 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUserLibri: A Dataset for ASR Personalization Using Only Text
Jul 02, 2022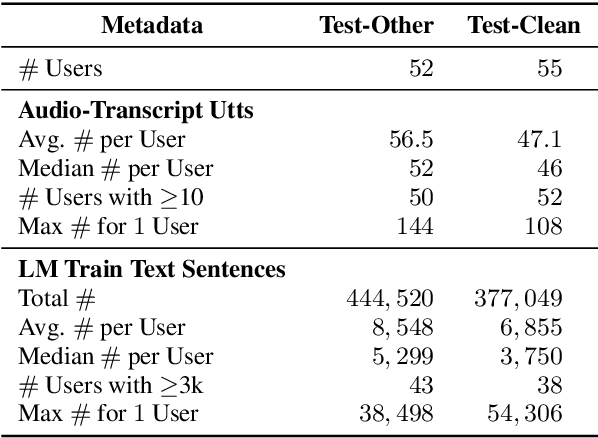
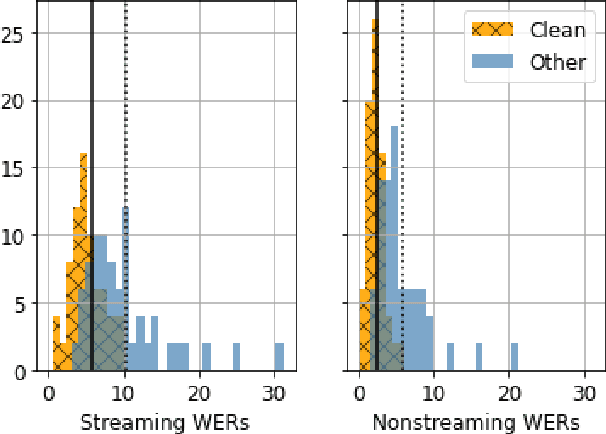
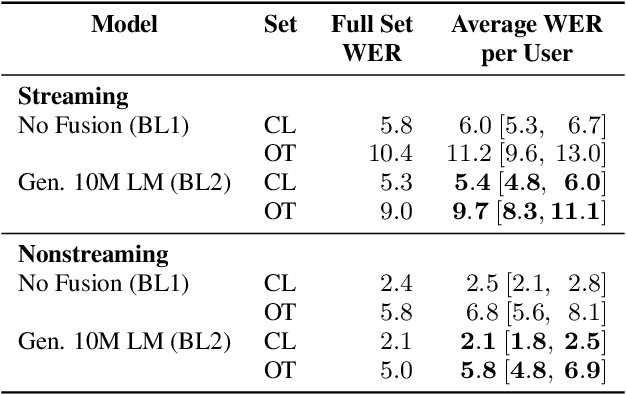
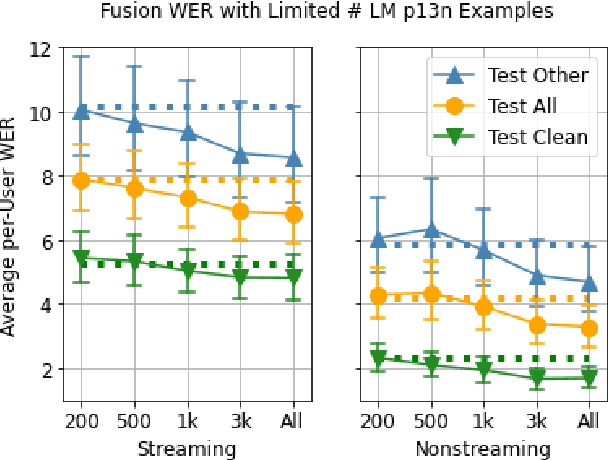
Personalization of speech models on mobile devices (on-device personalization) is an active area of research, but more often than not, mobile devices have more text-only data than paired audio-text data. We explore training a personalized language model on text-only data, used during inference to improve speech recognition performance for that user. We experiment on a user-clustered LibriSpeech corpus, supplemented with personalized text-only data for each user from Project Gutenberg. We release this User-Specific LibriSpeech (UserLibri) dataset to aid future personalization research. LibriSpeech audio-transcript pairs are grouped into 55 users from the test-clean dataset and 52 users from test-other. We are able to lower the average word error rate per user across both sets in streaming and nonstreaming models, including an improvement of 2.5 for the harder set of test-other users when streaming.
Mixed Federated Learning: Joint Decentralized and Centralized Learning
May 26, 2022
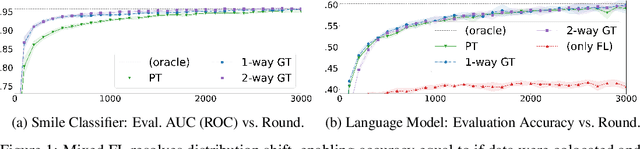
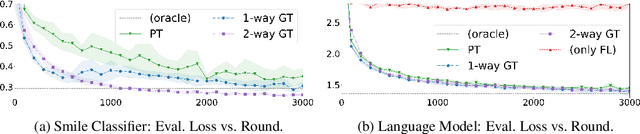
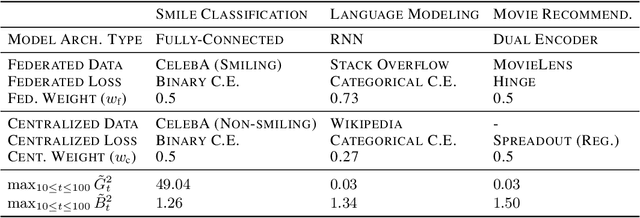
Federated learning (FL) enables learning from decentralized privacy-sensitive data, with computations on raw data confined to take place at edge clients. This paper introduces mixed FL, which incorporates an additional loss term calculated at the coordinating server (while maintaining FL's private data restrictions). There are numerous benefits. For example, additional datacenter data can be leveraged to jointly learn from centralized (datacenter) and decentralized (federated) training data and better match an expected inference data distribution. Mixed FL also enables offloading some intensive computations (e.g., embedding regularization) to the server, greatly reducing communication and client computation load. For these and other mixed FL use cases, we present three algorithms: PARALLEL TRAINING, 1-WAY GRADIENT TRANSFER, and 2-WAY GRADIENT TRANSFER. We state convergence bounds for each, and give intuition on which are suited to particular mixed FL problems. Finally we perform extensive experiments on three tasks, demonstrating that mixed FL can blend training data to achieve an oracle's accuracy on an inference distribution, and can reduce communication and computation overhead by over 90%. Our experiments confirm theoretical predictions of how algorithms perform under different mixed FL problem settings.
Online Model Compression for Federated Learning with Large Models
May 06, 2022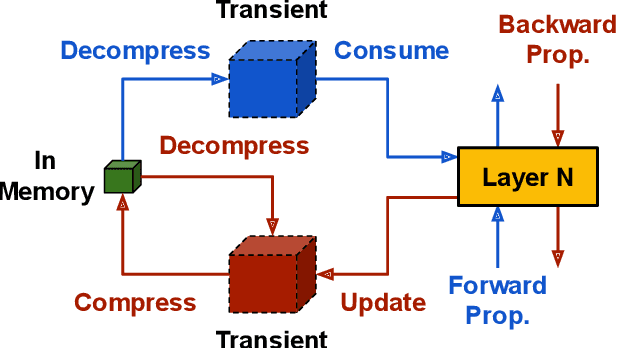
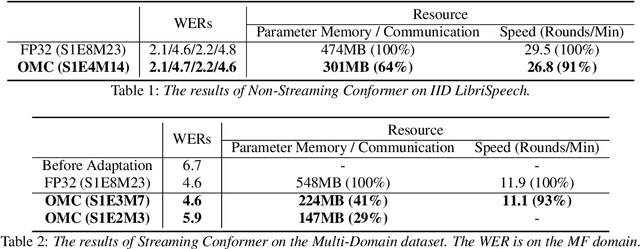
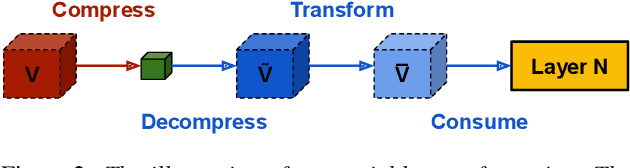
This paper addresses the challenges of training large neural network models under federated learning settings: high on-device memory usage and communication cost. The proposed Online Model Compression (OMC) provides a framework that stores model parameters in a compressed format and decompresses them only when needed. We use quantization as the compression method in this paper and propose three methods, (1) using per-variable transformation, (2) weight matrices only quantization, and (3) partial parameter quantization, to minimize the impact on model accuracy. According to our experiments on two recent neural networks for speech recognition and two different datasets, OMC can reduce memory usage and communication cost of model parameters by up to 59% while attaining comparable accuracy and training speed when compared with full-precision training.
Detecting Unintended Memorization in Language-Model-Fused ASR
Apr 20, 2022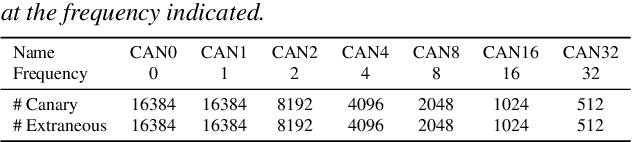
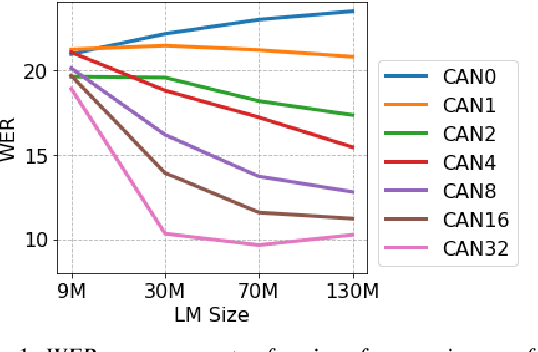
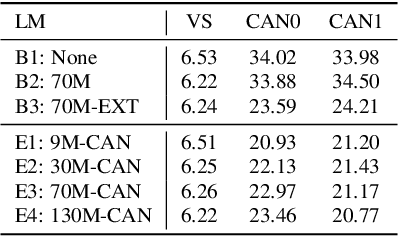
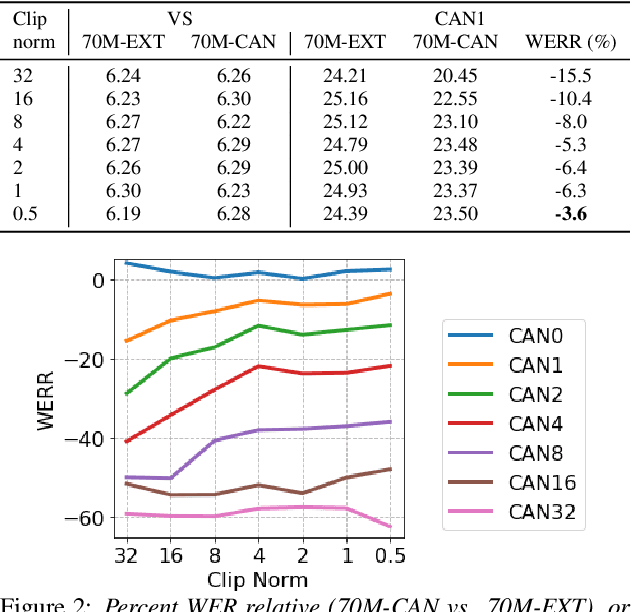
End-to-end (E2E) models are often being accompanied by language models (LMs) via shallow fusion for boosting their overall quality as well as recognition of rare words. At the same time, several prior works show that LMs are susceptible to unintentionally memorizing rare or unique sequences in the training data. In this work, we design a framework for detecting memorization of random textual sequences (which we call canaries) in the LM training data when one has only black-box (query) access to LM-fused speech recognizer, as opposed to direct access to the LM. On a production-grade Conformer RNN-T E2E model fused with a Transformer LM, we show that detecting memorization of singly-occurring canaries from the LM training data of 300M examples is possible. Motivated to protect privacy, we also show that such memorization gets significantly reduced by per-example gradient-clipped LM training without compromising overall quality.
Extracting Targeted Training Data from ASR Models, and How to Mitigate It
Apr 18, 2022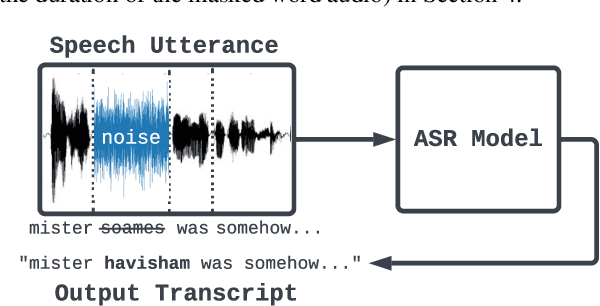
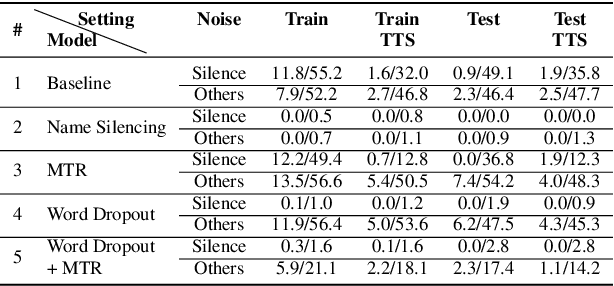
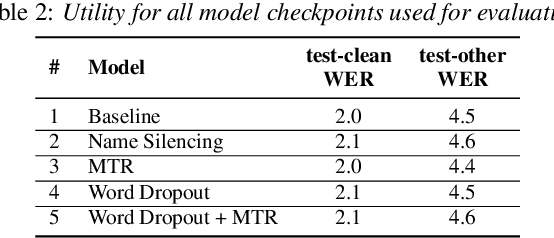
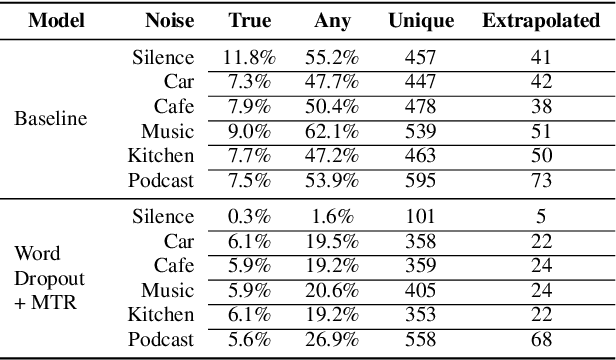
Recent work has designed methods to demonstrate that model updates in ASR training can leak potentially sensitive attributes of the utterances used in computing the updates. In this work, we design the first method to demonstrate information leakage about training data from trained ASR models. We design Noise Masking, a fill-in-the-blank style method for extracting targeted parts of training data from trained ASR models. We demonstrate the success of Noise Masking by using it in four settings for extracting names from the LibriSpeech dataset used for training a SOTA Conformer model. In particular, we show that we are able to extract the correct names from masked training utterances with 11.8% accuracy, while the model outputs some name from the train set 55.2% of the time. Further, we show that even in a setting that uses synthetic audio and partial transcripts from the test set, our method achieves 2.5% correct name accuracy (47.7% any name success rate). Lastly, we design Word Dropout, a data augmentation method that we show when used in training along with MTR, provides comparable utility as the baseline, along with significantly mitigating extraction via Noise Masking across the four evaluated settings.
Production federated keyword spotting via distillation, filtering, and joint federated-centralized training
Apr 11, 2022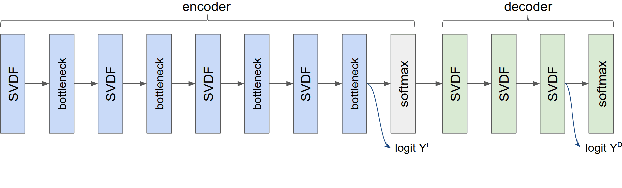
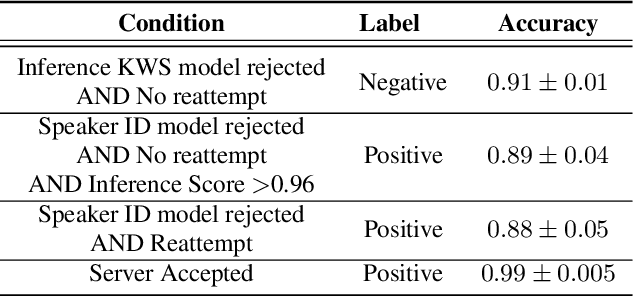

We trained a keyword spotting model using federated learning on real user devices and observed significant improvements when the model was deployed for inference on phones. To compensate for data domains that are missing from on-device training caches, we employed joint federated-centralized training. And to learn in the absence of curated labels on-device, we formulated a confidence filtering strategy based on user-feedback signals for federated distillation. These techniques created models that significantly improved quality metrics in offline evaluations and user-experience metrics in live A/B experiments.
Capitalization Normalization for Language Modeling with an Accurate and Efficient Hierarchical RNN Model
Feb 16, 2022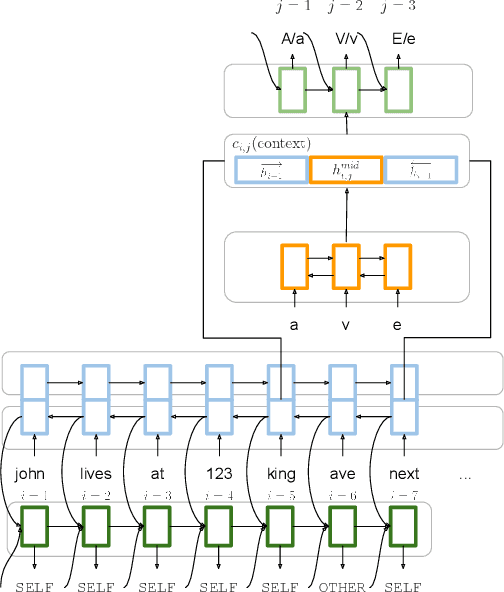
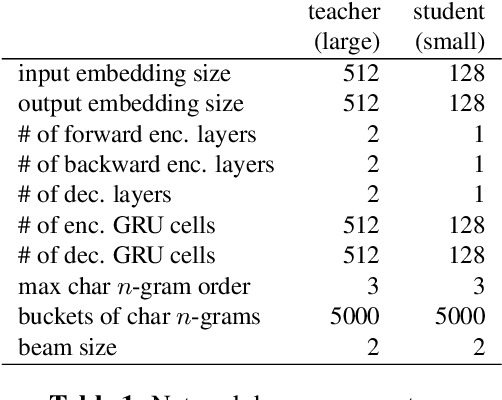
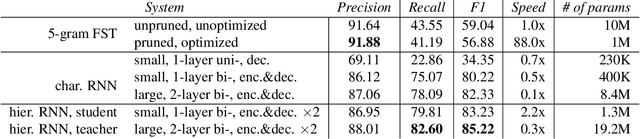

Capitalization normalization (truecasing) is the task of restoring the correct case (uppercase or lowercase) of noisy text. We propose a fast, accurate and compact two-level hierarchical word-and-character-based recurrent neural network model. We use the truecaser to normalize user-generated text in a Federated Learning framework for language modeling. A case-aware language model trained on this normalized text achieves the same perplexity as a model trained on text with gold capitalization. In a real user A/B experiment, we demonstrate that the improvement translates to reduced prediction error rates in a virtual keyboard application. Similarly, in an ASR language model fusion experiment, we show reduction in uppercase character error rate and word error rate.
Public Data-Assisted Mirror Descent for Private Model Training
Dec 01, 2021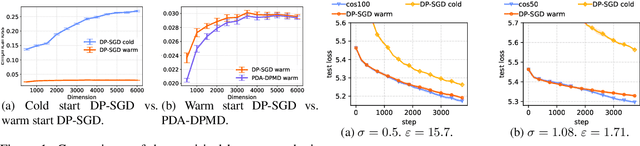
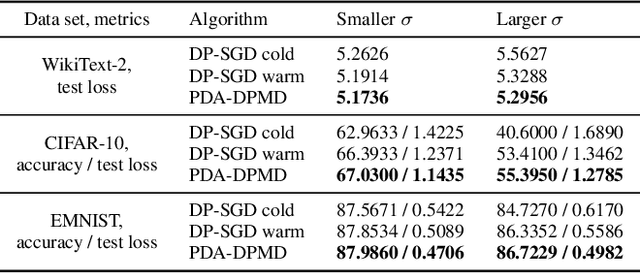

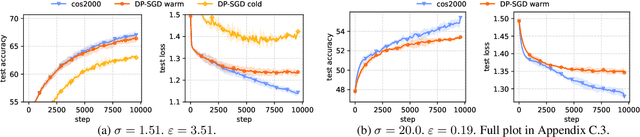
We revisit the problem of using public data to improve the privacy/utility trade-offs for differentially private (DP) model training. Here, public data refers to auxiliary data sets that have no privacy concerns. We consider public data that is from the same distribution as the private training data. For convex losses, we show that a variant of Mirror Descent provides population risk guarantees which are independent of the dimension of the model ($p$). Specifically, we apply Mirror Descent with the loss generated by the public data as the mirror map, and using DP gradients of the loss generated by the private (sensitive) data. To obtain dimension independence, we require $G_Q^2 \leq p$ public data samples, where $G_Q$ is a measure of the isotropy of the loss function. We further show that our algorithm has a natural ``noise stability'' property: If around the current iterate the public loss satisfies $\alpha_v$-strong convexity in a direction $v$, then using noisy gradients instead of the exact gradients shifts our next iterate in the direction $v$ by an amount proportional to $1/\alpha_v$ (in contrast with DP-SGD, where the shift is isotropic). Analogous results in prior works had to explicitly learn the geometry using the public data in the form of preconditioner matrices. Our method is also applicable to non-convex losses, as it does not rely on convexity assumptions to ensure DP guarantees. We demonstrate the empirical efficacy of our algorithm by showing privacy/utility trade-offs on linear regression, deep learning benchmark datasets (WikiText-2, CIFAR-10, and EMNIST), and in federated learning (StackOverflow). We show that our algorithm not only significantly improves over traditional DP-SGD and DP-FedAvg, which do not have access to public data, but also improves over DP-SGD and DP-FedAvg on models that have been pre-trained with the public data to begin with.
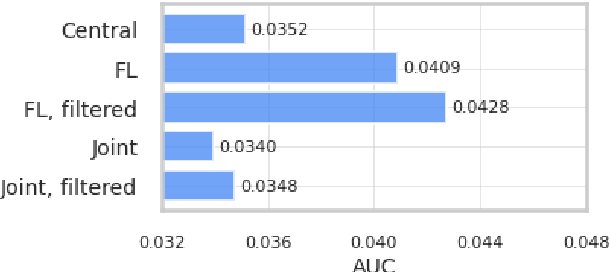
Jointly Learning from Decentralized (Federated) and Centralized Data to Mitigate Distribution Shift
Nov 23, 2021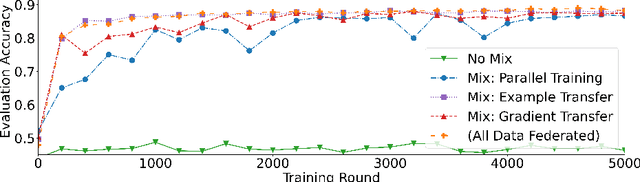
With privacy as a motivation, Federated Learning (FL) is an increasingly used paradigm where learning takes place collectively on edge devices, each with a cache of user-generated training examples that remain resident on the local device. These on-device training examples are gathered in situ during the course of users' interactions with their devices, and thus are highly reflective of at least part of the inference data distribution. Yet a distribution shift may still exist; the on-device training examples may lack for some data inputs expected to be encountered at inference time. This paper proposes a way to mitigate this shift: selective usage of datacenter data, mixed in with FL. By mixing decentralized (federated) and centralized (datacenter) data, we can form an effective training data distribution that better matches the inference data distribution, resulting in more useful models while still meeting the private training data access constraints imposed by FL.
Revealing and Protecting Labels in Distributed Training
Oct 31, 2021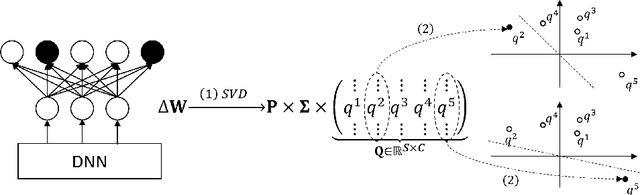
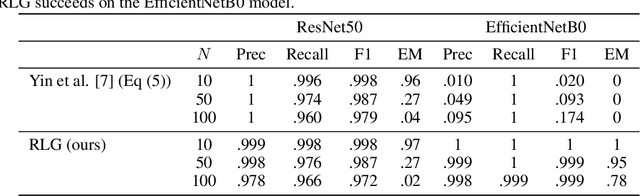
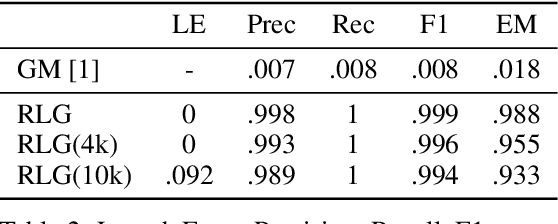
Distributed learning paradigms such as federated learning often involve transmission of model updates, or gradients, over a network, thereby avoiding transmission of private data. However, it is possible for sensitive information about the training data to be revealed from such gradients. Prior works have demonstrated that labels can be revealed analytically from the last layer of certain models (e.g., ResNet), or they can be reconstructed jointly with model inputs by using Gradients Matching [Zhu et al'19] with additional knowledge about the current state of the model. In this work, we propose a method to discover the set of labels of training samples from only the gradient of the last layer and the id to label mapping. Our method is applicable to a wide variety of model architectures across multiple domains. We demonstrate the effectiveness of our method for model training in two domains - image classification, and automatic speech recognition. Furthermore, we show that existing reconstruction techniques improve their efficacy when used in conjunction with our method. Conversely, we demonstrate that gradient quantization and sparsification can significantly reduce the success of the attack.