 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Generate Code Comments from Class Hierarchies
Apr 17, 2021
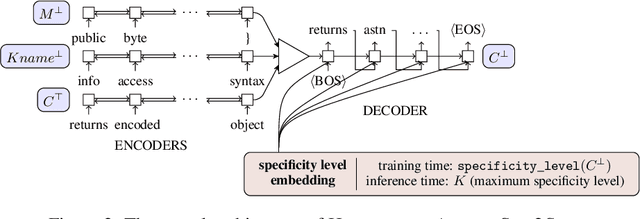

Descriptive code comments are essential for supporting code comprehension and maintenance. We propose the task of automatically generating comments for overriding methods. We formulate a novel framework which accommodates the unique contextual and linguistic reasoning that is required for performing this task. Our approach features: (1) incorporating context from the class hierarchy; (2) conditioning on learned, latent representations of specificity to generate comments that capture the more specialized behavior of the overriding method; and (3) unlikelihood training to discourage predictions which do not conform to invariant characteristics of the comment corresponding to the overridden method. Our experiments show that the proposed approach is able to generate comments for overriding methods of higher quality compared to prevailing comment generation techniques.
Systematic Generalization on gSCAN with Language Conditioned Embedding
Oct 04, 2020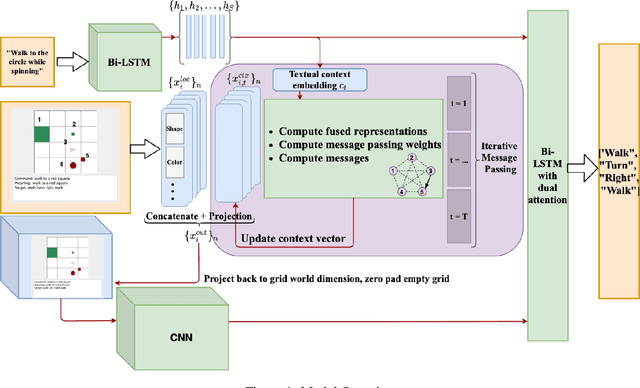
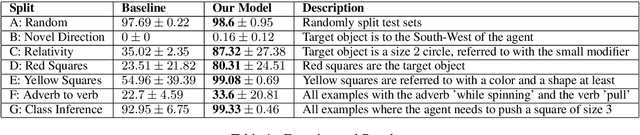

Systematic Generalization refers to a learning algorithm's ability to extrapolate learned behavior to unseen situations that are distinct but semantically similar to its training data. As shown in recent work, state-of-the-art deep learning models fail dramatically even on tasks for which they are designed when the test set is systematically different from the training data. We hypothesize that explicitly modeling the relations between objects in their contexts while learning their representations will help achieve systematic generalization. Therefore, we propose a novel method that learns objects' contextualized embeddings with dynamic message passing conditioned on the input natural language and end-to-end trainable with other downstream deep learning modules. To our knowledge, this model is the first one that significantly outperforms the provided baseline and reaches state-of-the-art performance on grounded-SCAN (gSCAN), a grounded natural language navigation dataset designed to require systematic generalization in its test splits.
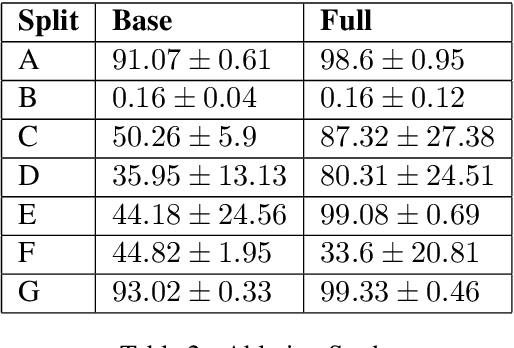
Deep Just-In-Time Inconsistency Detection Between Comments and Source Code
Oct 04, 2020
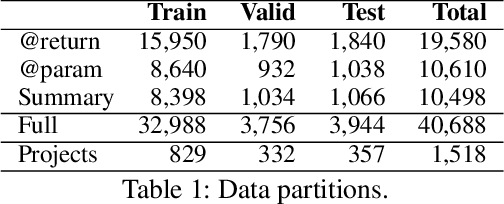
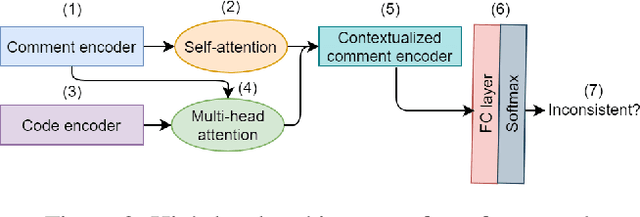
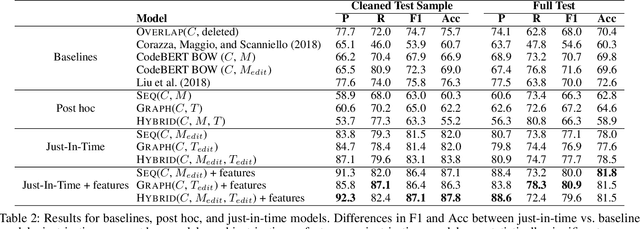
Natural language comments convey key aspects of source code such as implementation, usage, and pre- and post-conditions. Failure to update comments accordingly when the corresponding code is modified introduces inconsistencies, which is known to lead to confusion and software bugs. In this paper, we aim to detect whether a comment becomes inconsistent as a result of changes to the corresponding body of code, in order to catch potential inconsistencies just-in-time, i.e., before they are committed to a version control system. To achieve this, we develop a deep-learning approach that learns to correlate a comment with code changes. By evaluating on a large corpus of comment/code pairs spanning various comment types, we show that our model outperforms multiple baselines by significant margins. For extrinsic evaluation, we show the usefulness of our approach by combining it with a comment update model to build a more comprehensive automatic comment maintenance system which can both detect and resolve inconsistent comments based on code changes.
PixL2R: Guiding Reinforcement Learning Using Natural Language by Mapping Pixels to Rewards
Jul 30, 2020
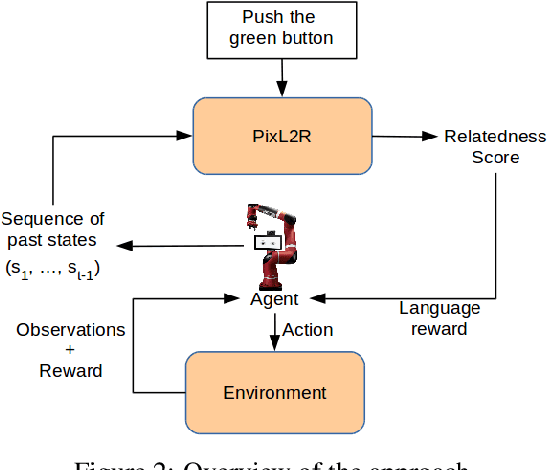
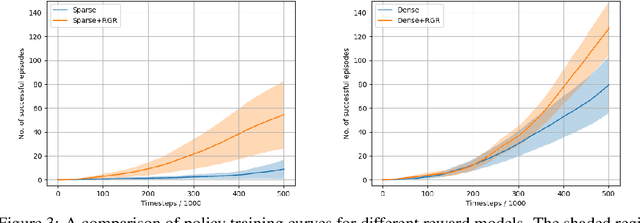
Reinforcement learning (RL), particularly in sparse reward settings, often requires prohibitively large numbers of interactions with the environment, thereby limiting its applicability to complex problems. To address this, several prior approaches have used natural language to guide the agent's exploration. However, these approaches typically operate on structured representations of the environment, and/or assume some structure in the natural language commands. In this work, we propose a model that directly maps pixels to rewards, given a free-form natural language description of the task, which can then be used for policy learning. Our experiments on the Meta-World robot manipulation domain show that language-based rewards significantly improves the sample efficiency of policy learning, both in sparse and dense reward settings.
Improving VQA and its Explanations \\ by Comparing Competing Explanations
Jun 28, 2020
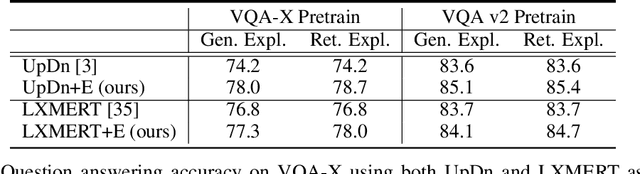
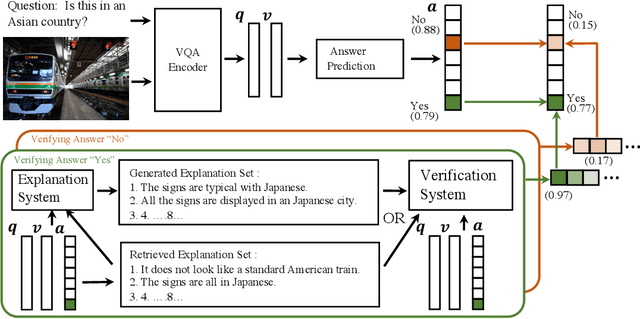

Most recent state-of-the-art Visual Question Answering (VQA) systems are opaque black boxes that are only trained to fit the answer distribution given the question and visual content. As a result, these systems frequently take shortcuts, focusing on simple visual concepts or question priors. This phenomenon becomes more problematic as the questions become complex that requires more reasoning and commonsense knowledge. To address this issue, we present a novel framework that uses explanations for competing answers to help VQA systems select the correct answer. By training on human textual explanations, our framework builds better representations for the questions and visual content, and then reweights confidences in the answer candidates using either generated or retrieved explanations from the training set. We evaluate our framework on the VQA-X dataset, which has more difficult questions with human explanations, achieving new state-of-the-art results on both VQA and its explanations.
Dialog as a Vehicle for Lifelong Learning
Jun 26, 2020Dialog systems research has primarily been focused around two main types of applications - task-oriented dialog systems that learn to use clarification to aid in understanding a goal, and open-ended dialog systems that are expected to carry out unconstrained "chit chat" conversations. However, dialog interactions can also be used to obtain various types of knowledge that can be used to improve an underlying language understanding system, or other machine learning systems that the dialog acts over. In this position paper, we present the problem of designing dialog systems that enable lifelong learning as an important challenge problem, in particular for applications involving physically situated robots. We include examples of prior work in this direction, and discuss challenges that remain to be addressed.
Dialog Policy Learning for Joint Clarification and Active Learning Queries
Jun 09, 2020
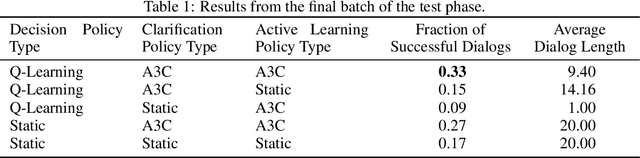

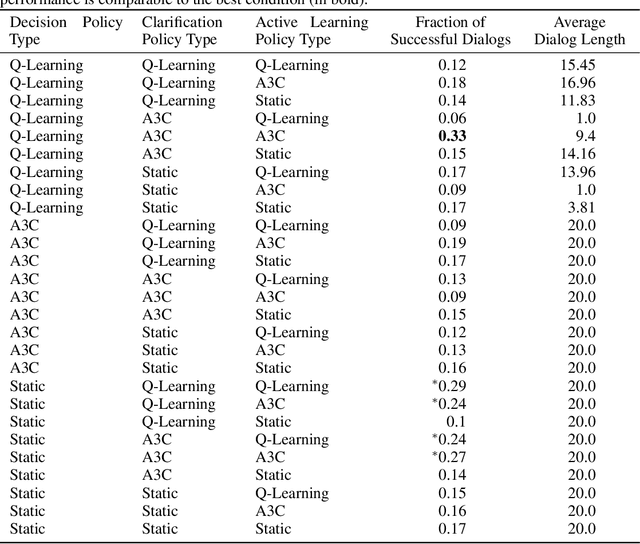
Intelligent systems need to be able to recover from mistakes, resolve uncertainty, and adapt to novel concepts not seen during training. Dialog interaction can enable this by the use of clarifications for correction and resolving uncertainty, and active learning queries to learn new concepts encountered during operation. Prior work on dialog systems has either focused on exclusively learning how to perform clarification/ information seeking, or to perform active learning. In this work, we train a hierarchical dialog policy to jointly perform {\it both} clarification and active learning in the context of an interactive language-based image retrieval task motivated by an on-line shopping application, and demonstrate that jointly learning dialog policies for clarification and active learning is more effective than the use of static dialog policies for one or both of these functions.
Learning to Update Natural Language Comments Based on Code Changes
Apr 28, 2020
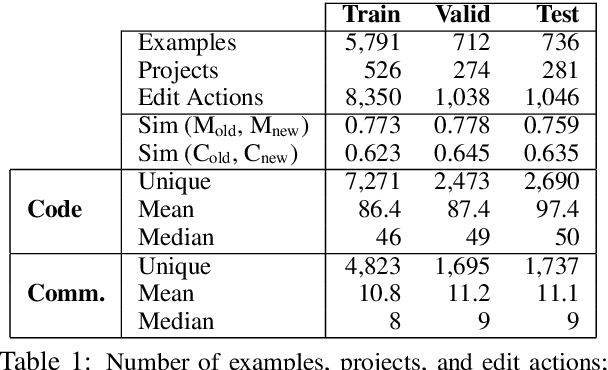
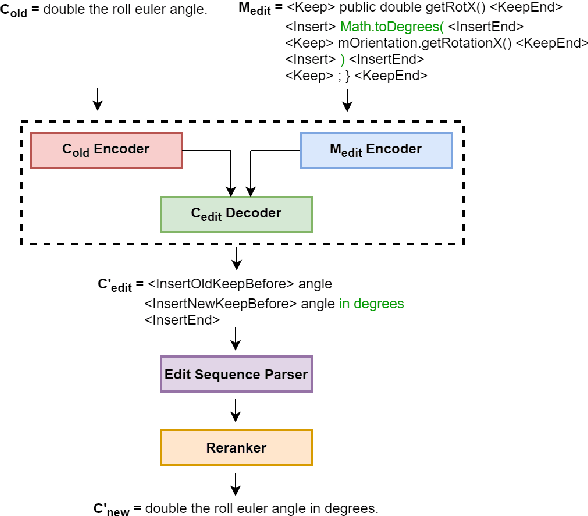
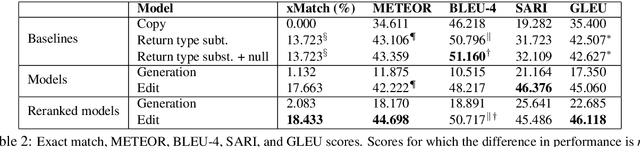
We formulate the novel task of automatically updating an existing natural language comment based on changes in the body of code it accompanies. We propose an approach that learns to correlate changes across two distinct language representations, to generate a sequence of edits that are applied to the existing comment to reflect the source code modifications. We train and evaluate our model using a dataset that we collected from commit histories of open-source software projects, with each example consisting of a concurrent update to a method and its corresponding comment. We compare our approach against multiple baselines using both automatic metrics and human evaluation. Results reflect the challenge of this task and that our model outperforms baselines with respect to making edits.
Associating Natural Language Comment and Source Code Entities
Dec 13, 2019
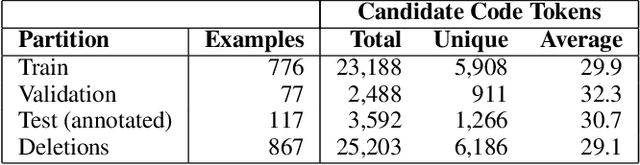
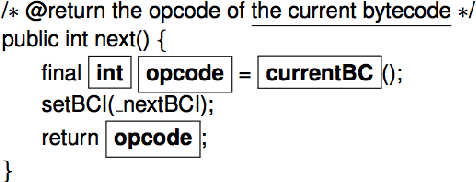
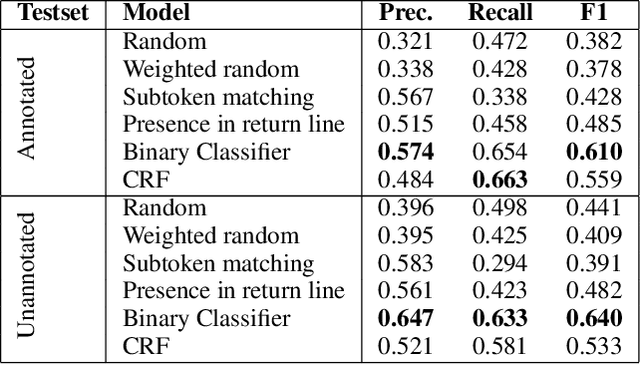
Comments are an integral part of software development; they are natural language descriptions associated with source code elements. Understanding explicit associations can be useful in improving code comprehensibility and maintaining the consistency between code and comments. As an initial step towards this larger goal, we address the task of associating entities in Javadoc comments with elements in Java source code. We propose an approach for automatically extracting supervised data using revision histories of open source projects and present a manually annotated evaluation dataset for this task. We develop a binary classifier and a sequence labeling model by crafting a rich feature set which encompasses various aspects of code, comments, and the relationships between them. Experiments show that our systems outperform several baselines learning from the proposed supervision.
Hidden State Guidance: Improving Image Captioning using An Image Conditioned Autoencoder
Oct 31, 2019
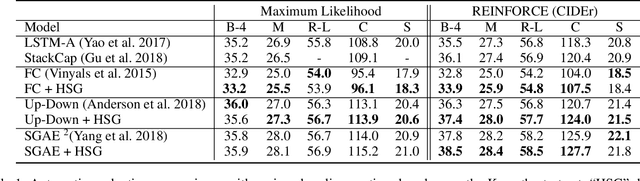
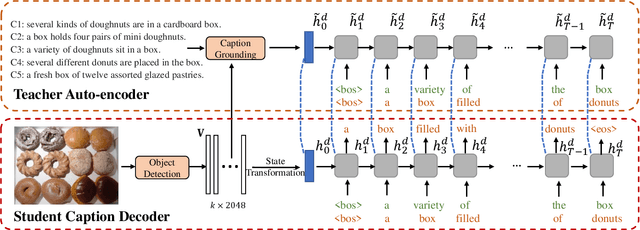
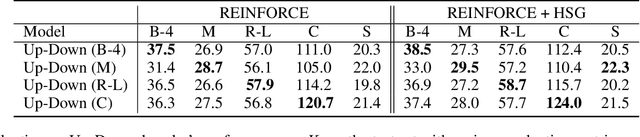
Most RNN-based image captioning models receive supervision on the output words to mimic human captions. Therefore, the hidden states can only receive noisy gradient signals via layers of back-propagation through time, leading to less accurate generated captions. Consequently, we propose a novel framework, Hidden State Guidance (HSG), that matches the hidden states in the caption decoder to those in a teacher decoder trained on an easier task of autoencoding the captions conditioned on the image. During training with the REINFORCE algorithm, the conventional rewards are sentence-based evaluation metrics equally distributed to each generated word, no matter their relevance. HSG provides a word-level reward that helps the model learn better hidden representations. Experimental results demonstrate that HSG clearly outperforms various state-of-the-art caption decoders using either raw images, detected objects, or scene graph features as inputs.