between privacy utility trade-off and depth is similarly affected by the initialization.
Can LLMs Keep a Secret? Testing Privacy Implications of Language Models via Contextual Integrity Theory
Oct 27, 2023The interactive use of large language models (LLMs) in AI assistants (at work, home, etc.) introduces a new set of inference-time privacy risks: LLMs are fed different types of information from multiple sources in their inputs and are expected to reason about what to share in their outputs, for what purpose and with whom, within a given context. In this work, we draw attention to the highly critical yet overlooked notion of contextual privacy by proposing ConfAIde, a benchmark designed to identify critical weaknesses in the privacy reasoning capabilities of instruction-tuned LLMs. Our experiments show that even the most capable models such as GPT-4 and ChatGPT reveal private information in contexts that humans would not, 39% and 57% of the time, respectively. This leakage persists even when we employ privacy-inducing prompts or chain-of-thought reasoning. Our work underscores the immediate need to explore novel inference-time privacy-preserving approaches, based on reasoning and theory of mind.