 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning over Grammar: Can Synthetic Linguistic Reasoning Traces Enhance Low-Resource Machine Translation?
Jun 02, 2026Large language models (LLMs) offer a promising approach to machine translation (MT) for extremely low-resource languages by incorporating linguistic resources through in-context learning. However, LLMs often struggle to apply grammatical information effectively during translation. Inspired by recent progress in chain-of-thought reasoning, we investigate whether low-resource MT can benefit from structured intermediate steps of linguistic analysis and grammatical reasoning. We propose a pipeline for automatically generating step-by-step linguistic reasoning traces from Universal Dependencies treebanks, dictionaries, and grammar-rule banks. We evaluate these traces in three settings: in-context learning (ICL), supervised fine-tuning (SFT), and reinforcement fine-tuning (RFT), on Xibe and Chintang as test cases. Our results show that linguistic reasoning traces are most effective as inference-time guidance: in ICL, reliable sentence-specific traces substantially improve translation performance across most models, languages, and metrics. In contrast, using the linguistic reasoning traces as training data yields smaller and less consistent gains, as models learn the trace format but often generate erroneous content. These findings suggest that LLMs can leverage grammatical information for low-resource MT when given reliable linguistic analyses, while learning to generate such analyses remains a major bottleneck.
Information Asymmetry across Language Varieties: A Case Study on Cantonese-Mandarin and Bavarian-German QA
Mar 16, 2026Large Language Models (LLMs) are becoming a common way for humans to seek knowledge, yet their coverage and reliability vary widely. Especially for local language varieties, there are large asymmetries, e.g., information in local Wikipedia that is absent from the standard variant. However, little is known about how well LLMs perform under such information asymmetry, especially on closely related languages. We manually construct a novel challenge question-answering (QA) dataset that captures knowledge conveyed on a local Wikipedia page, which is absent from their higher-resource counterparts-covering Mandarin Chinese vs. Cantonese and German vs. Bavarian. Our experiments show that LLMs fail to answer questions about information only in local editions of Wikipedia. Providing context from lead sections substantially improves performance, with further gains possible via translation. Our topical, geographic annotations, and stratified evaluations reveal the usefulness of local Wikipedia editions as sources of both regional and global information. These findings raise critical questions about inclusivity and cultural coverage of LLMs.
Understanding In-Context Machine Translation for Low-Resource Languages: A Case Study on Manchu
Feb 17, 2025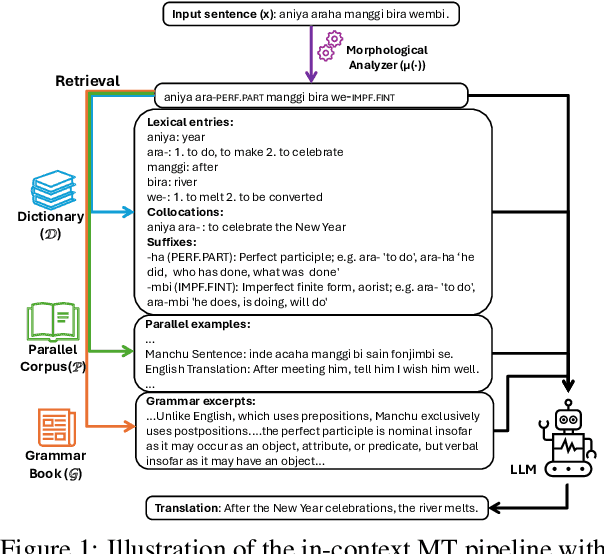
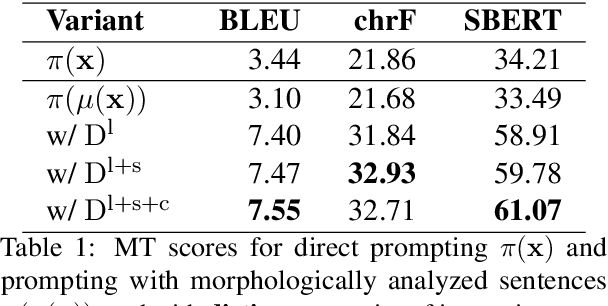
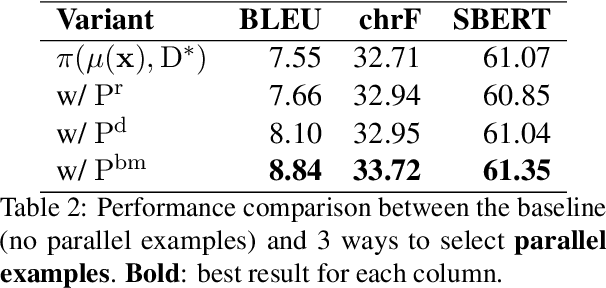
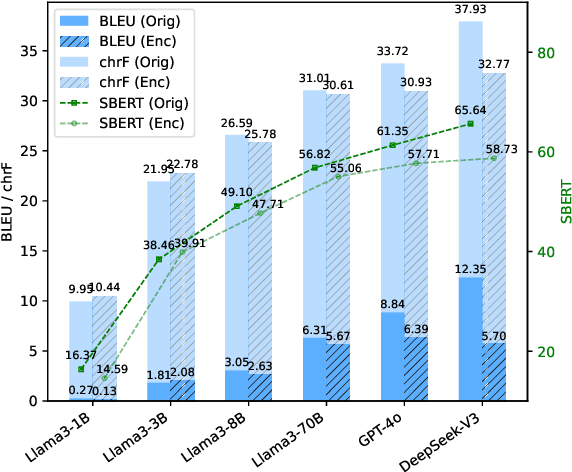
In-context machine translation (MT) with large language models (LLMs) is a promising approach for low-resource MT, as it can readily take advantage of linguistic resources such as grammar books and dictionaries. Such resources are usually selectively integrated into the prompt so that LLMs can directly perform translation without any specific training, via their in-context learning capability (ICL). However, the relative importance of each type of resource e.g., dictionary, grammar book, and retrieved parallel examples, is not entirely clear. To address this gap, this study systematically investigates how each resource and its quality affects the translation performance, with the Manchu language as our case study. To remove any prior knowledge of Manchu encoded in the LLM parameters and single out the effect of ICL, we also experiment with an encrypted version of Manchu texts. Our results indicate that high-quality dictionaries and good parallel examples are very helpful, while grammars hardly help. In a follow-up study, we showcase a promising application of in-context MT: parallel data augmentation as a way to bootstrap the conventional MT model. When monolingual data abound, generating synthetic parallel data through in-context MT offers a pathway to mitigate data scarcity and build effective and efficient low-resource neural MT systems.
A Crosslingual Investigation of Conceptualization in 1335 Languages
May 15, 2023



Languages differ in how they divide up the world into concepts and words; e.g., in contrast to English, Swahili has a single concept for `belly' and `womb'. We investigate these differences in conceptualization across 1,335 languages by aligning concepts in a parallel corpus. To this end, we propose Conceptualizer, a method that creates a bipartite directed alignment graph between source language concepts and sets of target language strings. In a detailed linguistic analysis across all languages for one concept (`bird') and an evaluation on gold standard data for 32 Swadesh concepts, we show that Conceptualizer has good alignment accuracy. We demonstrate the potential of research on conceptualization in NLP with two experiments. (1) We define crosslingual stability of a concept as the degree to which it has 1-1 correspondences across languages, and show that concreteness predicts stability. (2) We represent each language by its conceptualization pattern for 83 concepts, and define a similarity measure on these representations. The resulting measure for the conceptual similarity of two languages is complementary to standard genealogical, typological, and surface similarity measures. For four out of six language families, we can assign languages to their correct family based on conceptual similarity with accuracy between 54\% and 87\%.