 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsync Learned User Embeddings for Ads Delivery Optimization
Jun 09, 2024



User representation is crucial for recommendation systems as it helps to deliver personalized recommendations by capturing user preferences and behaviors in low-dimensional vectors. High-quality user embeddings can capture subtle preferences, enable precise similarity calculations, and adapt to changing preferences over time to maintain relevance. The effectiveness of recommendation systems depends significantly on the quality of user embedding. We propose to asynchronously learn high fidelity user embeddings for billions of users each day from sequence based multimodal user activities in Meta platforms through a Transformer-like large scale feature learning module. The async learned user representations embeddings (ALURE) are further converted to user similarity graphs through graph learning and then combined with user realtime activities to retrieval highly related ads candidates for the entire ads delivery system. Our method shows significant gains in both offline and online experiments.
Densifying Assumed-sparse Tensors: Improving Memory Efficiency and MPI Collective Performance during Tensor Accumulation for Parallelized Training of Neural Machine Translation Models
May 10, 2019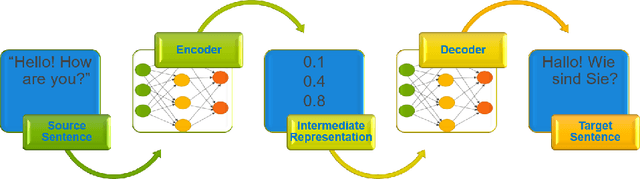

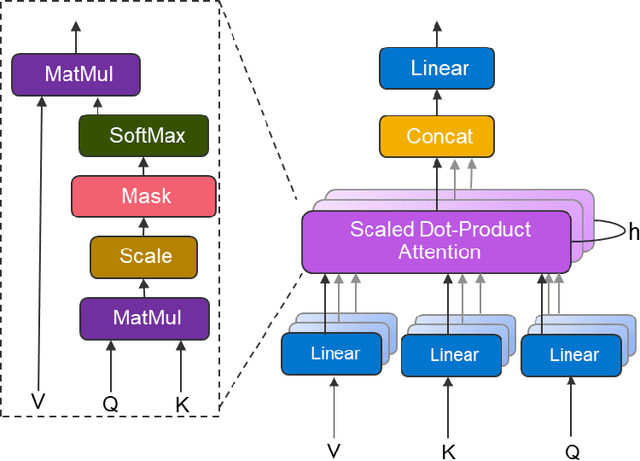

Neural machine translation - using neural networks to translate human language - is an area of active research exploring new neuron types and network topologies with the goal of dramatically improving machine translation performance. Current state-of-the-art approaches, such as the multi-head attention-based transformer, require very large translation corpuses and many epochs to produce models of reasonable quality. Recent attempts to parallelize the official TensorFlow "Transformer" model across multiple nodes have hit roadblocks due to excessive memory use and resulting out of memory errors when performing MPI collectives. This paper describes modifications made to the Horovod MPI-based distributed training framework to reduce memory usage for transformer models by converting assumed-sparse tensors to dense tensors, and subsequently replacing sparse gradient gather with dense gradient reduction. The result is a dramatic increase in scale-out capability, with CPU-only scaling tests achieving 91% weak scaling efficiency up to 1200 MPI processes (300 nodes), and up to 65% strong scaling efficiency up to 400 MPI processes (200 nodes) using the Stampede2 supercomputer.