 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition-Invariant Truecasing with a Word-and-Character Hierarchical Recurrent Neural Network
Sep 01, 2021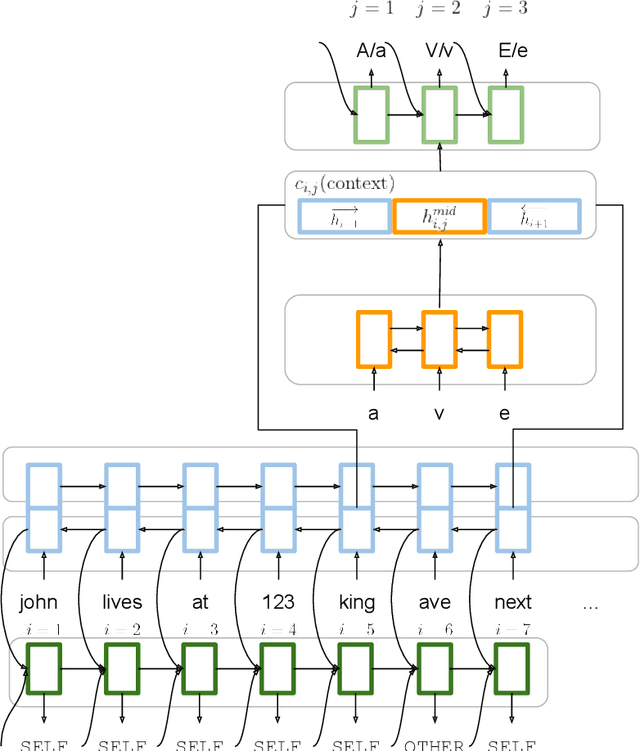
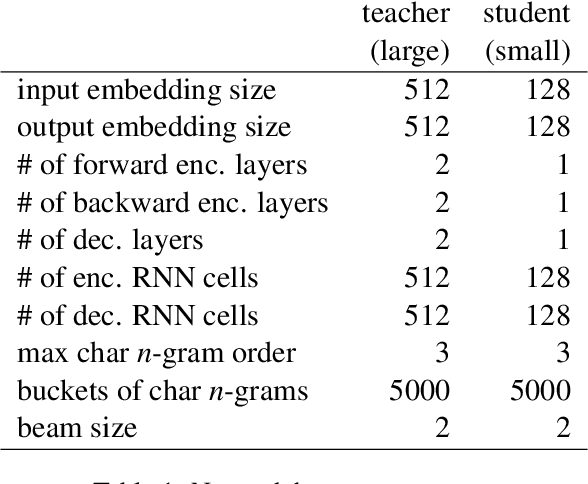

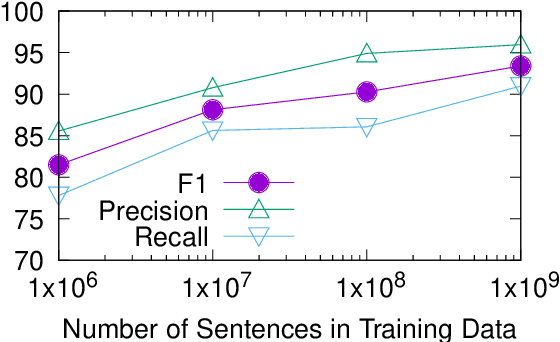
Truecasing is the task of restoring the correct case (uppercase or lowercase) of noisy text generated either by an automatic system for speech recognition or machine translation or by humans. It improves the performance of downstream NLP tasks such as named entity recognition and language modeling. We propose a fast, accurate and compact two-level hierarchical word-and-character-based recurrent neural network model, the first of its kind for this problem. Using sequence distillation, we also address the problem of truecasing while ignoring token positions in the sentence, i.e. in a position-invariant manner.
A Method to Reveal Speaker Identity in Distributed ASR Training, and How to Counter It
Apr 15, 2021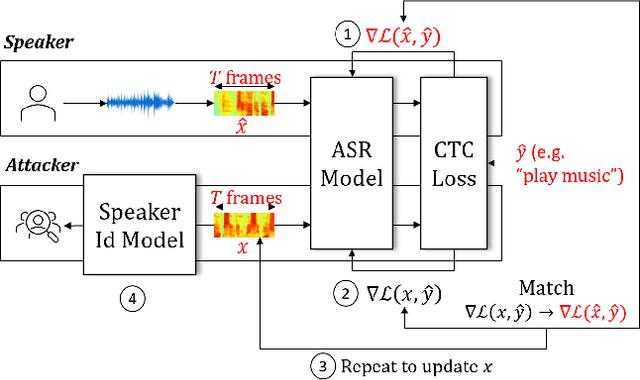

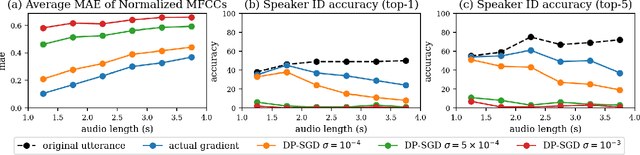
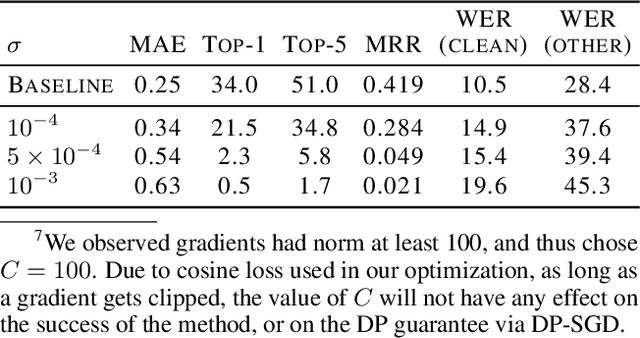
End-to-end Automatic Speech Recognition (ASR) models are commonly trained over spoken utterances using optimization methods like Stochastic Gradient Descent (SGD). In distributed settings like Federated Learning, model training requires transmission of gradients over a network. In this work, we design the first method for revealing the identity of the speaker of a training utterance with access only to a gradient. We propose Hessian-Free Gradients Matching, an input reconstruction technique that operates without second derivatives of the loss function (required in prior works), which can be expensive to compute. We show the effectiveness of our method using the DeepSpeech model architecture, demonstrating that it is possible to reveal the speaker's identity with 34% top-1 accuracy (51% top-5 accuracy) on the LibriSpeech dataset. Further, we study the effect of two well-known techniques, Differentially Private SGD and Dropout, on the success of our method. We show that a dropout rate of 0.2 can reduce the speaker identity accuracy to 0% top-1 (0.5% top-5).
Communication-Efficient Agnostic Federated Averaging
Apr 06, 2021
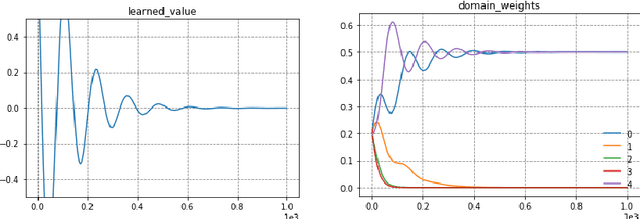
In distributed learning settings such as federated learning, the training algorithm can be potentially biased towards different clients. Mohri et al. (2019) proposed a domain-agnostic learning algorithm, where the model is optimized for any target distribution formed by a mixture of the client distributions in order to overcome this bias. They further proposed an algorithm for the cross-silo federated learning setting, where the number of clients is small. We consider this problem in the cross-device setting, where the number of clients is much larger. We propose a communication-efficient distributed algorithm called Agnostic Federated Averaging (or AgnosticFedAvg) to minimize the domain-agnostic objective proposed in Mohri et al. (2019), which is amenable to other private mechanisms such as secure aggregation. We highlight two types of naturally occurring domains in federated learning and argue that AgnosticFedAvg performs well on both. To demonstrate the practical effectiveness of AgnosticFedAvg, we report positive results for large-scale language modeling tasks in both simulation and live experiments, where the latter involves training language models for Spanish virtual keyboard for millions of user devices.
Training Production Language Models without Memorizing User Data
Sep 21, 2020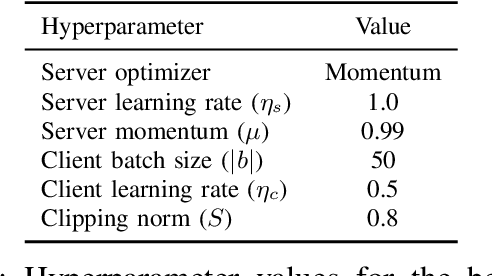
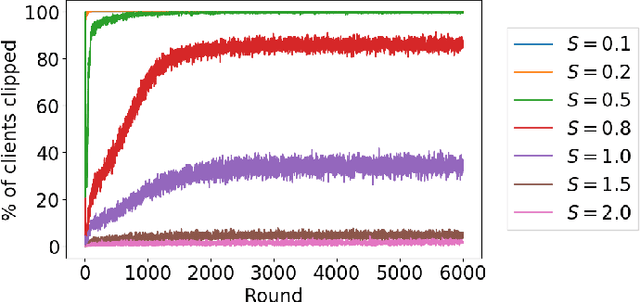
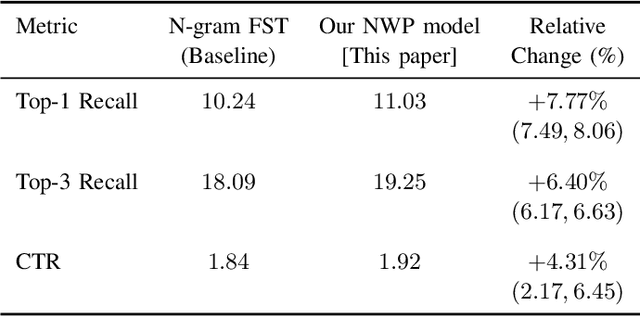
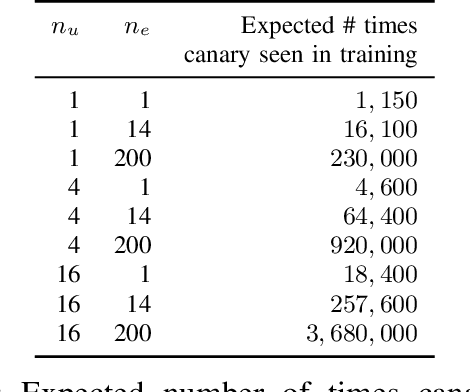
This paper presents the first consumer-scale next-word prediction (NWP) model trained with Federated Learning (FL) while leveraging the Differentially Private Federated Averaging (DP-FedAvg) technique. There has been prior work on building practical FL infrastructure, including work demonstrating the feasibility of training language models on mobile devices using such infrastructure. It has also been shown (in simulations on a public corpus) that it is possible to train NWP models with user-level differential privacy using the DP-FedAvg algorithm. Nevertheless, training production-quality NWP models with DP-FedAvg in a real-world production environment on a heterogeneous fleet of mobile phones requires addressing numerous challenges. For instance, the coordinating central server has to keep track of the devices available at the start of each round and sample devices uniformly at random from them, while ensuring \emph{secrecy of the sample}, etc. Unlike all prior privacy-focused FL work of which we are aware, for the first time we demonstrate the deployment of a differentially private mechanism for the training of a production neural network in FL, as well as the instrumentation of the production training infrastructure to perform an end-to-end empirical measurement of unintended memorization.
Understanding Unintended Memorization in Federated Learning
Jun 12, 2020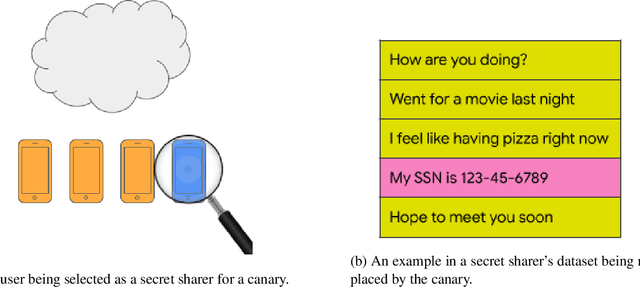
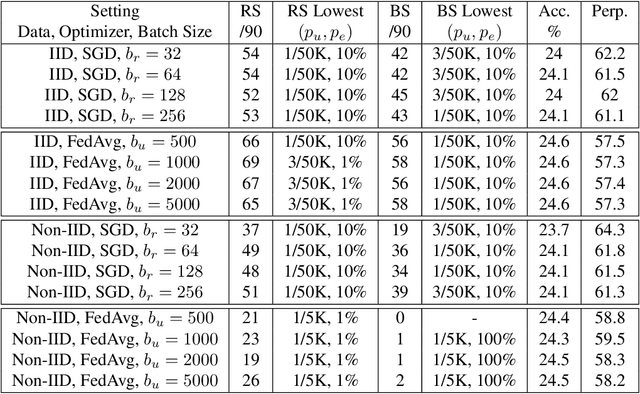
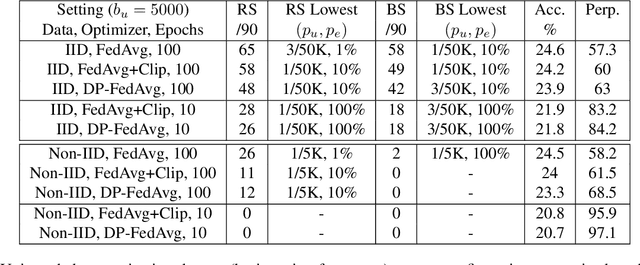
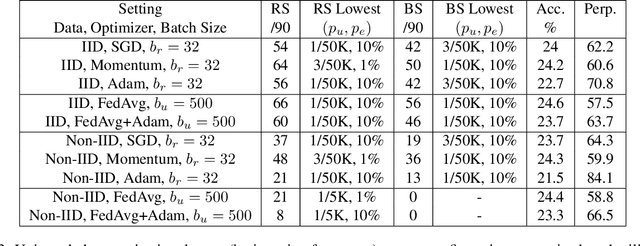
Recent works have shown that generative sequence models (e.g., language models) have a tendency to memorize rare or unique sequences in the training data. Since useful models are often trained on sensitive data, to ensure the privacy of the training data it is critical to identify and mitigate such unintended memorization. Federated Learning (FL) has emerged as a novel framework for large-scale distributed learning tasks. However, it differs in many aspects from the well-studied central learning setting where all the data is stored at the central server. In this paper, we initiate a formal study to understand the effect of different components of canonical FL on unintended memorization in trained models, comparing with the central learning setting. Our results show that several differing components of FL play an important role in reducing unintended memorization. Specifically, we observe that the clustering of data according to users---which happens by design in FL---has a significant effect in reducing such memorization, and using the method of Federated Averaging for training causes a further reduction. We also show that training with a strong user-level differential privacy guarantee results in models that exhibit the least amount of unintended memorization.
Training Keyword Spotting Models on Non-IID Data with Federated Learning
Jun 04, 2020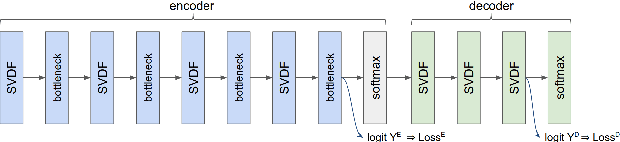
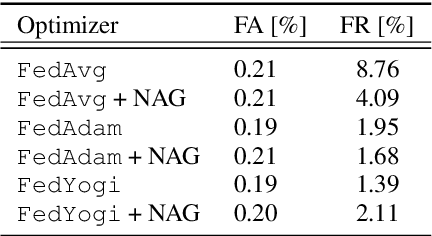

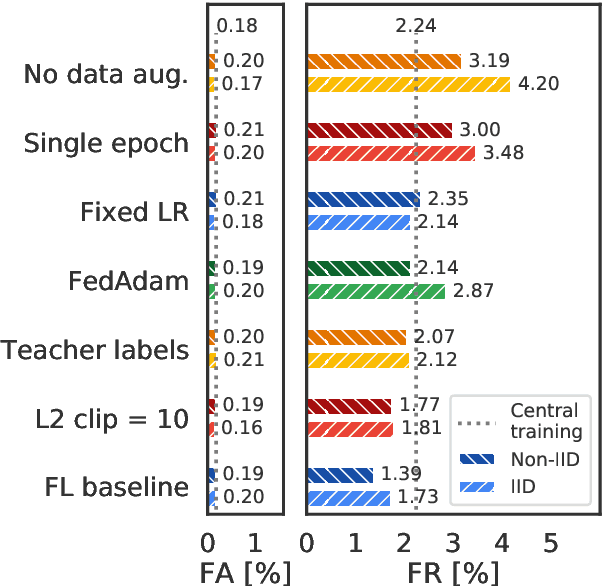
We demonstrate that a production-quality keyword-spotting model can be trained on-device using federated learning and achieve comparable false accept and false reject rates to a centrally-trained model. To overcome the algorithmic constraints associated with fitting on-device data (which are inherently non-independent and identically distributed), we conduct thorough empirical studies of optimization algorithms and hyperparameter configurations using large-scale federated simulations. To overcome resource constraints, we replace memory intensive MTR data augmentation with SpecAugment, which reduces the false reject rate by 56%. Finally, to label examples (given the zero visibility into on-device data), we explore teacher-student training.
Generative Models for Effective ML on Private, Decentralized Datasets
Nov 15, 2019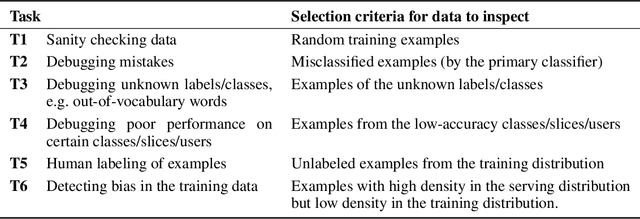
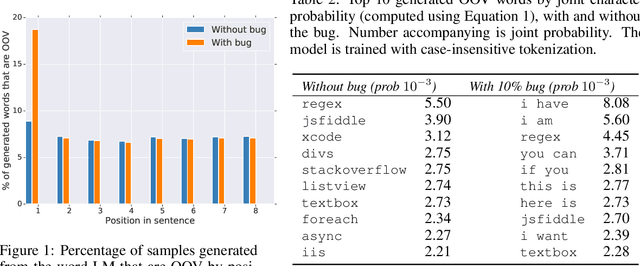
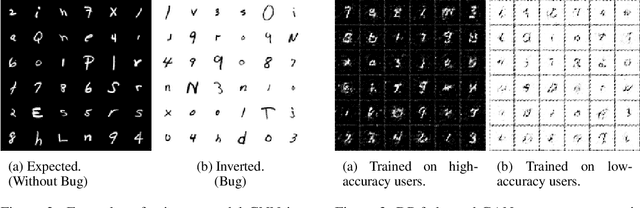
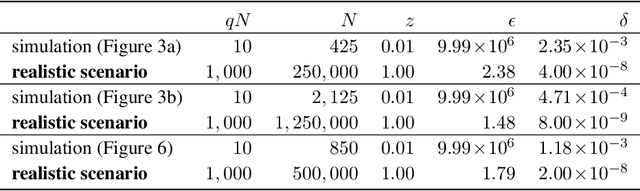
To improve real-world applications of machine learning, experienced modelers develop intuition about their datasets, their models, and how the two interact. Manual inspection of raw data - of representative samples, of outliers, of misclassifications - is an essential tool in a) identifying and fixing problems in the data, b) generating new modeling hypotheses, and c) assigning or refining human-provided labels. However, manual data inspection is problematic for privacy sensitive datasets, such as those representing the behavior of real-world individuals. Furthermore, manual data inspection is impossible in the increasingly important setting of federated learning, where raw examples are stored at the edge and the modeler may only access aggregated outputs such as metrics or model parameters. This paper demonstrates that generative models - trained using federated methods and with formal differential privacy guarantees - can be used effectively to debug many commonly occurring data issues even when the data cannot be directly inspected. We explore these methods in applications to text with differentially private federated RNNs and to images using a novel algorithm for differentially private federated GANs.
Federated Evaluation of On-device Personalization
Oct 22, 2019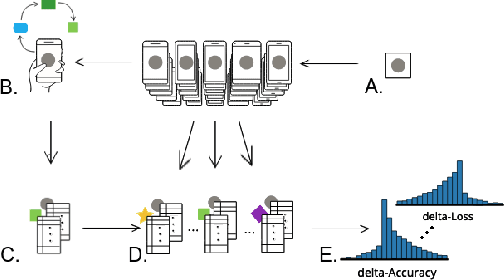
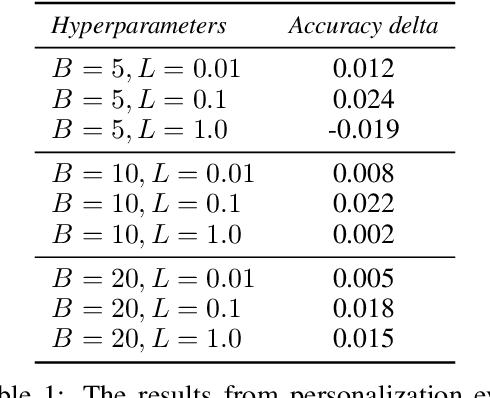
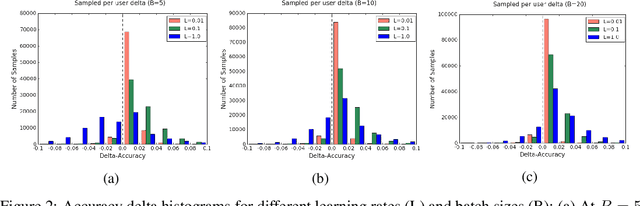
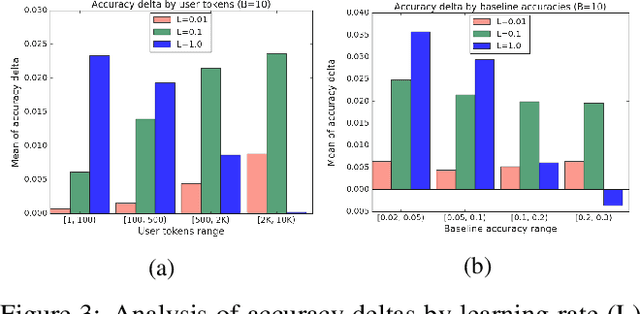
Federated learning is a distributed, on-device computation framework that enables training global models without exporting sensitive user data to servers. In this work, we describe methods to extend the federation framework to evaluate strategies for personalization of global models. We present tools to analyze the effects of personalization and evaluate conditions under which personalization yields desirable models. We report on our experiments personalizing a language model for a virtual keyboard for smartphones with a population of tens of millions of users. We show that a significant fraction of users benefit from personalization.
Federated Learning of N-gram Language Models
Oct 08, 2019

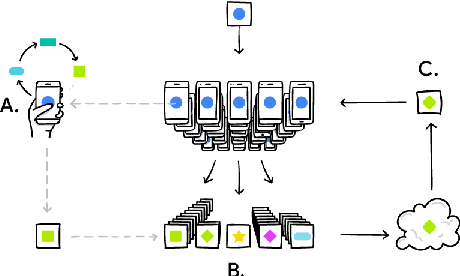
We propose algorithms to train production-quality n-gram language models using federated learning. Federated learning is a distributed computation platform that can be used to train global models for portable devices such as smart phones. Federated learning is especially relevant for applications handling privacy-sensitive data, such as virtual keyboards, because training is performed without the users' data ever leaving their devices. While the principles of federated learning are fairly generic, its methodology assumes that the underlying models are neural networks. However, virtual keyboards are typically powered by n-gram language models for latency reasons. We propose to train a recurrent neural network language model using the decentralized FederatedAveraging algorithm and to approximate this federated model server-side with an n-gram model that can be deployed to devices for fast inference. Our technical contributions include ways of handling large vocabularies, algorithms to correct capitalization errors in user data, and efficient finite state transducer algorithms to convert word language models to word-piece language models and vice versa. The n-gram language models trained with federated learning are compared to n-grams trained with traditional server-based algorithms using A/B tests on tens of millions of users of virtual keyboard. Results are presented for two languages, American English and Brazilian Portuguese. This work demonstrates that high-quality n-gram language models can be trained directly on client mobile devices without sensitive training data ever leaving the devices.
Federated Learning for Emoji Prediction in a Mobile Keyboard
Jun 11, 2019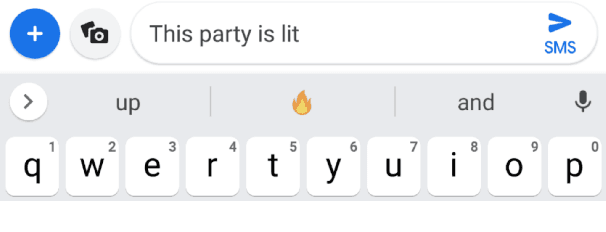

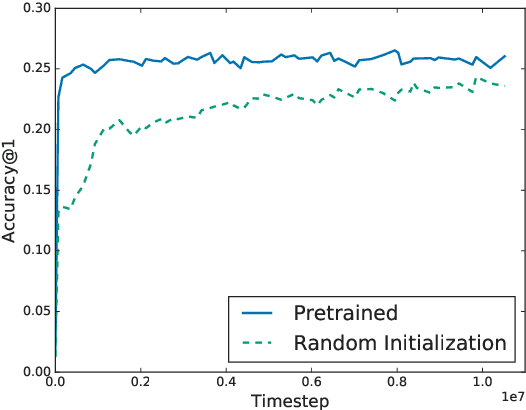
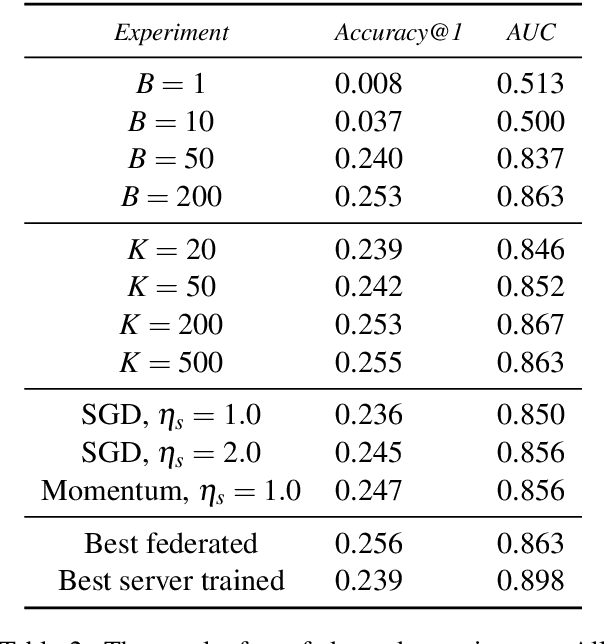
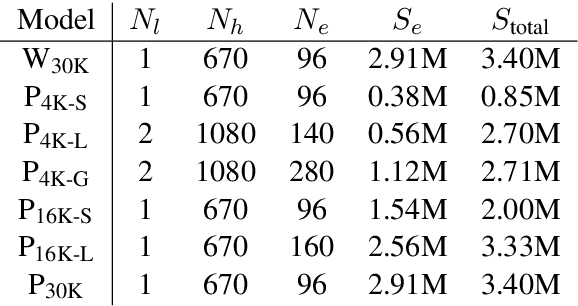
We show that a word-level recurrent neural network can predict emoji from text typed on a mobile keyboard. We demonstrate the usefulness of transfer learning for predicting emoji by pretraining the model using a language modeling task. We also propose mechanisms to trigger emoji and tune the diversity of candidates. The model is trained using a distributed on-device learning framework called federated learning. The federated model is shown to achieve better performance than a server-trained model. This work demonstrates the feasibility of using federated learning to train production-quality models for natural language understanding tasks while keeping users' data on their devices.