 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeculative Beam Search for Simultaneous Translation
Sep 12, 2019

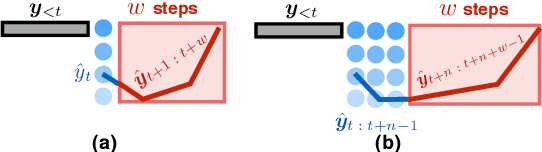
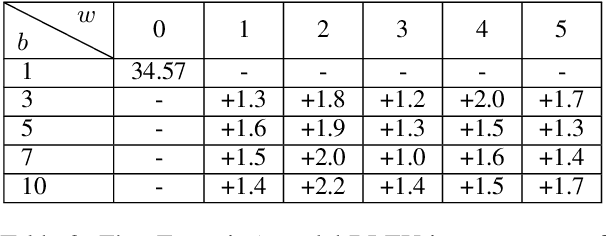
Beam search is universally used in full-sentence translation but its application to simultaneous translation remains non-trivial, where output words are committed on the fly. In particular, the recently proposed wait-k policy (Ma et al., 2019a) is a simple and effective method that (after an initial wait) commits one output word on receiving each input word, making beam search seemingly impossible. To address this challenge, we propose a speculative beam search algorithm that hallucinates several steps into the future in order to reach a more accurate decision, implicitly benefiting from a target language model. This makes beam search applicable for the first time to the generation of a single word in each step. Experiments over diverse language pairs show large improvements over previous work.
Robust Machine Translation with Domain Sensitive Pseudo-Sources: Baidu-OSU WMT19 MT Robustness Shared Task System Report
Jun 22, 2019
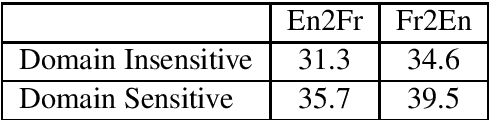
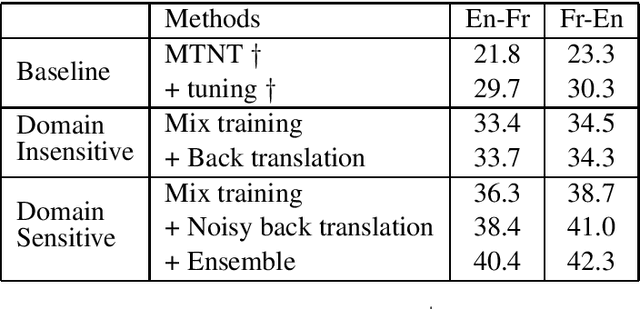
This paper describes the machine translation system developed jointly by Baidu Research and Oregon State University for WMT 2019 Machine Translation Robustness Shared Task. Translation of social media is a very challenging problem, since its style is very different from normal parallel corpora (e.g. News) and also include various types of noises. To make it worse, the amount of social media parallel corpora is extremely limited. In this paper, we use a domain sensitive training method which leverages a large amount of parallel data from popular domains together with a little amount of parallel data from social media. Furthermore, we generate a parallel dataset with pseudo noisy source sentences which are back-translated from monolingual data using a model trained by a similar domain sensitive way. We achieve more than 10 BLEU improvement in both En-Fr and Fr-En translation compared with the baseline methods.
Simultaneous Translation with Flexible Policy via Restricted Imitation Learning
Jun 04, 2019
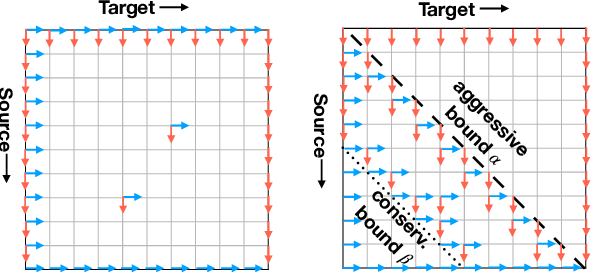
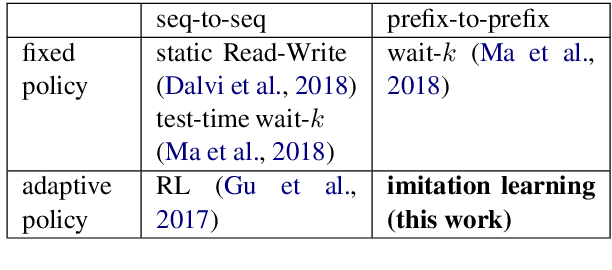
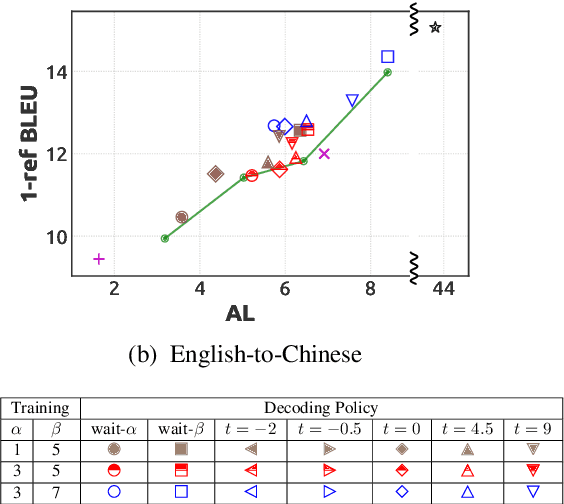
Simultaneous translation is widely useful but remains one of the most difficult tasks in NLP. Previous work either uses fixed-latency policies, or train a complicated two-staged model using reinforcement learning. We propose a much simpler single model that adds a `delay' token to the target vocabulary, and design a restricted dynamic oracle to greatly simplify training. Experiments on Chinese<->English simultaneous translation show that our work leads to flexible policies that achieve better BLEU scores and lower latencies compared to both fixed and RL-learned policies.
Learning to Stop in Structured Prediction for Neural Machine Translation
Apr 01, 2019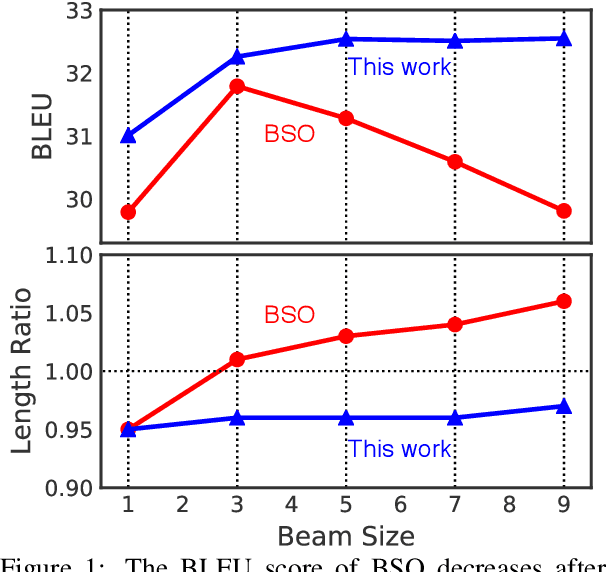
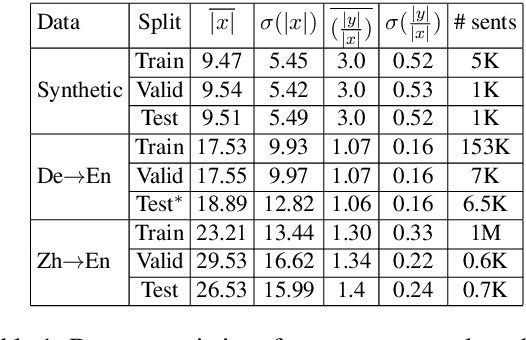
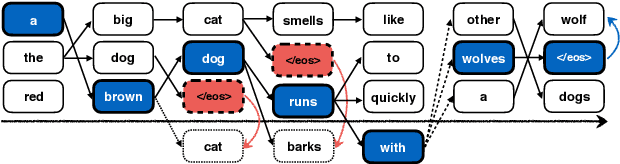
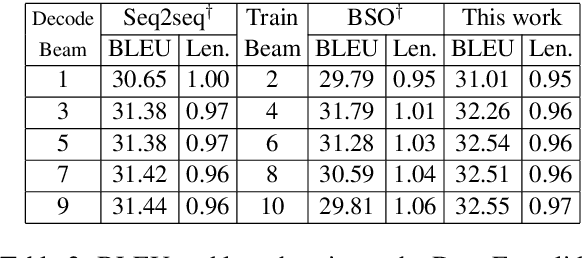
Beam search optimization resolves many issues in neural machine translation. However, this method lacks principled stopping criteria and does not learn how to stop during training, and the model naturally prefers the longer hypotheses during the testing time in practice since they use the raw score instead of the probability-based score. We propose a novel ranking method which enables an optimal beam search stopping criteria. We further introduce a structured prediction loss function which penalizes suboptimal finished candidates produced by beam search during training. Experiments of neural machine translation on both synthetic data and real languages (German-to-English and Chinese-to-English) demonstrate our proposed methods lead to better length and BLEU score.
* 5 pages
Ensemble Sequence Level Training for Multimodal MT: OSU-Baidu WMT18 Multimodal Machine Translation System Report
Aug 31, 2018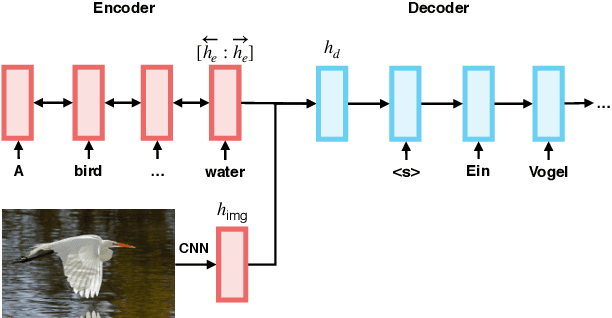
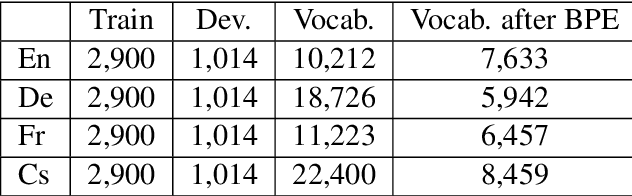
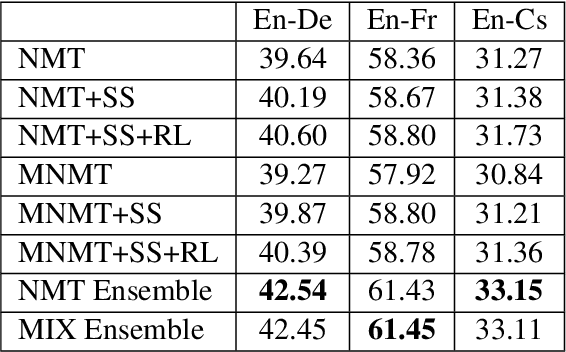
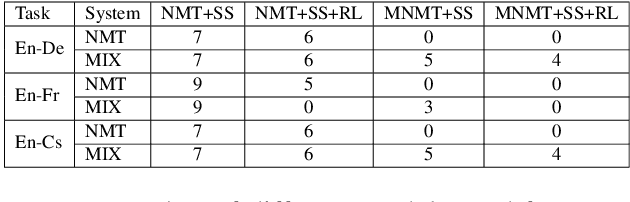
This paper describes multimodal machine translation systems developed jointly by Oregon State University and Baidu Research for WMT 2018 Shared Task on multimodal translation. In this paper, we introduce a simple approach to incorporate image information by feeding image features to the decoder side. We also explore different sequence level training methods including scheduled sampling and reinforcement learning which lead to substantial improvements. Our systems ensemble several models using different architectures and training methods and achieve the best performance for three subtasks: En-De and En-Cs in task 1 and (En+De+Fr)-Cs task 1B.
* 5 pages
Multi-Reference Training with Pseudo-References for Neural Translation and Text Generation
Aug 28, 2018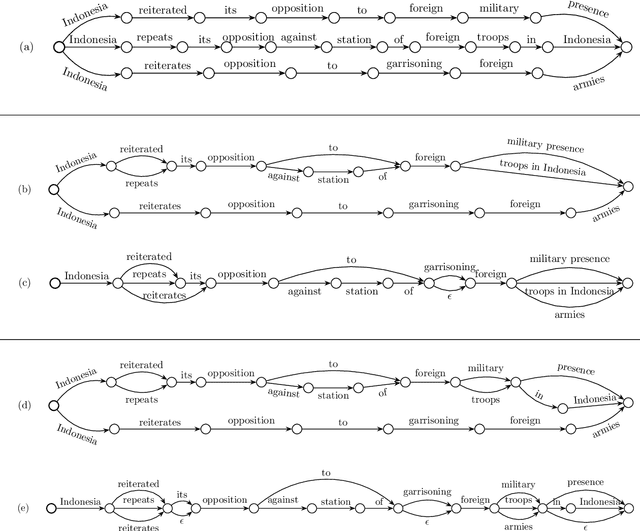

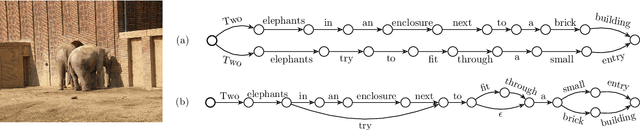
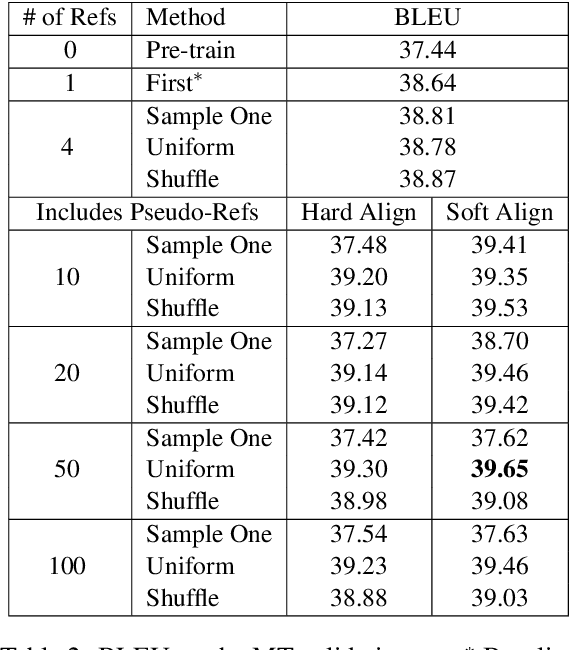
Neural text generation, including neural machine translation, image captioning, and summarization, has been quite successful recently. However, during training time, typically only one reference is considered for each example, even though there are often multiple references available, e.g., 4 references in NIST MT evaluations, and 5 references in image captioning data. We first investigate several different ways of utilizing multiple human references during training. But more importantly, we then propose an algorithm to generate exponentially many pseudo-references by first compressing existing human references into lattices and then traversing them to generate new pseudo-references. These approaches lead to substantial improvements over strong baselines in both machine translation (+1.5 BLEU) and image captioning (+3.1 BLEU / +11.7 CIDEr).
* 10 pages
Same Representation, Different Attentions: Shareable Sentence Representation Learning from Multiple Tasks
Apr 22, 2018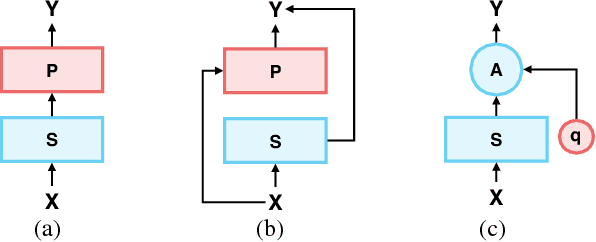
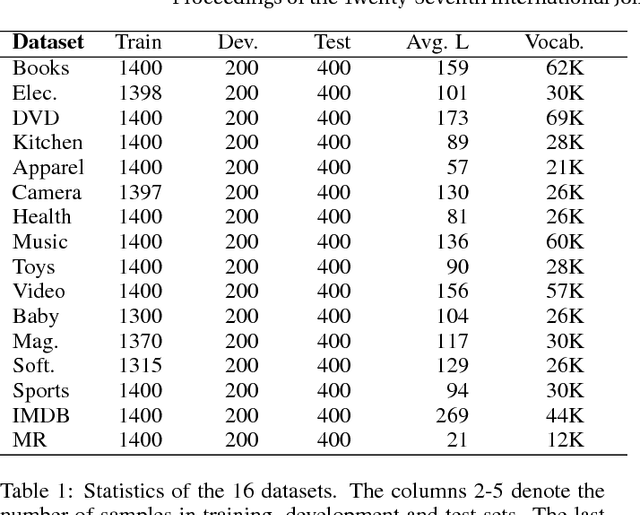
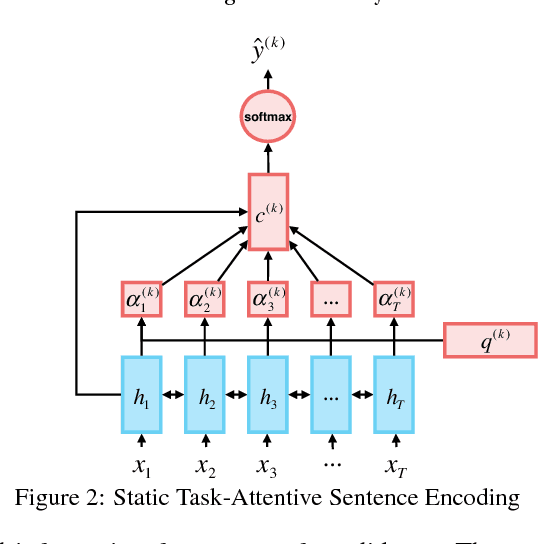
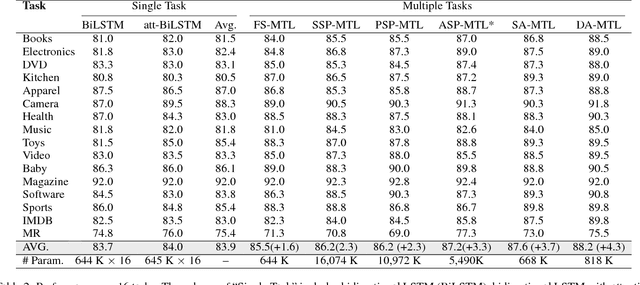
Distributed representation plays an important role in deep learning based natural language processing. However, the representation of a sentence often varies in different tasks, which is usually learned from scratch and suffers from the limited amounts of training data. In this paper, we claim that a good sentence representation should be invariant and can benefit the various subsequent tasks. To achieve this purpose, we propose a new scheme of information sharing for multi-task learning. More specifically, all tasks share the same sentence representation and each task can select the task-specific information from the shared sentence representation with attention mechanism. The query vector of each task's attention could be either static parameters or generated dynamically. We conduct extensive experiments on 16 different text classification tasks, which demonstrate the benefits of our architecture.
* 7 pages