 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Adaptive KKT-Based Indicator for Convergence Assessment in Multi-Objective Optimization
Mar 04, 2026Performance indicators are essential tools for assessing the convergence behavior of multi-objective optimization algorithms, particularly when the true Pareto front is unknown or difficult to approximate. Classical reference-based metrics such as hypervolume and inverted generational distance are widely used, but may suffer from scalability limitations and sensitivity to parameter choices in many-objective scenarios. Indicators derived from Karush--Kuhn--Tucker (KKT) optimality conditions provide an intrinsic alternative by quantifying stationarity without relying on external reference sets. This paper revisits an entropy-inspired KKT-based convergence indicator and proposes a robust adaptive reformulation based on quantile normalization. The proposed indicator preserves the stationarity-based interpretation of the original formulation while improving robustness to heterogeneous distributions of stationarity residuals, a recurring issue in many-objective optimization.
Lyapunov Stability of Stochastic Vector Optimization: Theory and Numerical Implementation
Mar 04, 2026The use of stochastic differential equations in multi-objective optimization has been limited, in practice, by two persistent gaps: incomplete stability analyses and the absence of accessible implementations. We revisit a drift--diffusion model for unconstrained vector optimization in which the drift is induced by a common descent direction and the diffusion term preserves exploratory behavior. The main theoretical contribution is a self-contained Lyapunov analysis establishing global existence, pathwise uniqueness, and non-explosion under a dissipativity condition, together with positive recurrence under an additional coercivity assumption. We also derive an Euler--Maruyama discretization and implement the resulting iteration as a \emph{pymoo}-compatible algorithm -- \emph{pymoo} being an open-source Python framework for multi-objective optimization -- with an interactive \emph{PymooLab} front-end for reproducible experiments. Empirical results on DTLZ2 with objective counts from three to fifteen indicate a consistent trade-off: compared with established evolutionary baselines, the method is less competitive in low-dimensional regimes but remains a viable option under restricted evaluation budgets in higher-dimensional settings. Taken together, these observations suggest that stochastic drift--diffusion search occupies a mathematically tractable niche alongside population-based heuristics -- not as a replacement, but as an alternative whose favorable properties are amenable to rigorous analysis.
PathologyBERT -- Pre-trained Vs. A New Transformer Language Model for Pathology Domain
May 13, 2022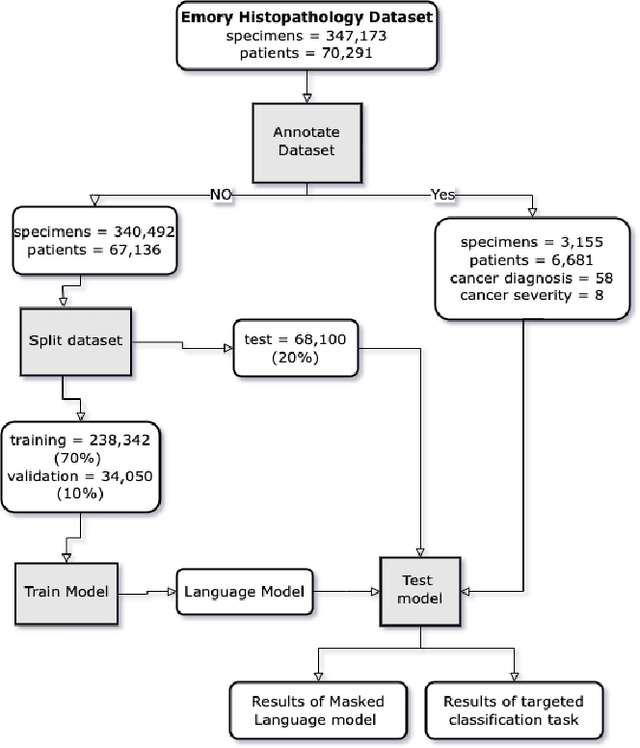

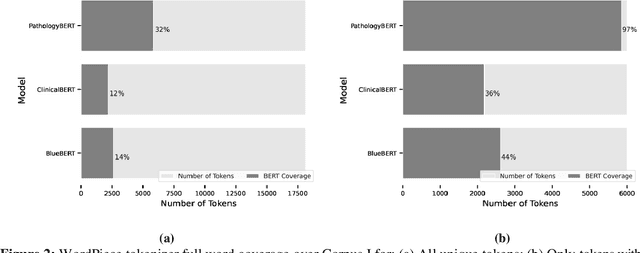
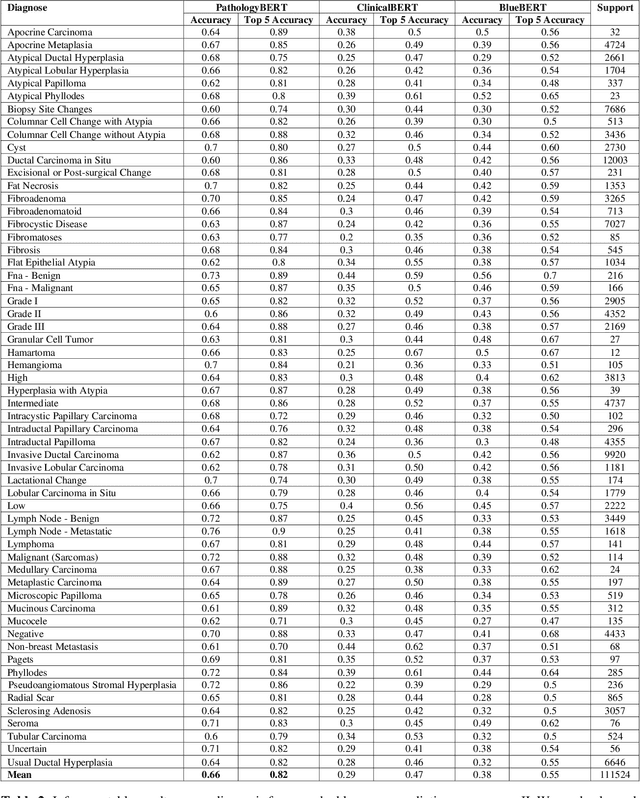
Pathology text mining is a challenging task given the reporting variability and constant new findings in cancer sub-type definitions. However, successful text mining of a large pathology database can play a critical role to advance 'big data' cancer research like similarity-based treatment selection, case identification, prognostication, surveillance, clinical trial screening, risk stratification, and many others. While there is a growing interest in developing language models for more specific clinical domains, no pathology-specific language space exist to support the rapid data-mining development in pathology space. In literature, a few approaches fine-tuned general transformer models on specialized corpora while maintaining the original tokenizer, but in fields requiring specialized terminology, these models often fail to perform adequately. We propose PathologyBERT - a pre-trained masked language model which was trained on 347,173 histopathology specimen reports and publicly released in the Huggingface repository. Our comprehensive experiments demonstrate that pre-training of transformer model on pathology corpora yields performance improvements on Natural Language Understanding (NLU) and Breast Cancer Diagnose Classification when compared to nonspecific language models.
The EMory BrEast imaging Dataset : A Racially Diverse, Granular Dataset of 3.5M Screening and Diagnostic Mammograms
Feb 08, 2022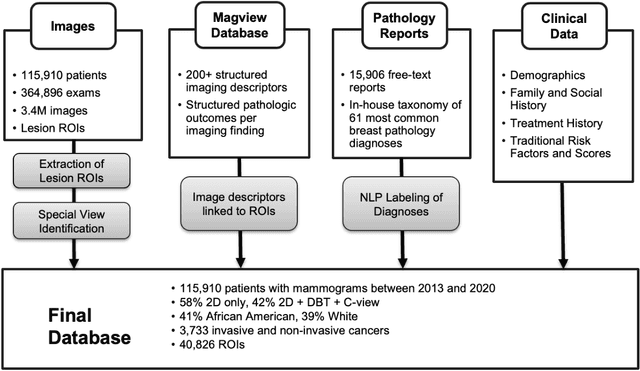
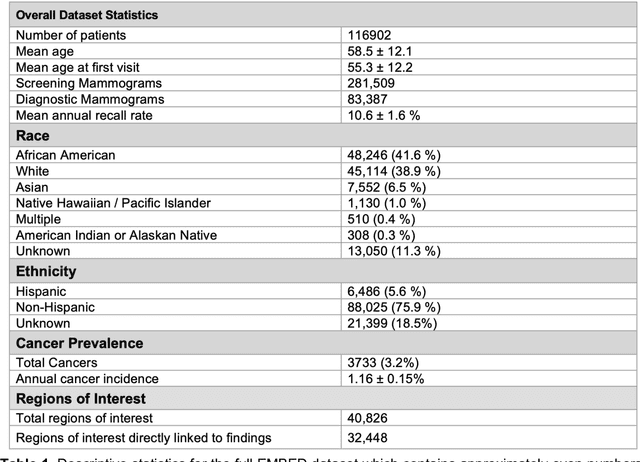

Developing and validating artificial intelligence models in medical imaging requires datasets that are large, granular, and diverse. To date, the majority of publicly available breast imaging datasets lack in one or more of these areas. Models trained on these data may therefore underperform on patient populations or pathologies that have not previously been encountered. The EMory BrEast imaging Dataset (EMBED) addresses these gaps by providing 3650,000 2D and DBT screening and diagnostic mammograms for 116,000 women divided equally between White and African American patients. The dataset also contains 40,000 annotated lesions linked to structured imaging descriptors and 61 ground truth pathologic outcomes grouped into six severity classes. Our goal is to share this dataset with research partners to aid in development and validation of breast AI models that will serve all patients fairly and help decrease bias in medical AI.
A Convergence indicator for Multi-Objective Optimisation Algorithms
Oct 29, 2018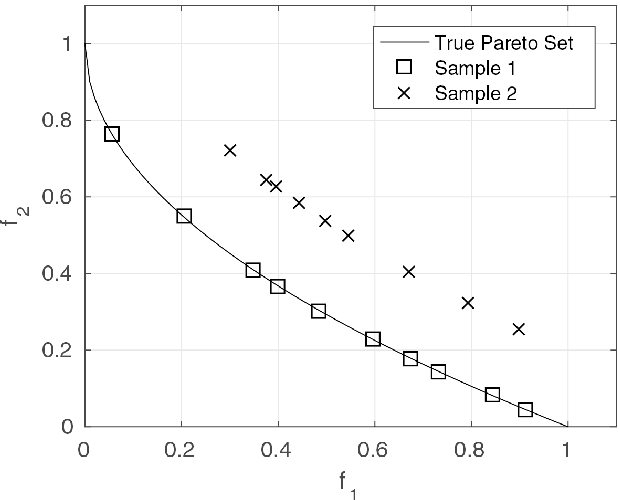

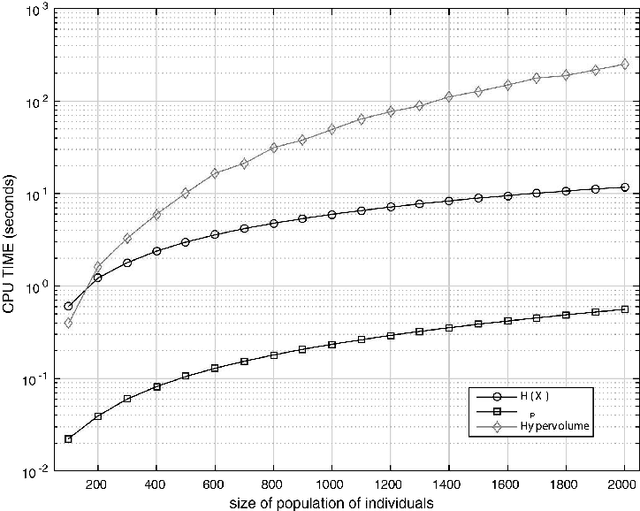

The algorithms of multi-objective optimisation had a relative growth in the last years. Thereby, it's requires some way of comparing the results of these. In this sense, performance measures play a key role. In general, it's considered some properties of these algorithms such as capacity, convergence, diversity or convergence-diversity. There are some known measures such as generational distance (GD), inverted generational distance (IGD), hypervolume (HV), Spread($\Delta$), Averaged Hausdorff distance ($\Delta_p$), R2-indicator, among others. In this paper, we focuses on proposing a new indicator to measure convergence based on the traditional formula for Shannon entropy. The main features about this measure are: 1) It does not require tho know the true Pareto set and 2) Medium computational cost when compared with Hypervolume.