 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe EMory BrEast imaging Dataset : A Racially Diverse, Granular Dataset of 3.5M Screening and Diagnostic Mammograms
Feb 08, 2022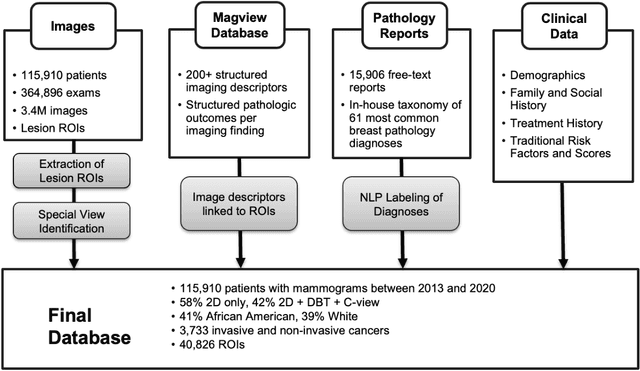
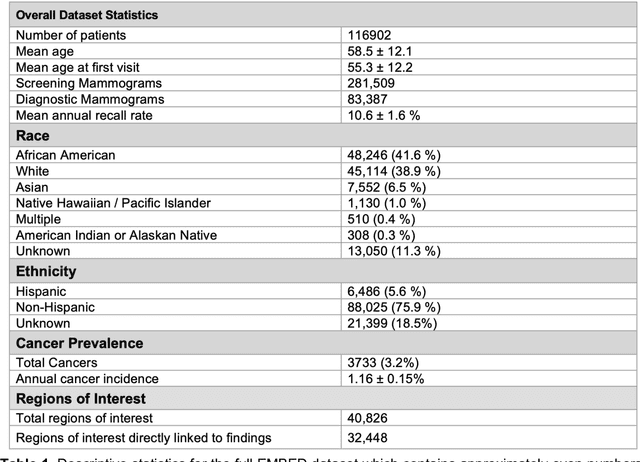
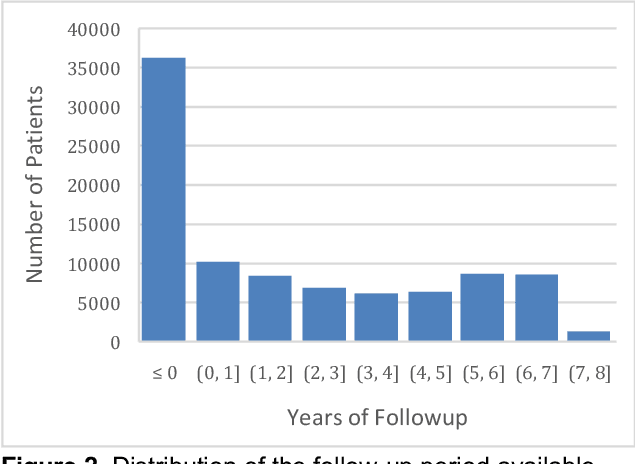

Developing and validating artificial intelligence models in medical imaging requires datasets that are large, granular, and diverse. To date, the majority of publicly available breast imaging datasets lack in one or more of these areas. Models trained on these data may therefore underperform on patient populations or pathologies that have not previously been encountered. The EMory BrEast imaging Dataset (EMBED) addresses these gaps by providing 3650,000 2D and DBT screening and diagnostic mammograms for 116,000 women divided equally between White and African American patients. The dataset also contains 40,000 annotated lesions linked to structured imaging descriptors and 61 ground truth pathologic outcomes grouped into six severity classes. Our goal is to share this dataset with research partners to aid in development and validation of breast AI models that will serve all patients fairly and help decrease bias in medical AI.
Two-step adversarial debiasing with partial learning -- medical image case-studies
Nov 16, 2021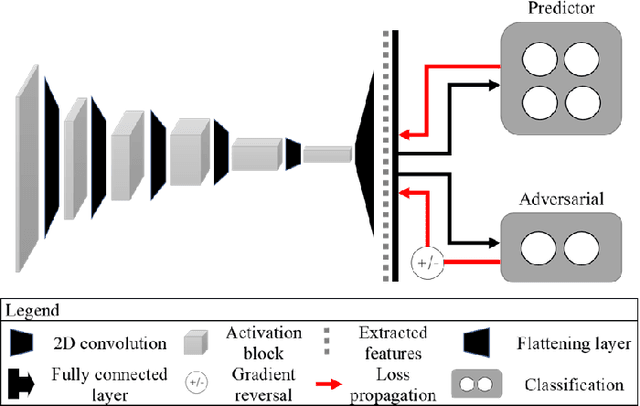
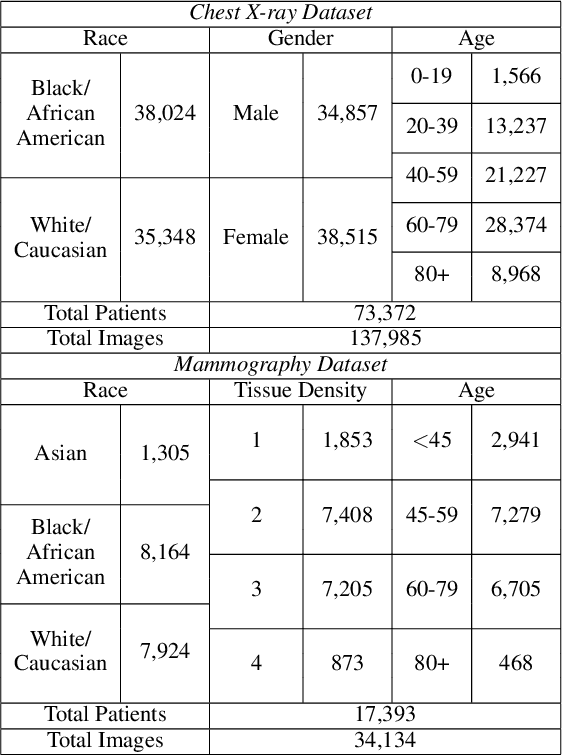
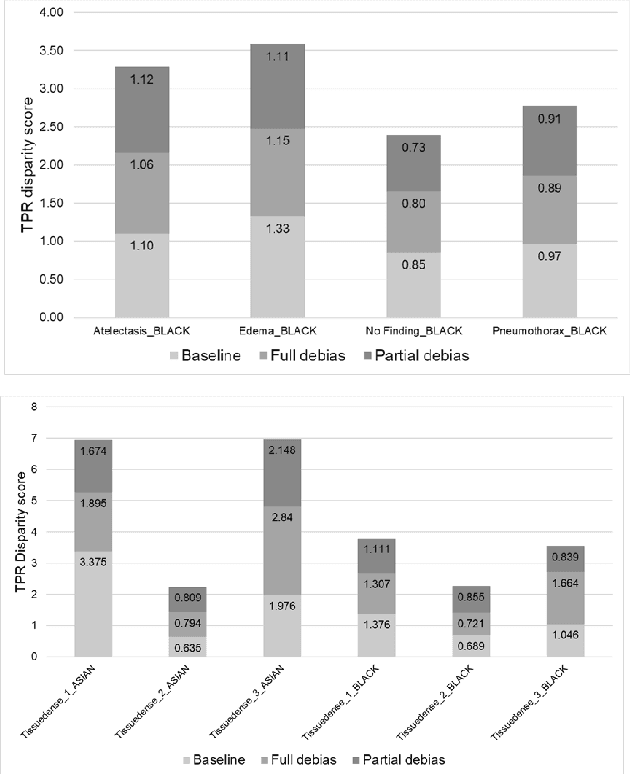
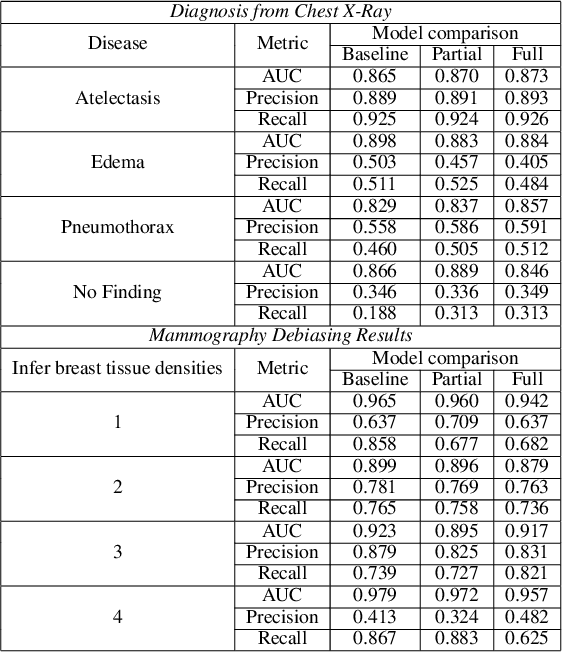
The use of artificial intelligence (AI) in healthcare has become a very active research area in the last few years. While significant progress has been made in image classification tasks, only a few AI methods are actually being deployed in hospitals. A major hurdle in actively using clinical AI models currently is the trustworthiness of these models. More often than not, these complex models are black boxes in which promising results are generated. However, when scrutinized, these models begin to reveal implicit biases during the decision making, such as detecting race and having bias towards ethnic groups and subpopulations. In our ongoing study, we develop a two-step adversarial debiasing approach with partial learning that can reduce the racial disparity while preserving the performance of the targeted task. The methodology has been evaluated on two independent medical image case-studies - chest X-ray and mammograms, and showed promises in bias reduction while preserving the targeted performance.
Reading Race: AI Recognises Patient's Racial Identity In Medical Images
Jul 21, 2021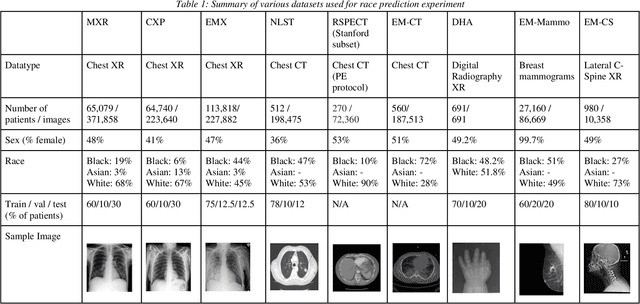
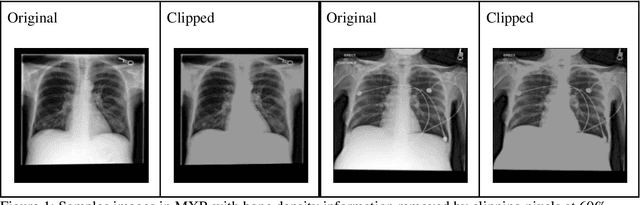
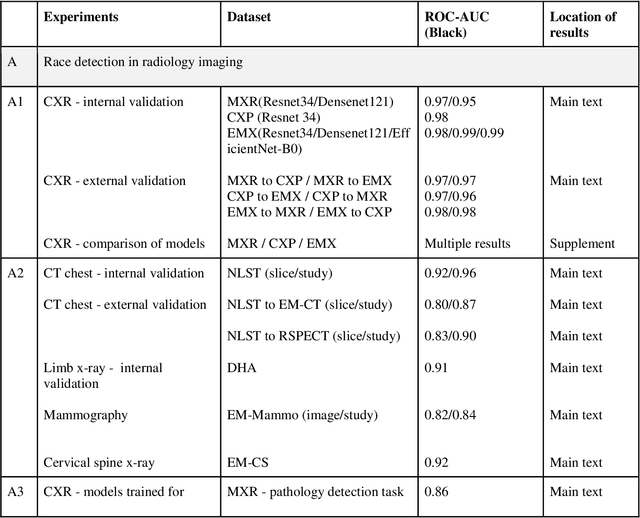
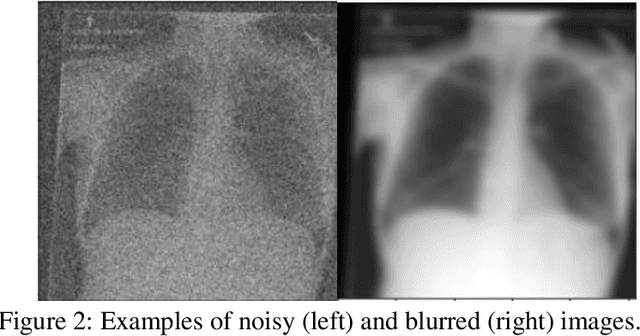
Background: In medical imaging, prior studies have demonstrated disparate AI performance by race, yet there is no known correlation for race on medical imaging that would be obvious to the human expert interpreting the images. Methods: Using private and public datasets we evaluate: A) performance quantification of deep learning models to detect race from medical images, including the ability of these models to generalize to external environments and across multiple imaging modalities, B) assessment of possible confounding anatomic and phenotype population features, such as disease distribution and body habitus as predictors of race, and C) investigation into the underlying mechanism by which AI models can recognize race. Findings: Standard deep learning models can be trained to predict race from medical images with high performance across multiple imaging modalities. Our findings hold under external validation conditions, as well as when models are optimized to perform clinically motivated tasks. We demonstrate this detection is not due to trivial proxies or imaging-related surrogate covariates for race, such as underlying disease distribution. Finally, we show that performance persists over all anatomical regions and frequency spectrum of the images suggesting that mitigation efforts will be challenging and demand further study. Interpretation: We emphasize that model ability to predict self-reported race is itself not the issue of importance. However, our findings that AI can trivially predict self-reported race -- even from corrupted, cropped, and noised medical images -- in a setting where clinical experts cannot, creates an enormous risk for all model deployments in medical imaging: if an AI model secretly used its knowledge of self-reported race to misclassify all Black patients, radiologists would not be able to tell using the same data the model has access to.
Spatial-And-Context aware (SpACe) "virtual biopsy" radiogenomic maps to target tumor mutational status on structural MRI
Jun 17, 2020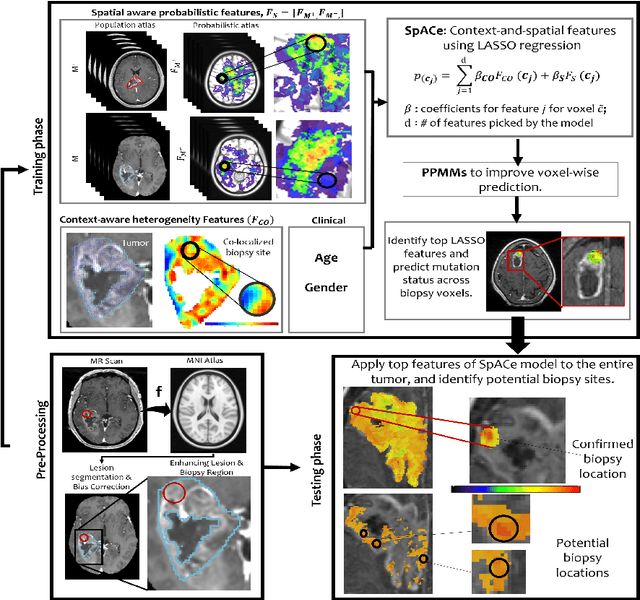
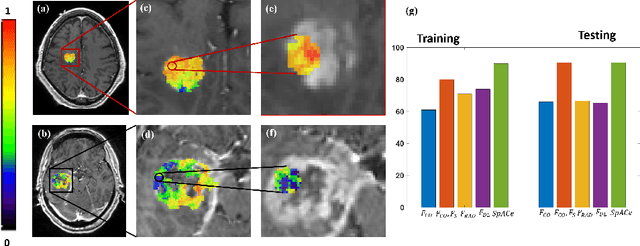
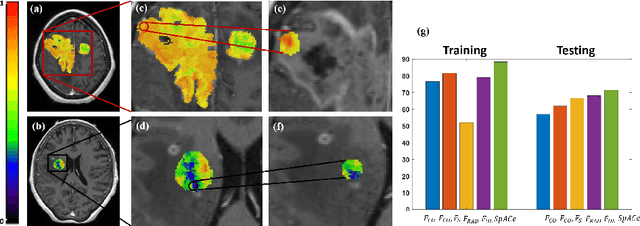
With growing emphasis on personalized cancer-therapies,radiogenomics has shown promise in identifying target tumor mutational status on routine imaging (i.e. MRI) scans. These approaches fall into 2 categories: (1) deep-learning/radiomics (context-based), using image features from the entire tumor to identify the gene mutation status, or (2) atlas (spatial)-based to obtain likelihood of gene mutation status based on population statistics. While many genes (i.e. EGFR, MGMT) are spatially variant, a significant challenge in reliable assessment of gene mutation status on imaging has been the lack of available co-localized ground truth for training the models. We present Spatial-And-Context aware (SpACe) "virtual biopsy" maps that incorporate context-features from co-localized biopsy site along with spatial-priors from population atlases, within a Least Absolute Shrinkage and Selection Operator (LASSO) regression model, to obtain a per-voxel probability of the presence of a mutation status (M+ vs M-). We then use probabilistic pair-wise Markov model to improve the voxel-wise prediction probability. We evaluate the efficacy of SpACe maps on MRI scans with co-localized ground truth obtained from corresponding biopsy, to predict the mutation status of 2 driver genes in Glioblastoma: (1) EGFR (n=91), and (2) MGMT (n=81). When compared against deep-learning (DL) and radiomic models, SpACe maps obtained training and testing accuracies of 90% (n=71) and 90.48% (n=21) in identifying EGFR amplification status,compared to 80% and 71.4% via radiomics, and 74.28% and 65.5% via DL. For MGMT status, training and testing accuracies using SpACe were 88.3% (n=61) and 71.5% (n=20), compared to 52.4% and 66.7% using radiomics,and 79.3% and 68.4% using DL. Following validation,SpACe maps could provide surgical navigation to improve localization of sampling sites for targeting of specific driver genes in cancer.
Can tumor location on pre-treatment MRI predict likelihood of pseudo-progression versus tumor recurrence in Glioblastoma? A feasibility study
Jun 16, 2020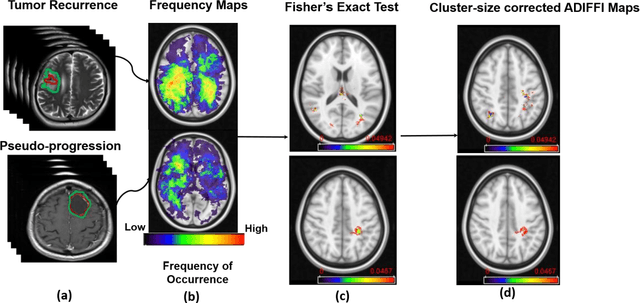

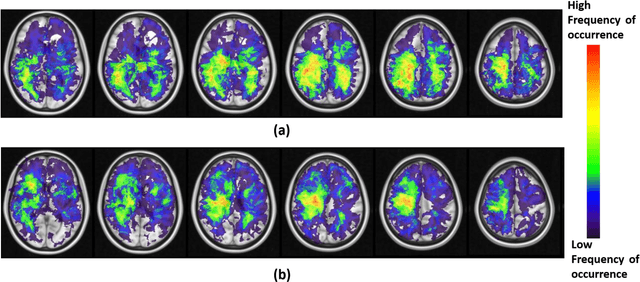
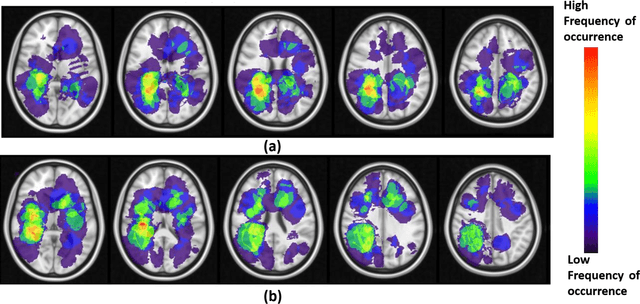
A significant challenge in Glioblastoma (GBM) management is identifying pseudo-progression (PsP), a benign radiation-induced effect, from tumor recurrence, on routine imaging following conventional treatment. Previous studies have linked tumor lobar presence and laterality to GBM outcomes, suggesting that disease etiology and progression in GBM may be impacted by tumor location. Hence, in this feasibility study, we seek to investigate the following question: Can tumor location on treatment-na\"ive MRI provide early cues regarding likelihood of a patient developing pseudo-progression versus tumor recurrence? In this study, 74 pre-treatment Glioblastoma MRI scans with PsP (33) and tumor recurrence (41) were analyzed. First, enhancing lesion on Gd-T1w MRI and peri-lesional hyperintensities on T2w/FLAIR were segmented by experts and then registered to a brain atlas. Using patients from the two phenotypes, we construct two atlases by quantifying frequency of occurrence of enhancing lesion and peri-lesion hyperintensities, by averaging voxel intensities across the population. Analysis of differential involvement was then performed to compute voxel-wise significant differences (p-value<0.05) across the atlases. Statistically significant clusters were finally mapped to a structural atlas to provide anatomic localization of their location. Our results demonstrate that patients with tumor recurrence showed prominence of their initial tumor in the parietal lobe, while patients with PsP showed a multi-focal distribution of the initial tumor in the frontal and temporal lobes, insula, and putamen. These preliminary results suggest that lateralization of pre-treatment lesions towards certain anatomical areas of the brain may allow to provide early cues regarding assessing likelihood of occurrence of pseudo-progression from tumor recurrence on MRI scans.