 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Fast and Accurate System for Face Detection, Identification, and Verification
Sep 20, 2018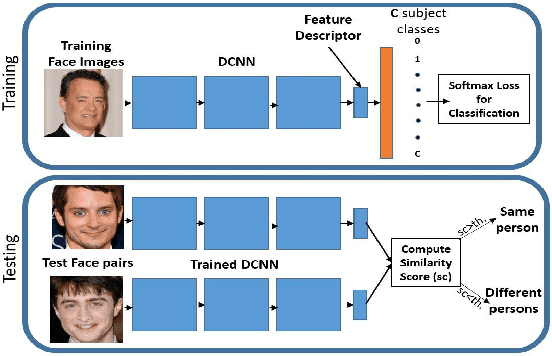
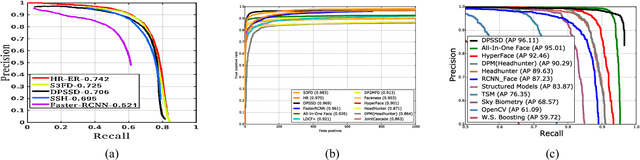
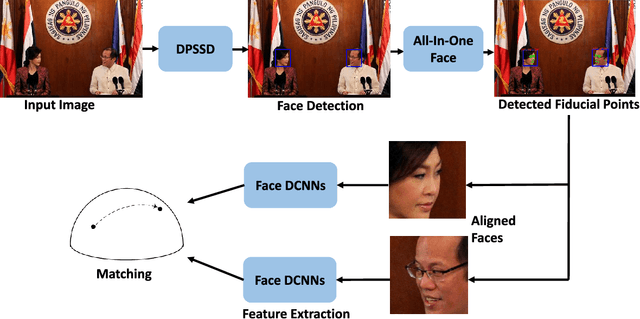
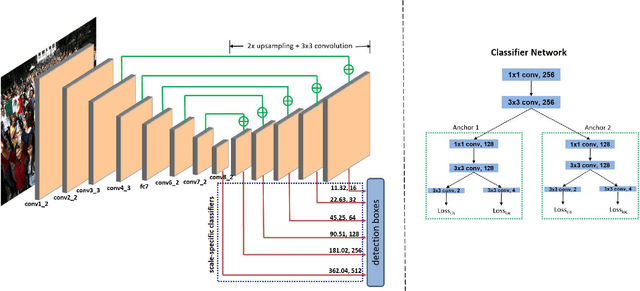
The availability of large annotated datasets and affordable computation power have led to impressive improvements in the performance of CNNs on various object detection and recognition benchmarks. These, along with a better understanding of deep learning methods, have also led to improved capabilities of machine understanding of faces. CNNs are able to detect faces, locate facial landmarks, estimate pose, and recognize faces in unconstrained images and videos. In this paper, we describe the details of a deep learning pipeline for unconstrained face identification and verification which achieves state-of-the-art performance on several benchmark datasets. We propose a novel face detector, Deep Pyramid Single Shot Face Detector (DPSSD), which is fast and capable of detecting faces with large scale variations (especially tiny faces). We give design details of the various modules involved in automatic face recognition: face detection, landmark localization and alignment, and face identification/verification. We provide evaluation results of the proposed face detector on challenging unconstrained face detection datasets. Then, we present experimental results for IARPA Janus Benchmarks A, B and C (IJB-A, IJB-B, IJB-C), and the Janus Challenge Set 5 (CS5).
Deep Regionlets for Object Detection
Aug 23, 2018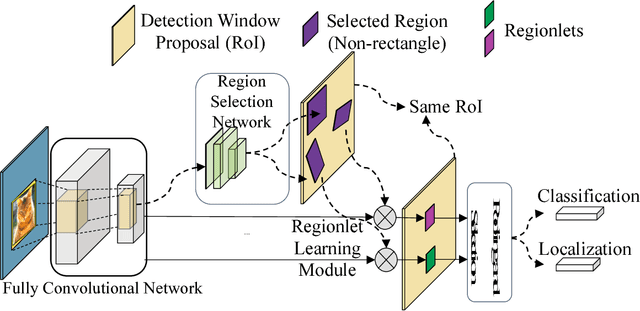
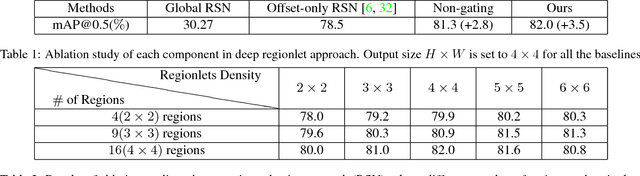
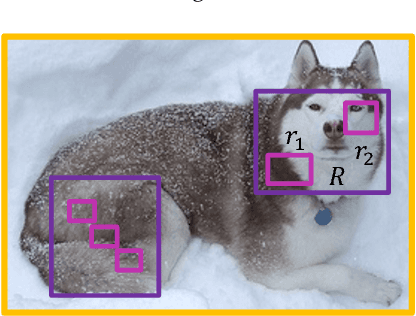
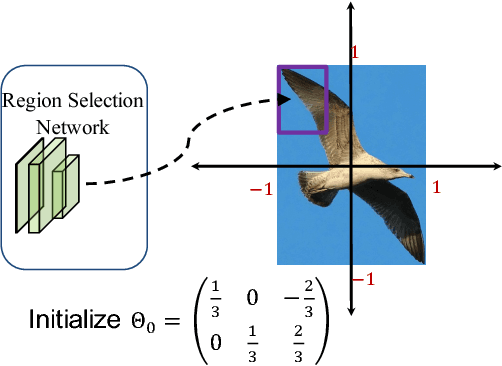
In this paper, we propose a novel object detection framework named "Deep Regionlets" by establishing a bridge between deep neural networks and conventional detection schema for accurate generic object detection. Motivated by the abilities of regionlets for modeling object deformation and multiple aspect ratios, we incorporate regionlets into an end-to-end trainable deep learning framework. The deep regionlets framework consists of a region selection network and a deep regionlet learning module. Specifically, given a detection bounding box proposal, the region selection network provides guidance on where to select regions to learn the features from. The regionlet learning module focuses on local feature selection and transformation to alleviate local variations. To this end, we first realize non-rectangular region selection within the detection framework to accommodate variations in object appearance. Moreover, we design a "gating network" within the regionlet leaning module to enable soft regionlet selection and pooling. The Deep Regionlets framework is trained end-to-end without additional efforts. We perform ablation studies and conduct extensive experiments on the PASCAL VOC and Microsoft COCO datasets. The proposed framework outperforms state-of-the-art algorithms, such as RetinaNet and Mask R-CNN, even without additional segmentation labels.
An Experimental Evaluation of Covariates Effects on Unconstrained Face Verification
Aug 16, 2018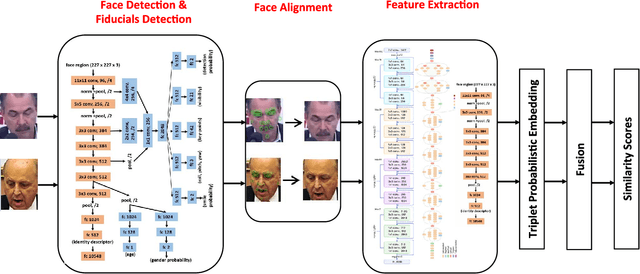
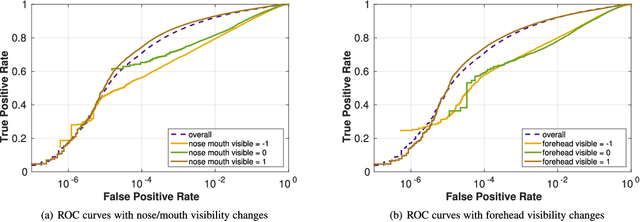
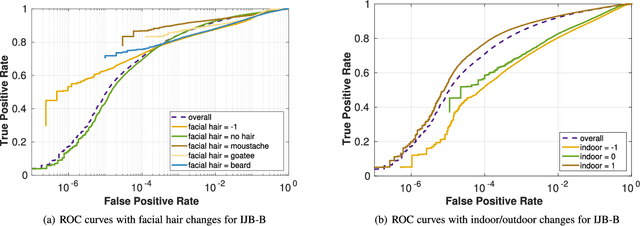
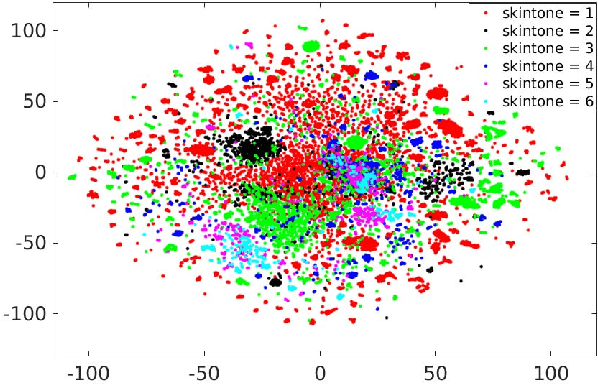
Covariates are factors that have a debilitating influence on face verification performance. In this paper, we comprehensively study two covariate related problems for unconstrained face verification: first, how covariates affect the performance of deep neural networks on the large-scale unconstrained face verification problem; second, how to utilize covariates to improve verification performance. To study the first problem, we implement five state-of-the-art deep convolutional networks (DCNNs) for face verification and evaluate them on three challenging covariates datasets. In total, seven covariates are considered: pose (yaw and roll), age, facial hair, gender, indoor/outdoor, occlusion (nose and mouth visibility, eyes visibility, and forehead visibility), and skin tone. These covariates cover both intrinsic subject-specific characteristics and extrinsic factors of faces. Some of the results confirm and extend the findings of previous studies, others are new findings that were rarely mentioned previously or did not show consistent trends. For the second problem, we demonstrate that with the assistance of gender information, the quality of a pre-curated noisy large-scale face dataset for face recognition can be further improved. After retraining the face recognition model using the curated data, performance improvement is observed at low False Acceptance Rates (FARs) (FAR=$10^{-5}$, $10^{-6}$, $10^{-7}$).
Zero-Shot Object Detection
Jul 27, 2018
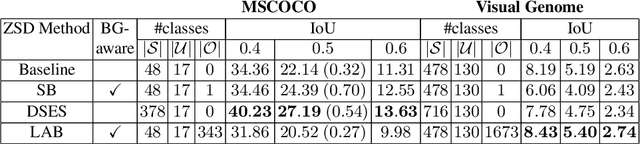
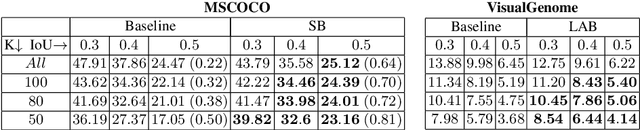

We introduce and tackle the problem of zero-shot object detection (ZSD), which aims to detect object classes which are not observed during training. We work with a challenging set of object classes, not restricting ourselves to similar and/or fine-grained categories as in prior works on zero-shot classification. We present a principled approach by first adapting visual-semantic embeddings for ZSD. We then discuss the problems associated with selecting a background class and motivate two background-aware approaches for learning robust detectors. One of these models uses a fixed background class and the other is based on iterative latent assignments. We also outline the challenge associated with using a limited number of training classes and propose a solution based on dense sampling of the semantic label space using auxiliary data with a large number of categories. We propose novel splits of two standard detection datasets - MSCOCO and VisualGenome, and present extensive empirical results in both the traditional and generalized zero-shot settings to highlight the benefits of the proposed methods. We provide useful insights into the algorithm and conclude by posing some open questions to encourage further research.
Continuous Authentication of Smartphones Based on Application Usage
Jul 18, 2018
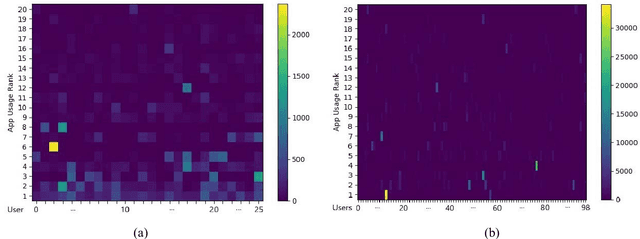
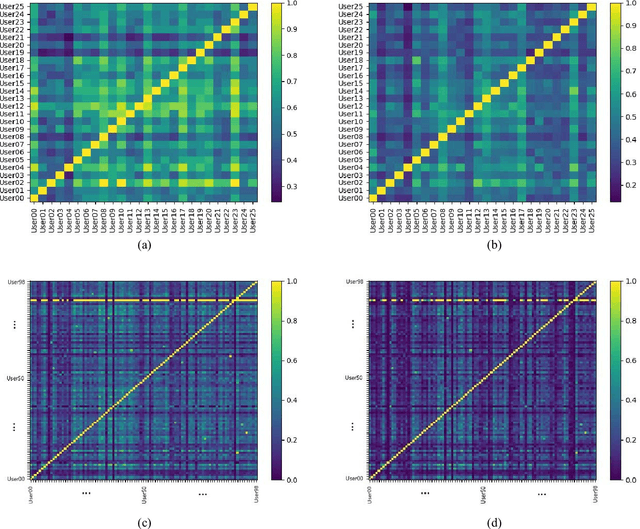
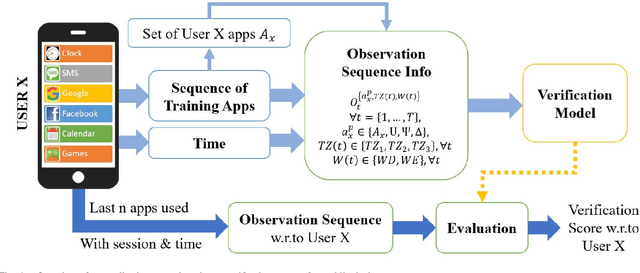
An empirical investigation of active/continuous authentication for smartphones is presented in this paper by exploiting users' unique application usage data, i.e., distinct patterns of use, modeled by a Markovian process. Variations of Hidden Markov Models (HMMs) are evaluated for continuous user verification, and challenges due to the sparsity of session-wise data, an explosion of states, and handling unforeseen events in the test data are tackled. Unlike traditional approaches, the proposed formulation does not depend on the top N-apps, rather uses the complete app-usage information to achieve low latency. Through experimentation, empirical assessment of the impact of unforeseen events, i.e., unknown applications and unforeseen observations, on user verification is done via a modified edit-distance algorithm for simple sequence matching. It is found that for enhanced verification performance, unforeseen events should be incorporated in the models by adopting smoothing techniques with HMMs. For validation, extensive experiments on two distinct datasets are performed. The marginal smoothing technique is the most effective for user verification in terms of equal error rate (EER) and with a sampling rate of 1/30s^{-1} and 30 minutes of historical data, and the method is capable of detecting an intrusion within ~2.5 minutes of application use.
Soft Sampling for Robust Object Detection
Jun 18, 2018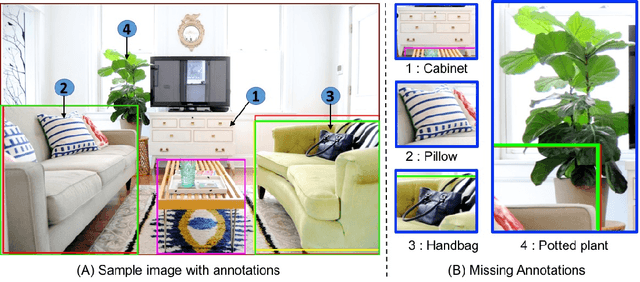
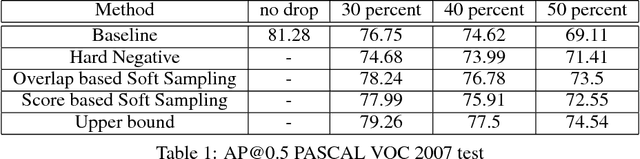
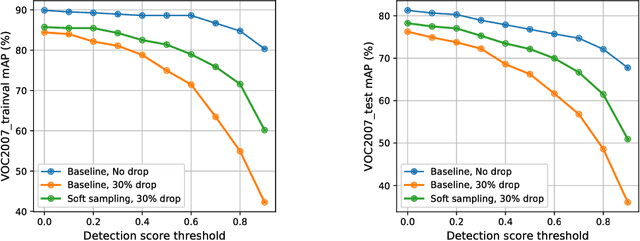
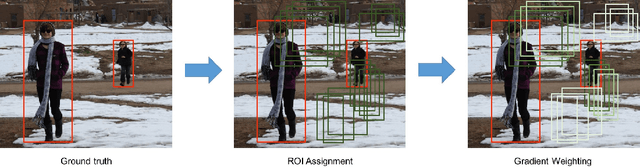
We study the robustness of object detection under the presence of missing annotations. In this setting, the unlabeled object instances will be treated as background, which will generate an incorrect training signal for the detector. Interestingly, we observe that after dropping 30% of the annotations (and labeling them as background), the performance of CNN-based object detectors like Faster-RCNN only drops by 5% on the PASCAL VOC dataset. We provide a detailed explanation for this result. To further bridge the performance gap, we propose a simple yet effective solution, called Soft Sampling. Soft Sampling re-weights the gradients of RoIs as a function of overlap with positive instances. This ensures that the uncertain background regions are given a smaller weight compared to the hardnegatives. Extensive experiments on curated PASCAL VOC datasets demonstrate the effectiveness of the proposed Soft Sampling method at different annotation drop rates. Finally, we show that on OpenImagesV3, which is a real-world dataset with missing annotations, Soft Sampling outperforms standard detection baselines by over 3%.
Regularizing deep networks using efficient layerwise adversarial training
May 29, 2018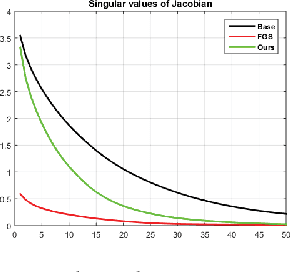
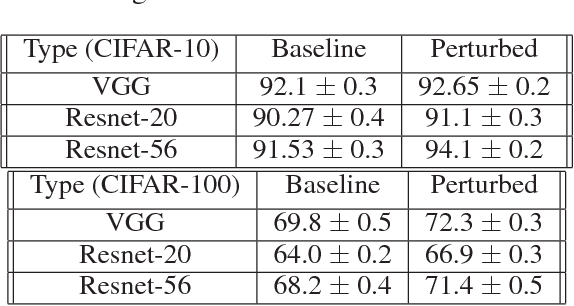
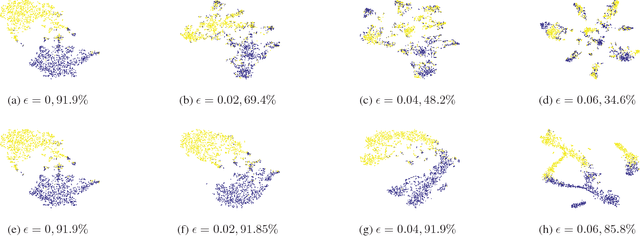
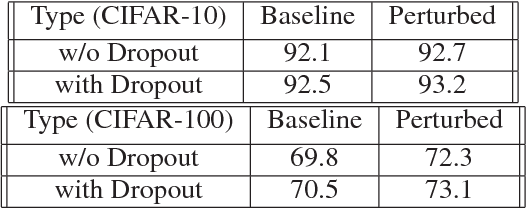
Adversarial training has been shown to regularize deep neural networks in addition to increasing their robustness to adversarial examples. However, its impact on very deep state of the art networks has not been fully investigated. In this paper, we present an efficient approach to perform adversarial training by perturbing intermediate layer activations and study the use of such perturbations as a regularizer during training. We use these perturbations to train very deep models such as ResNets and show improvement in performance both on adversarial and original test data. Our experiments highlight the benefits of perturbing intermediate layer activations compared to perturbing only the inputs. The results on CIFAR-10 and CIFAR-100 datasets show the merits of the proposed adversarial training approach. Additional results on WideResNets show that our approach provides significant improvement in classification accuracy for a given base model, outperforming dropout and other base models of larger size.
Defense-GAN: Protecting Classifiers Against Adversarial Attacks Using Generative Models
May 18, 2018
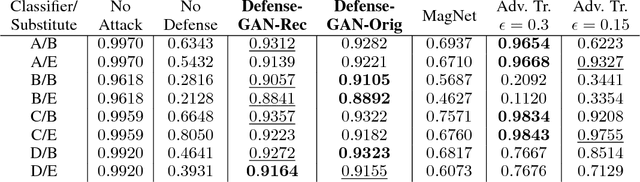
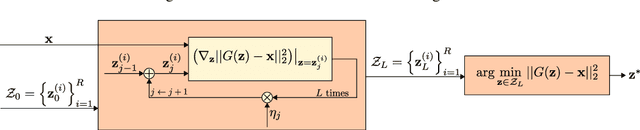
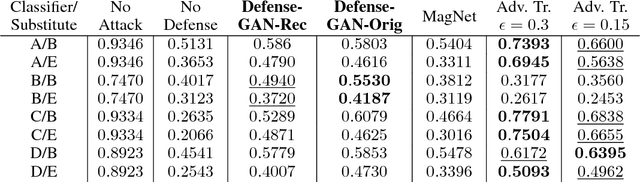
In recent years, deep neural network approaches have been widely adopted for machine learning tasks, including classification. However, they were shown to be vulnerable to adversarial perturbations: carefully crafted small perturbations can cause misclassification of legitimate images. We propose Defense-GAN, a new framework leveraging the expressive capability of generative models to defend deep neural networks against such attacks. Defense-GAN is trained to model the distribution of unperturbed images. At inference time, it finds a close output to a given image which does not contain the adversarial changes. This output is then fed to the classifier. Our proposed method can be used with any classification model and does not modify the classifier structure or training procedure. It can also be used as a defense against any attack as it does not assume knowledge of the process for generating the adversarial examples. We empirically show that Defense-GAN is consistently effective against different attack methods and improves on existing defense strategies. Our code has been made publicly available at https://github.com/kabkabm/defensegan
Cross-Domain Visual Recognition via Domain Adaptive Dictionary Learning
Apr 16, 2018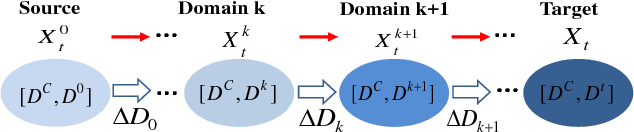
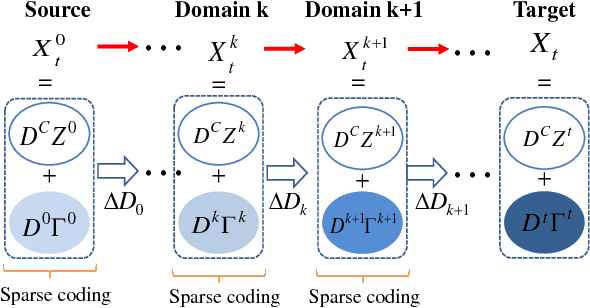


In real-world visual recognition problems, the assumption that the training data (source domain) and test data (target domain) are sampled from the same distribution is often violated. This is known as the domain adaptation problem. In this work, we propose a novel domain-adaptive dictionary learning framework for cross-domain visual recognition. Our method generates a set of intermediate domains. These intermediate domains form a smooth path and bridge the gap between the source and target domains. Specifically, we not only learn a common dictionary to encode the domain-shared features, but also learn a set of domain-specific dictionaries to model the domain shift. The separation of the common and domain-specific dictionaries enables us to learn more compact and reconstructive dictionaries for domain adaptation. These dictionaries are learned by alternating between domain-adaptive sparse coding and dictionary updating steps. Meanwhile, our approach gradually recovers the feature representations of both source and target data along the domain path. By aligning all the recovered domain data, we derive the final domain-adaptive features for cross-domain visual recognition. Extensive experiments on three public datasets demonstrates that our approach outperforms most state-of-the-art methods.
Generate To Adapt: Aligning Domains using Generative Adversarial Networks
Apr 12, 2018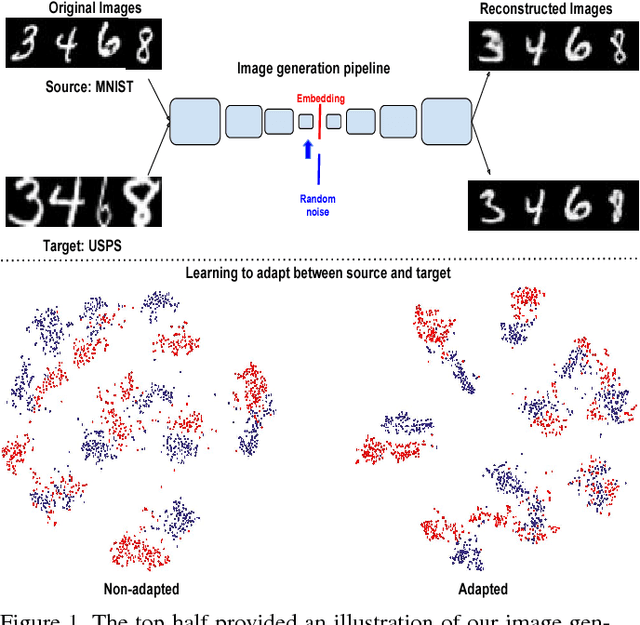

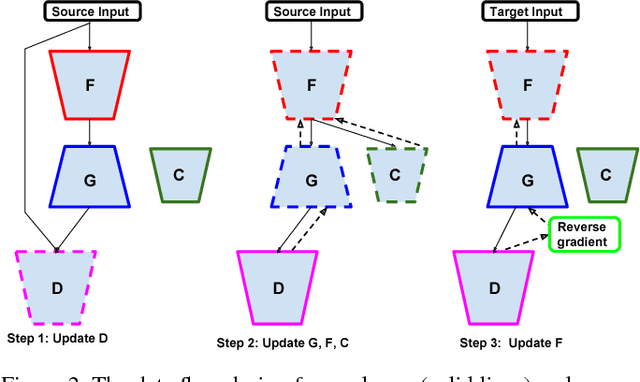
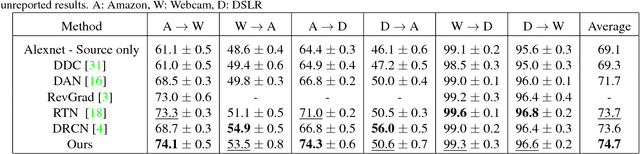
Domain Adaptation is an actively researched problem in Computer Vision. In this work, we propose an approach that leverages unsupervised data to bring the source and target distributions closer in a learned joint feature space. We accomplish this by inducing a symbiotic relationship between the learned embedding and a generative adversarial network. This is in contrast to methods which use the adversarial framework for realistic data generation and retraining deep models with such data. We demonstrate the strength and generality of our approach by performing experiments on three different tasks with varying levels of difficulty: (1) Digit classification (MNIST, SVHN and USPS datasets) (2) Object recognition using OFFICE dataset and (3) Domain adaptation from synthetic to real data. Our method achieves state-of-the art performance in most experimental settings and by far the only GAN-based method that has been shown to work well across different datasets such as OFFICE and DIGITS.