 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDR-BiLSTM: Dependent Reading Bidirectional LSTM for Natural Language Inference
Apr 11, 2018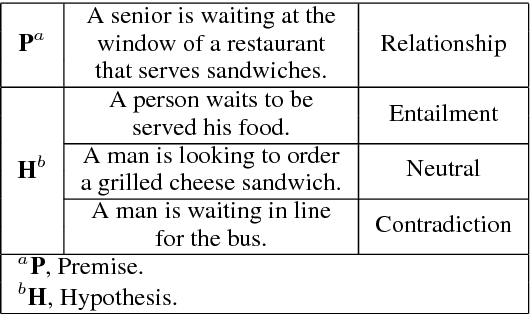
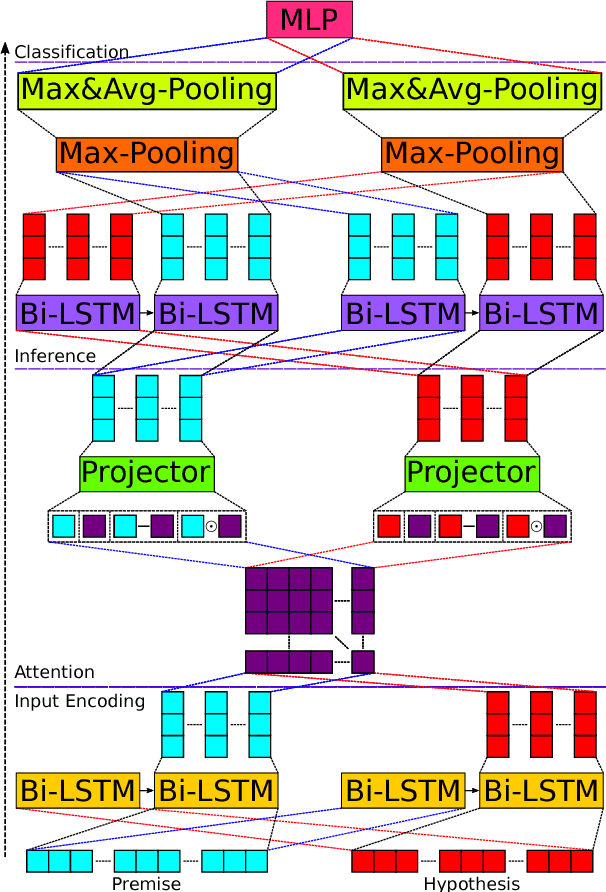
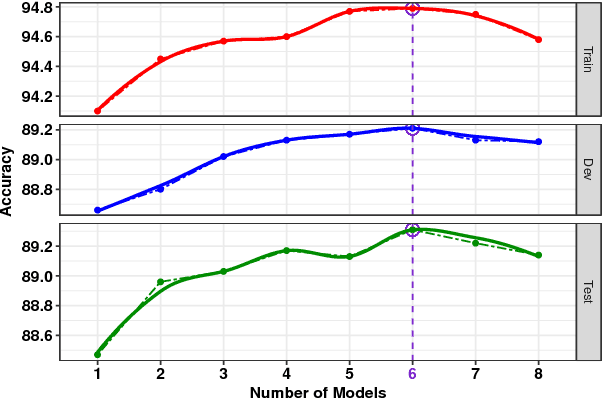
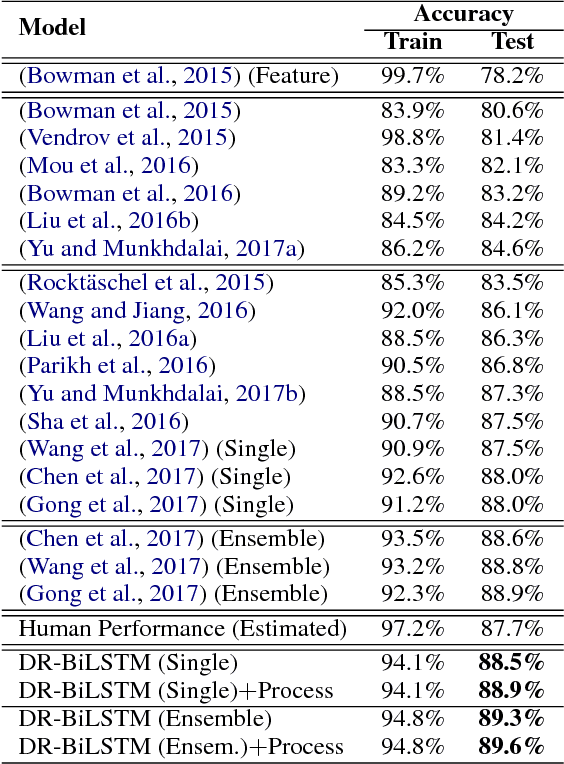
We present a novel deep learning architecture to address the natural language inference (NLI) task. Existing approaches mostly rely on simple reading mechanisms for independent encoding of the premise and hypothesis. Instead, we propose a novel dependent reading bidirectional LSTM network (DR-BiLSTM) to efficiently model the relationship between a premise and a hypothesis during encoding and inference. We also introduce a sophisticated ensemble strategy to combine our proposed models, which noticeably improves final predictions. Finally, we demonstrate how the results can be improved further with an additional preprocessing step. Our evaluation shows that DR-BiLSTM obtains the best single model and ensemble model results achieving the new state-of-the-art scores on the Stanford NLI dataset.
Condensed Memory Networks for Clinical Diagnostic Inferencing
Jan 03, 2017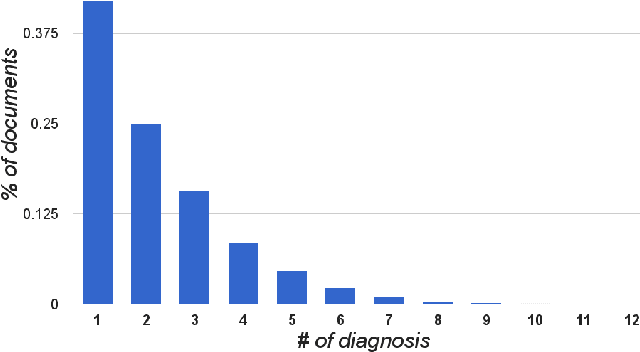


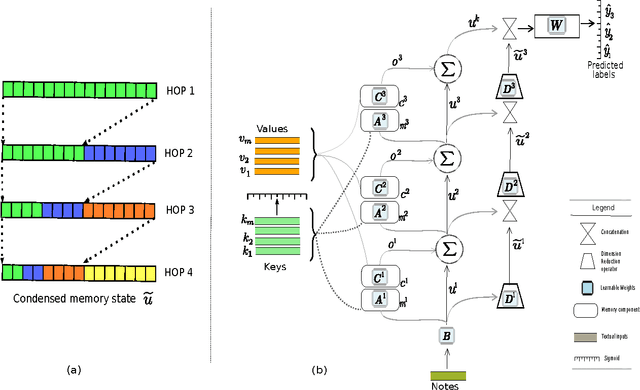
Diagnosis of a clinical condition is a challenging task, which often requires significant medical investigation. Previous work related to diagnostic inferencing problems mostly consider multivariate observational data (e.g. physiological signals, lab tests etc.). In contrast, we explore the problem using free-text medical notes recorded in an electronic health record (EHR). Complex tasks like these can benefit from structured knowledge bases, but those are not scalable. We instead exploit raw text from Wikipedia as a knowledge source. Memory networks have been demonstrated to be effective in tasks which require comprehension of free-form text. They use the final iteration of the learned representation to predict probable classes. We introduce condensed memory neural networks (C-MemNNs), a novel model with iterative condensation of memory representations that preserves the hierarchy of features in the memory. Experiments on the MIMIC-III dataset show that the proposed model outperforms other variants of memory networks to predict the most probable diagnoses given a complex clinical scenario.
Neural Paraphrase Generation with Stacked Residual LSTM Networks
Oct 13, 2016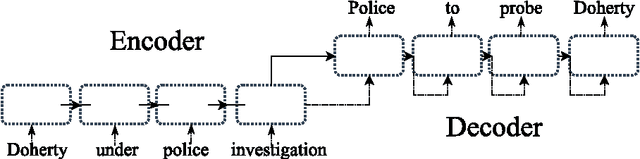

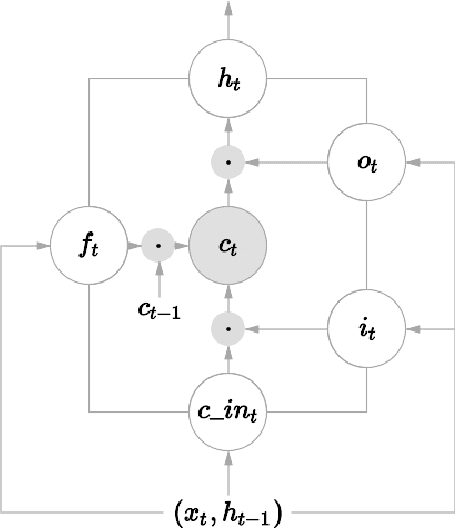
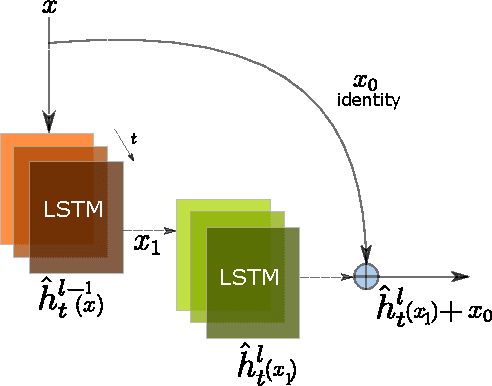
In this paper, we propose a novel neural approach for paraphrase generation. Conventional para- phrase generation methods either leverage hand-written rules and thesauri-based alignments, or use statistical machine learning principles. To the best of our knowledge, this work is the first to explore deep learning models for paraphrase generation. Our primary contribution is a stacked residual LSTM network, where we add residual connections between LSTM layers. This allows for efficient training of deep LSTMs. We evaluate our model and other state-of-the-art deep learning models on three different datasets: PPDB, WikiAnswers and MSCOCO. Evaluation results demonstrate that our model outperforms sequence to sequence, attention-based and bi- directional LSTM models on BLEU, METEOR, TER and an embedding-based sentence similarity metric.
A Data-Driven Approach for Semantic Role Labeling from Induced Grammar Structures in Language
Jun 20, 2016
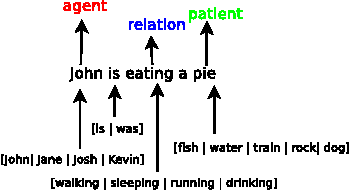
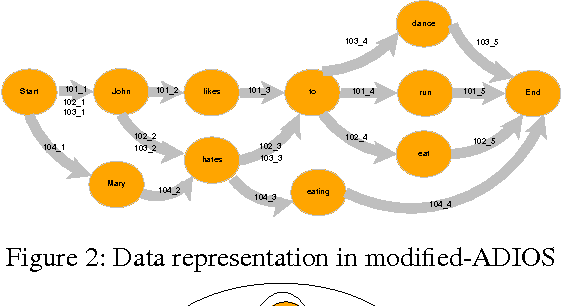

Semantic roles play an important role in extracting knowledge from text. Current unsupervised approaches utilize features from grammar structures, to induce semantic roles. The dependence on these grammars, however, makes it difficult to adapt to noisy and new languages. In this paper we develop a data-driven approach to identifying semantic roles, the approach is entirely unsupervised up to the point where rules need to be learned to identify the position the semantic role occurs. Specifically we develop a modified-ADIOS algorithm based on ADIOS Solan et al. (2005) to learn grammar structures, and use these grammar structures to learn the rules for identifying the semantic roles based on the context in which the grammar structures appeared. The results obtained are comparable with the current state-of-art models that are inherently dependent on human annotated data.
Predicting the top and bottom ranks of billboard songs using Machine Learning
Dec 03, 2015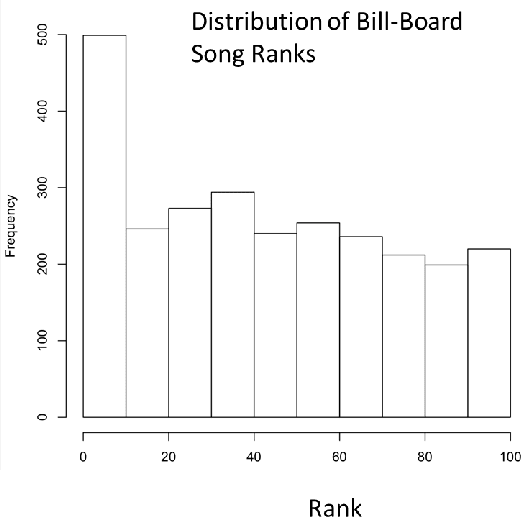

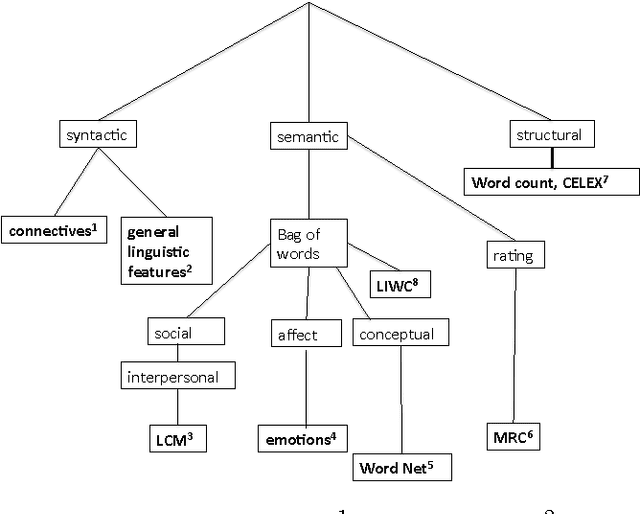
The music industry is a $130 billion industry. Predicting whether a song catches the pulse of the audience impacts the industry. In this paper we analyze language inside the lyrics of the songs using several computational linguistic algorithms and predict whether a song would make to the top or bottom of the billboard rankings based on the language features. We trained and tested an SVM classifier with a radial kernel function on the linguistic features. Results indicate that we can classify whether a song belongs to top and bottom of the billboard charts with a precision of 0.76.