 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePure Exploration in Kernel and Neural Bandits
Jun 22, 2021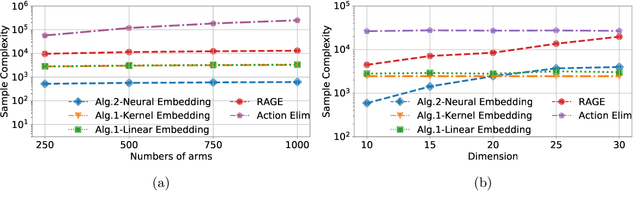

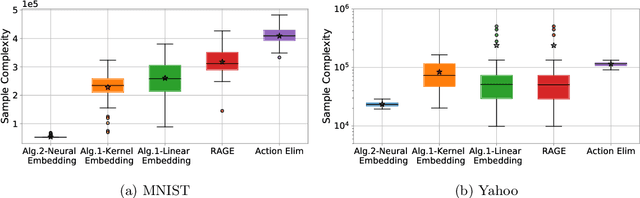
We study pure exploration in bandits, where the dimension of the feature representation can be much larger than the number of arms. To overcome the curse of dimensionality, we propose to adaptively embed the feature representation of each arm into a lower-dimensional space and carefully deal with the induced model misspecifications. Our approach is conceptually very different from existing works that can either only handle low-dimensional linear bandits or passively deal with model misspecifications. We showcase the application of our approach to two pure exploration settings that were previously under-studied: (1) the reward function belongs to a possibly infinite-dimensional Reproducing Kernel Hilbert Space, and (2) the reward function is nonlinear and can be approximated by neural networks. Our main results provide sample complexity guarantees that only depend on the effective dimension of the feature spaces in the kernel or neural representations. Extensive experiments conducted on both synthetic and real-world datasets demonstrate the efficacy of our methods.
Prediction in the presence of response-dependent missing labels
Mar 25, 2021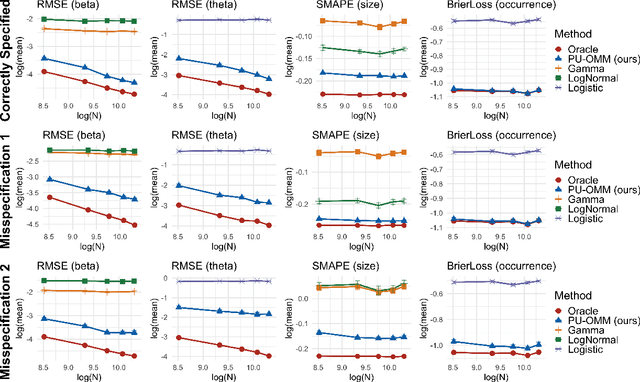
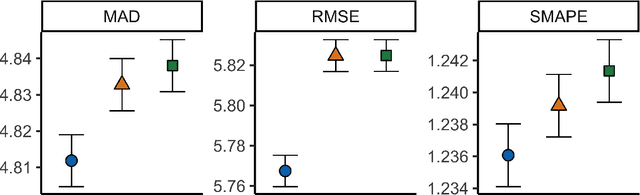
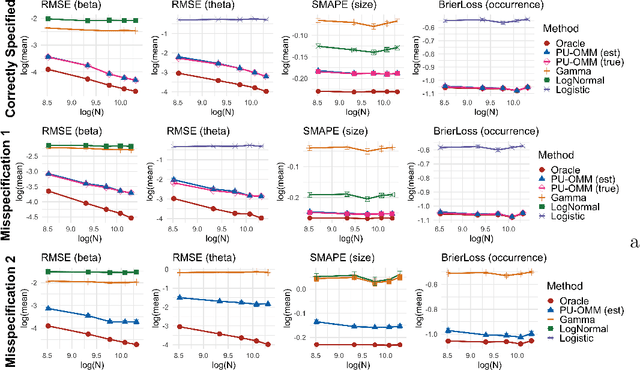
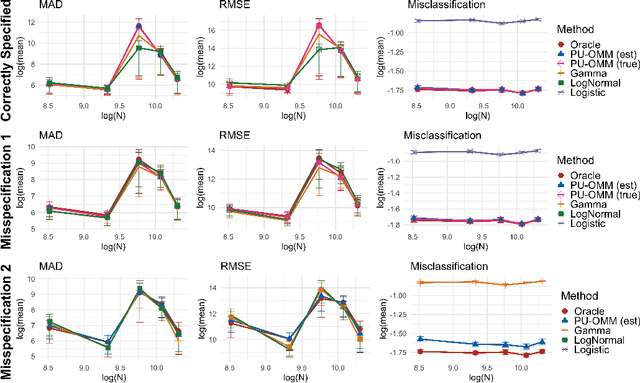
In a variety of settings, limitations of sensing technologies or other sampling mechanisms result in missing labels, where the likelihood of a missing label in the training set is an unknown function of the data. For example, satellites used to detect forest fires cannot sense fires below a certain size threshold. In such cases, training datasets consist of positive and pseudo-negative observations where pseudo-negative observations can be either true negatives or undetected positives with small magnitudes. We develop a new methodology and non-convex algorithm P(ositive) U(nlabeled) - O(ccurrence) M(agnitude) M(ixture) which jointly estimates the occurrence and detection likelihood of positive samples, utilizing prior knowledge of the detection mechanism. Our approach uses ideas from positive-unlabeled (PU)-learning and zero-inflated models that jointly estimate the magnitude and occurrence of events. We provide conditions under which our model is identifiable and prove that even though our approach leads to a non-convex objective, any local minimizer has optimal statistical error (up to a log term) and projected gradient descent has geometric convergence rates. We demonstrate on both synthetic data and a California wildfire dataset that our method out-performs existing state-of-the-art approaches.
Data-driven Cloud Clustering via a Rotationally Invariant Autoencoder
Mar 08, 2021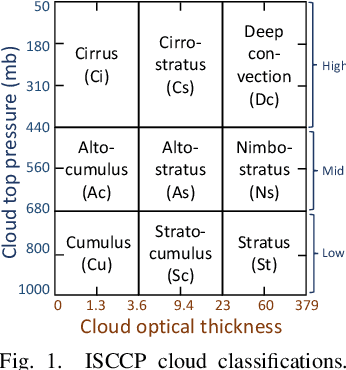


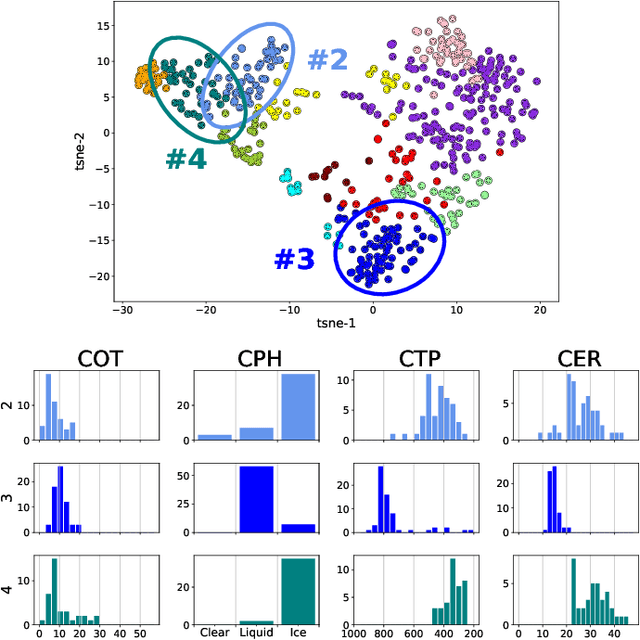
Advanced satellite-born remote sensing instruments produce high-resolution multi-spectral data for much of the globe at a daily cadence. These datasets open up the possibility of improved understanding of cloud dynamics and feedback, which remain the biggest source of uncertainty in global climate model projections. As a step towards answering these questions, we describe an automated rotation-invariant cloud clustering (RICC) method that leverages deep learning autoencoder technology to organize cloud imagery within large datasets in an unsupervised fashion, free from assumptions about predefined classes. We describe both the design and implementation of this method and its evaluation, which uses a sequence of testing protocols to determine whether the resulting clusters: (1) are physically reasonable, (i.e., embody scientifically relevant distinctions); (2) capture information on spatial distributions, such as textures; (3) are cohesive and separable in latent space; and (4) are rotationally invariant, (i.e., insensitive to the orientation of an image). Results obtained when these evaluation protocols are applied to RICC outputs suggest that the resultant novel cloud clusters capture meaningful aspects of cloud physics, are appropriately spatially coherent, and are invariant to orientations of input images. Our results support the possibility of using an unsupervised data-driven approach for automated clustering and pattern discovery in cloud imagery.
Deep Equilibrium Architectures for Inverse Problems in Imaging
Feb 16, 2021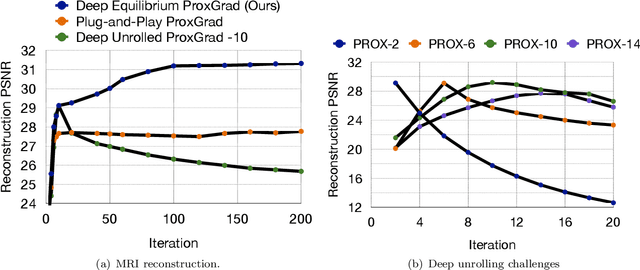
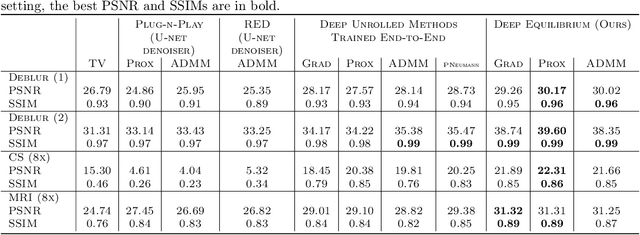
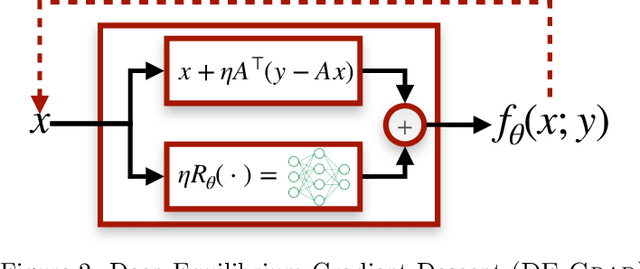
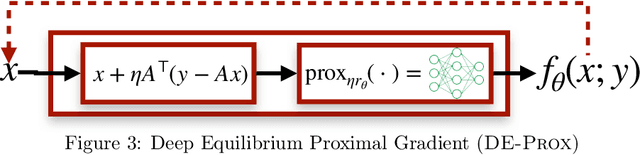
Recent efforts on solving inverse problems in imaging via deep neural networks use architectures inspired by a fixed number of iterations of an optimization method. The number of iterations is typically quite small due to difficulties in training networks corresponding to more iterations; the resulting solvers cannot be run for more iterations at test time without incurring significant errors. This paper describes an alternative approach corresponding to an {\em infinite} number of iterations, yielding up to a 4dB PSNR improvement in reconstruction accuracy above state-of-the-art alternatives and where the computational budget can be selected at test time to optimize context-dependent trade-offs between accuracy and computation. The proposed approach leverages ideas from Deep Equilibrium Models, where the fixed-point iteration is constructed to incorporate a known forward model and insights from classical optimization-based reconstruction methods.
Model Adaptation for Inverse Problems in Imaging
Nov 30, 2020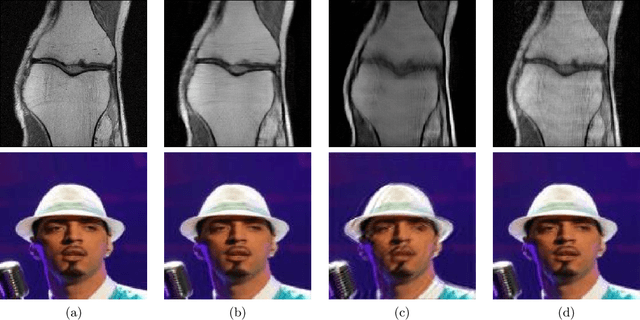

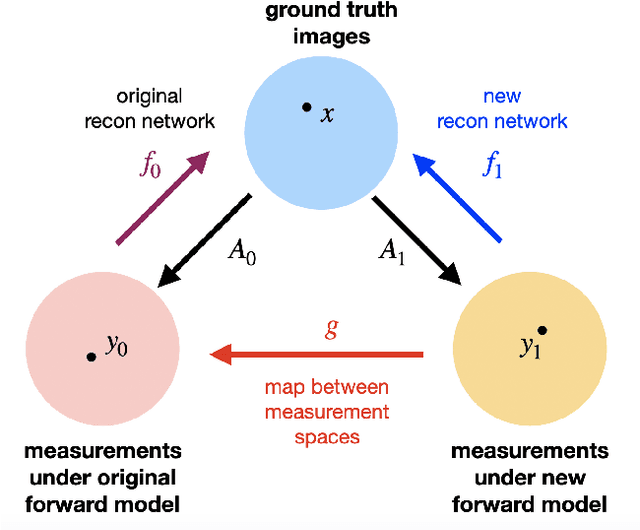

Deep neural networks have been applied successfully to a wide variety of inverse problems arising in computational imaging. These networks are typically trained using a forward model that describes the measurement process to be inverted, which is often incorporated directly into the network itself. However, these approaches lack robustness to drift of the forward model: if at test time the forward model varies (even slightly) from the one the network was trained for, the reconstruction performance can degrade substantially. Given a network trained to solve an initial inverse problem with a known forward model, we propose two novel procedures that adapt the network to a perturbed forward model, even without full knowledge of the perturbation. Our approaches do not require access to more labeled data (i.e., ground truth images), but only a small set of calibration measurements. We show these simple model adaptation procedures empirically achieve robustness to changes in the forward model in a variety of settings, including deblurring, super-resolution, and undersampled image reconstruction in magnetic resonance imaging.
Deep Learning Techniques for Inverse Problems in Imaging
May 12, 2020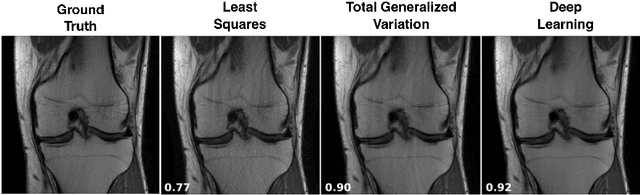
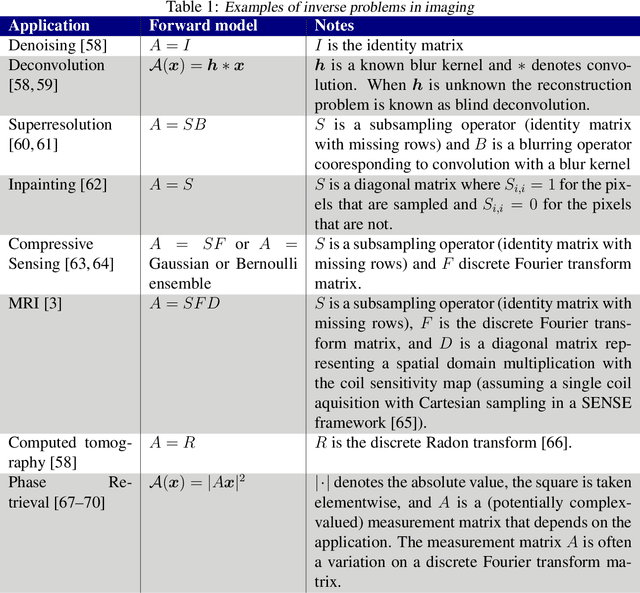

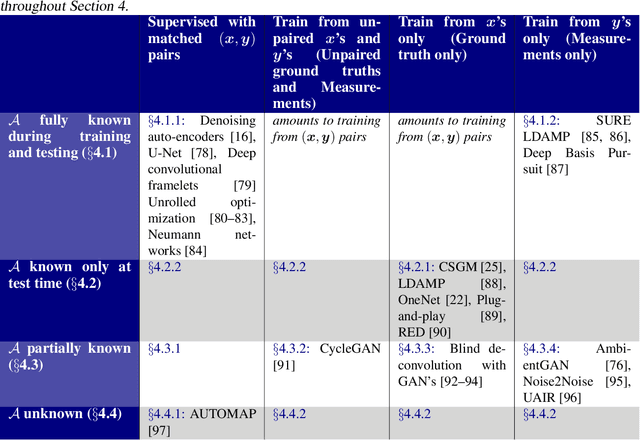
Recent work in machine learning shows that deep neural networks can be used to solve a wide variety of inverse problems arising in computational imaging. We explore the central prevailing themes of this emerging area and present a taxonomy that can be used to categorize different problems and reconstruction methods. Our taxonomy is organized along two central axes: (1) whether or not a forward model is known and to what extent it is used in training and testing, and (2) whether or not the learning is supervised or unsupervised, i.e., whether or not the training relies on access to matched ground truth image and measurement pairs. We also discuss the trade-offs associated with these different reconstruction approaches, caveats and common failure modes, plus open problems and avenues for future work.
Detection and Description of Change in Visual Streams
Apr 09, 2020
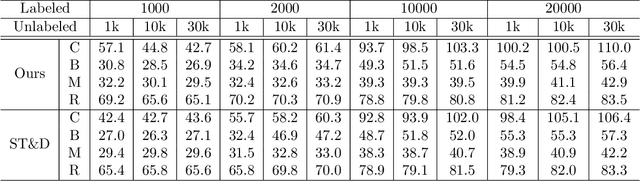

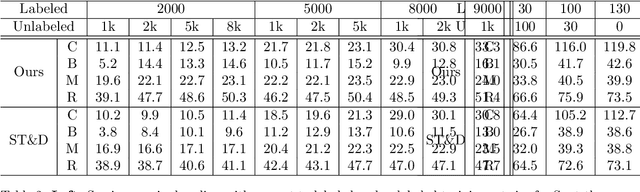
This paper presents a framework for the analysis of changes in visual streams: ordered sequences of images, possibly separated by significant time gaps. We propose a new approach to incorporating unlabeled data into training to generate natural language descriptions of change. We also develop a framework for estimating the time of change in visual stream. We use learned representations for change evidence and consistency of perceived change, and combine these in a regularized graph cut based change detector. Experimental evaluation on visual stream datasets, which we release as part of our contribution, shows that representation learning driven by natural language descriptions significantly improves change detection accuracy, compared to methods that do not rely on language.
Context-dependent self-exciting point processes: models, methods, and risk bounds in high dimensions
Mar 16, 2020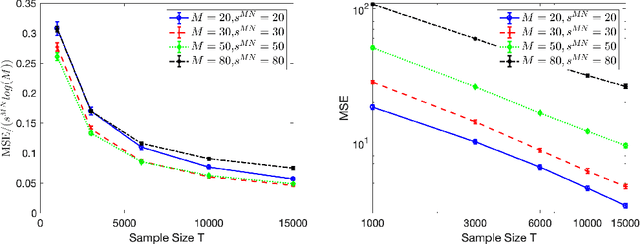
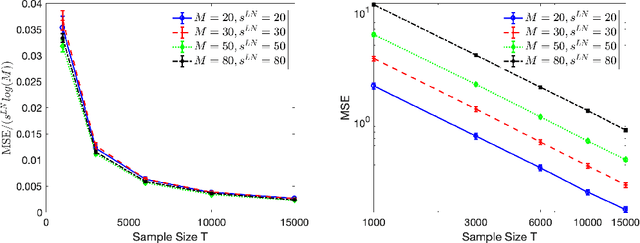
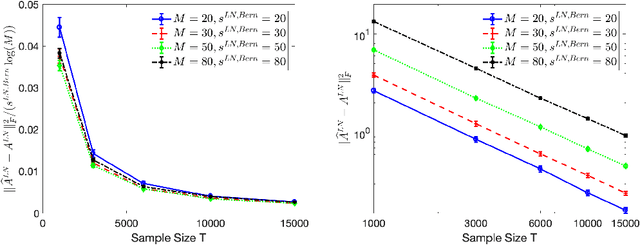
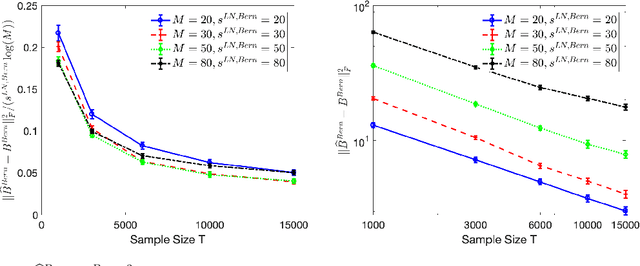
High-dimensional autoregressive point processes model how current events trigger or inhibit future events, such as activity by one member of a social network can affect the future activity of his or her neighbors. While past work has focused on estimating the underlying network structure based solely on the times at which events occur on each node of the network, this paper examines the more nuanced problem of estimating context-dependent networks that reflect how features associated with an event (such as the content of a social media post) modulate the strength of influences among nodes. Specifically, we leverage ideas from compositional time series and regularization methods in machine learning to conduct network estimation for high-dimensional marked point processes. Two models and corresponding estimators are considered in detail: an autoregressive multinomial model suited to categorical marks and a logistic-normal model suited to marks with mixed membership in different categories. Importantly, the logistic-normal model leads to a convex negative log-likelihood objective and captures dependence across categories. We provide theoretical guarantees for both estimators, which we validate by simulations and a synthetic data-generating model. We further validate our methods through two real data examples and demonstrate the advantages and disadvantages of both approaches.
An Optimal Statistical and Computational Framework for Generalized Tensor Estimation
Feb 26, 2020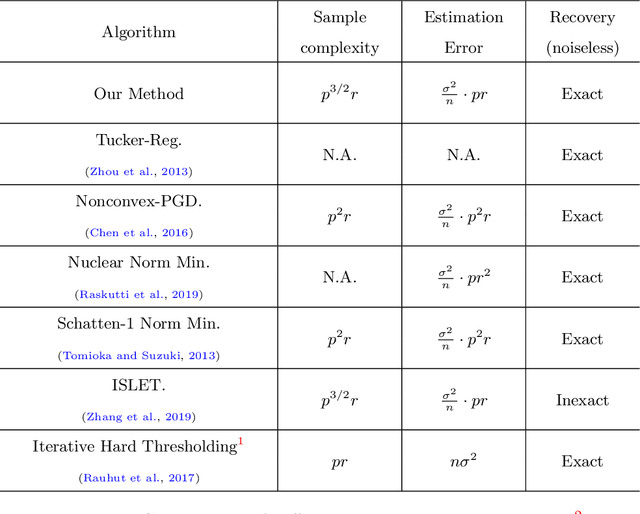
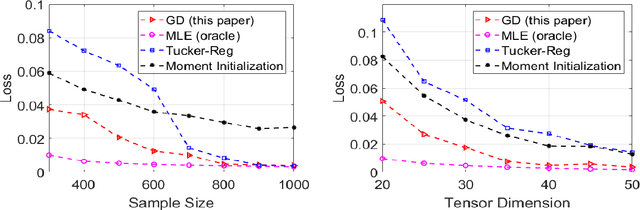
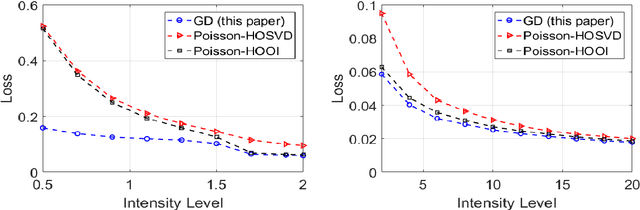
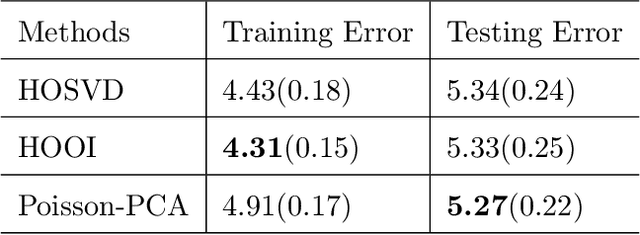
This paper describes a flexible framework for generalized low-rank tensor estimation problems that includes many important instances arising from applications in computational imaging, genomics, and network analysis. The proposed estimator consists of finding a low-rank tensor fit to the data under generalized parametric models. To overcome the difficulty of non-convexity in these problems, we introduce a unified approach of projected gradient descent that adapts to the underlying low-rank structure. Under mild conditions on the loss function, we establish both an upper bound on statistical error and the linear rate of computational convergence through a general deterministic analysis. Then we further consider a suite of generalized tensor estimation problems, including sub-Gaussian tensor denoising, tensor regression, and Poisson and binomial tensor PCA. We prove that the proposed algorithm achieves the minimax optimal rate of convergence in estimation error. Finally, we demonstrate the superiority of the proposed framework via extensive experiments on both simulated and real data.
A Function Space View of Bounded Norm Infinite Width ReLU Nets: The Multivariate Case
Oct 03, 2019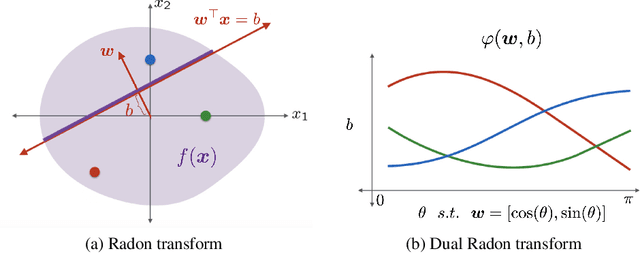
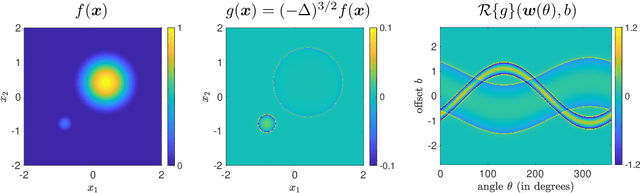
A key element of understanding the efficacy of overparameterized neural networks is characterizing how they represent functions as the number of weights in the network approaches infinity. In this paper, we characterize the norm required to realize a function $f:\mathbb{R}^d\rightarrow\mathbb{R}$ as a single hidden-layer ReLU network with an unbounded number of units (infinite width), but where the Euclidean norm of the weights is bounded, including precisely characterizing which functions can be realized with finite norm. This was settled for univariate univariate functions in Savarese et al. (2019), where it was shown that the required norm is determined by the L1-norm of the second derivative of the function. We extend the characterization to multivariate functions (i.e., networks with d input units), relating the required norm to the L1-norm of the Radon transform of a (d+1)/2-power Laplacian of the function. This characterization allows us to show that all functions in Sobolev spaces $W^{s,1}(\mathbb{R})$, $s\geq d+1$, can be represented with bounded norm, to calculate the required norm for several specific functions, and to obtain a depth separation result. These results have important implications for understanding generalization performance and the distinction between neural networks and more traditional kernel learning.