 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRajesh Ranganath
Set Norm and Equivariant Skip Connections: Putting the Deep in Deep Sets
Jun 23, 2022
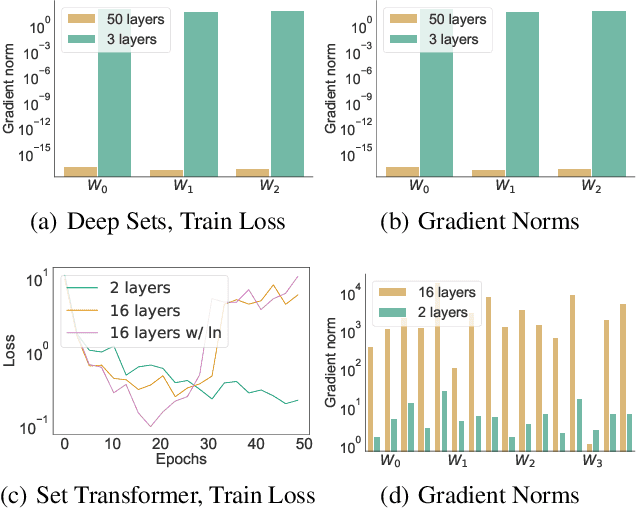
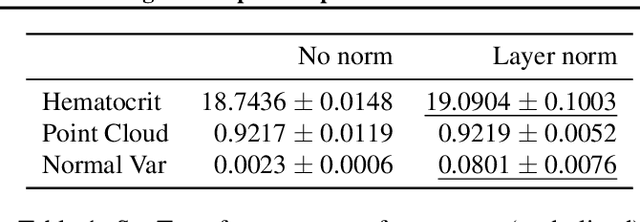
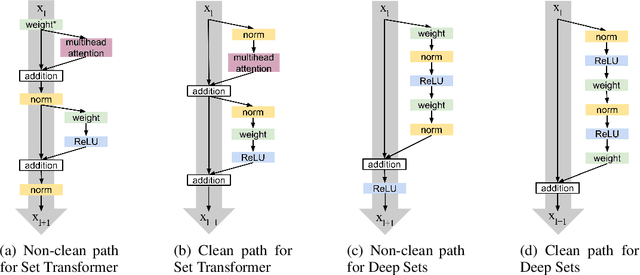
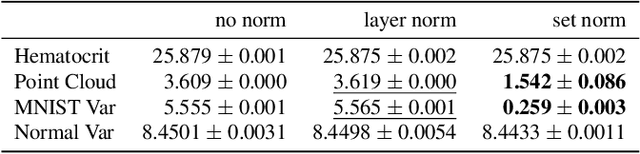
Permutation invariant neural networks are a promising tool for making predictions from sets. However, we show that existing permutation invariant architectures, Deep Sets and Set Transformer, can suffer from vanishing or exploding gradients when they are deep. Additionally, layer norm, the normalization of choice in Set Transformer, can hurt performance by removing information useful for prediction. To address these issues, we introduce the clean path principle for equivariant residual connections and develop set norm, a normalization tailored for sets. With these, we build Deep Sets++ and Set Transformer++, models that reach high depths with comparable or better performance than their original counterparts on a diverse suite of tasks. We additionally introduce Flow-RBC, a new single-cell dataset and real-world application of permutation invariant prediction. We open-source our data and code here: https://github.com/rajesh-lab/deep_permutation_invariant.
New-Onset Diabetes Assessment Using Artificial Intelligence-Enhanced Electrocardiography
May 05, 2022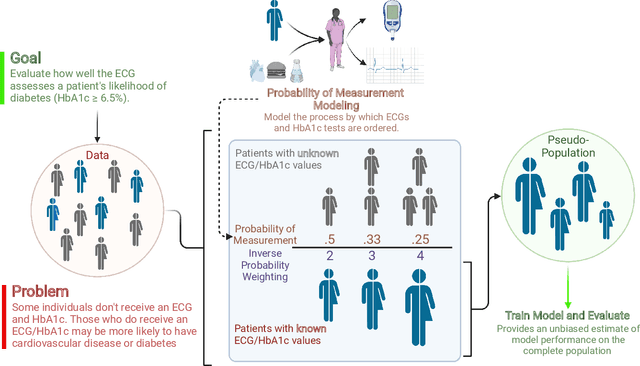
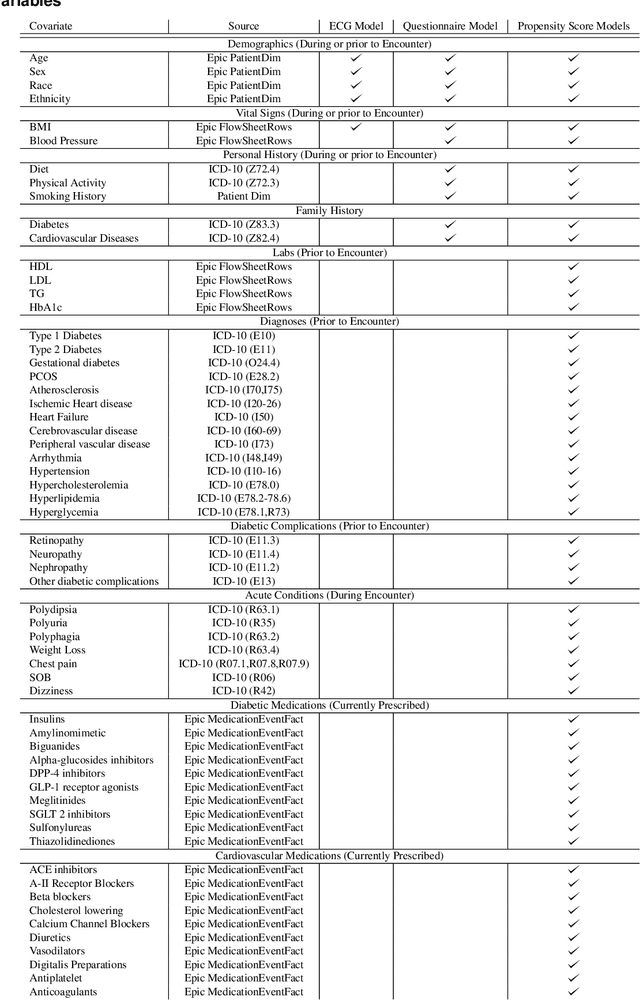
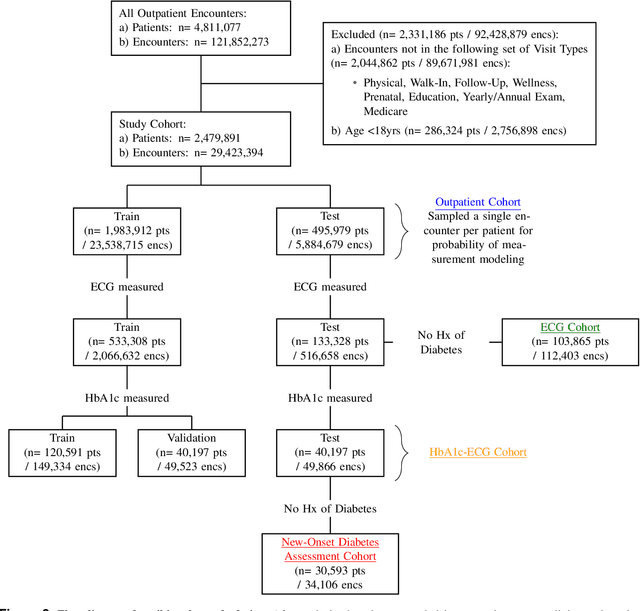
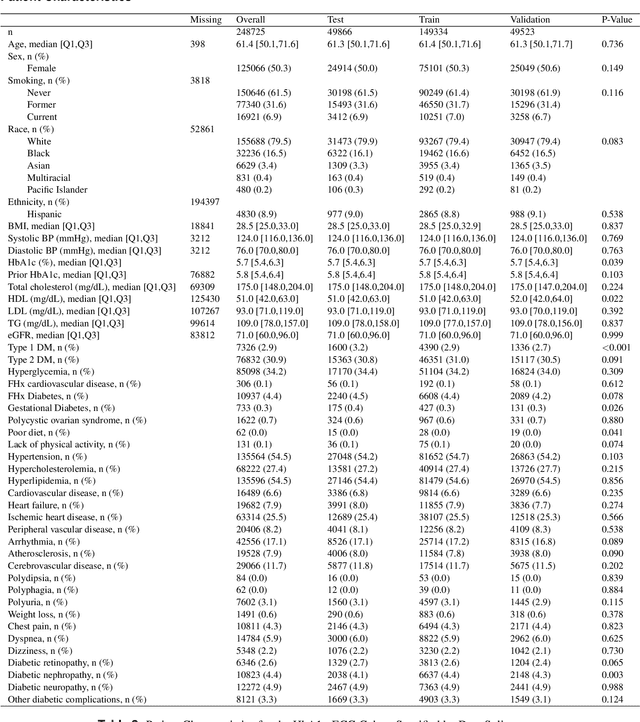
Undiagnosed diabetes is present in 21.4% of adults with diabetes. Diabetes can remain asymptomatic and undetected due to limitations in screening rates. To address this issue, questionnaires, such as the American Diabetes Association (ADA) Risk test, have been recommended for use by physicians and the public. Based on evidence that blood glucose concentration can affect cardiac electrophysiology, we hypothesized that an artificial intelligence (AI)-enhanced electrocardiogram (ECG) could identify adults with new-onset diabetes. We trained a neural network to estimate HbA1c using a 12-lead ECG and readily available demographics. We retrospectively assembled a dataset comprised of patients with paired ECG and HbA1c data. The population of patients who receive both an ECG and HbA1c may a biased sample of the complete outpatient population, so we adjusted the importance placed on each patient to generate a more representative pseudo-population. We found ECG-based assessment outperforms the ADA Risk test, achieving a higher area under the curve (0.80 vs. 0.68) and positive predictive value (14% vs. 9%) -- 2.6 times the prevalence of diabetes in the cohort. The AI-enhanced ECG significantly outperforms electrophysiologist interpretation of the ECG, suggesting that the task is beyond current clinical capabilities. Given the prevalence of ECGs in clinics and via wearable devices, such a tool would make precise, automated diabetes assessment widely accessible.
Quantile Filtered Imitation Learning
Dec 02, 2021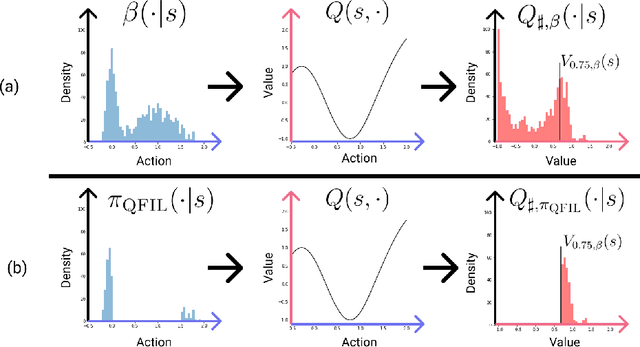
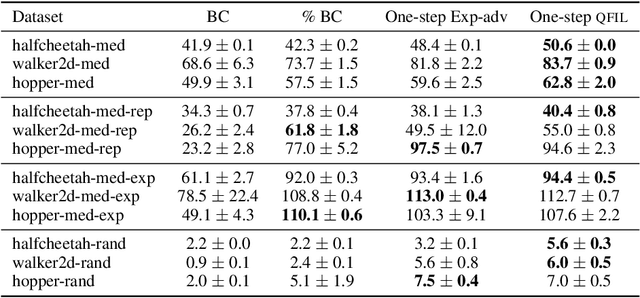
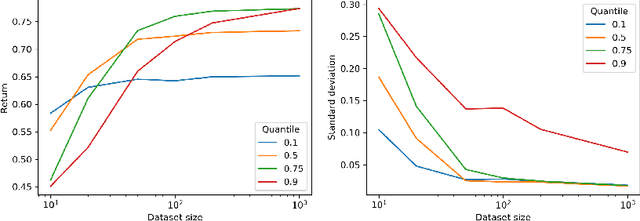
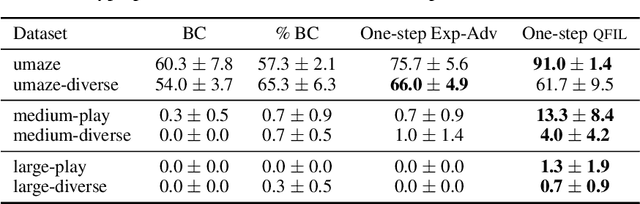
We introduce quantile filtered imitation learning (QFIL), a novel policy improvement operator designed for offline reinforcement learning. QFIL performs policy improvement by running imitation learning on a filtered version of the offline dataset. The filtering process removes $ s,a $ pairs whose estimated Q values fall below a given quantile of the pushforward distribution over values induced by sampling actions from the behavior policy. The definitions of both the pushforward Q distribution and resulting value function quantile are key contributions of our method. We prove that QFIL gives us a safe policy improvement step with function approximation and that the choice of quantile provides a natural hyperparameter to trade off bias and variance of the improvement step. Empirically, we perform a synthetic experiment illustrating how QFIL effectively makes a bias-variance tradeoff and we see that QFIL performs well on the D4RL benchmark.
Learning Invariant Representations with Missing Data
Dec 01, 2021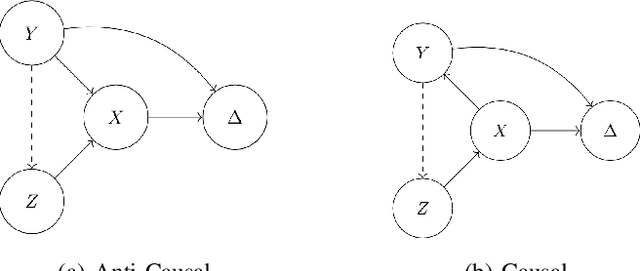



Spurious correlations allow flexible models to predict well during training but poorly on related test populations. Recent work has shown that models that satisfy particular independencies involving correlation-inducing \textit{nuisance} variables have guarantees on their test performance. Enforcing such independencies requires nuisances to be observed during training. However, nuisances, such as demographics or image background labels, are often missing. Enforcing independence on just the observed data does not imply independence on the entire population. Here we derive \acrshort{mmd} estimators used for invariance objectives under missing nuisances. On simulations and clinical data, optimizing through these estimates achieves test performance similar to using estimators that make use of the full data.
Inverse-Weighted Survival Games
Nov 16, 2021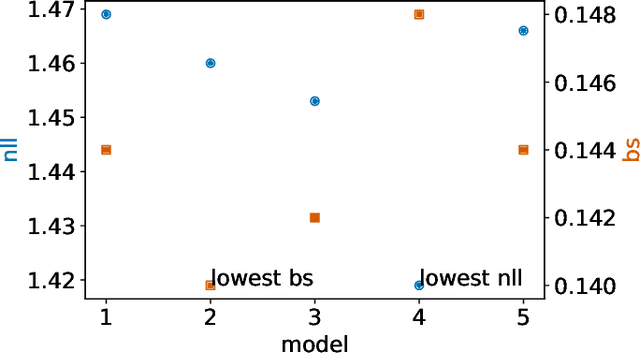
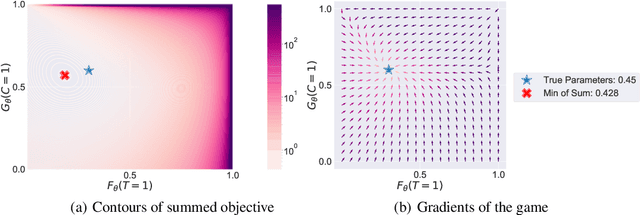
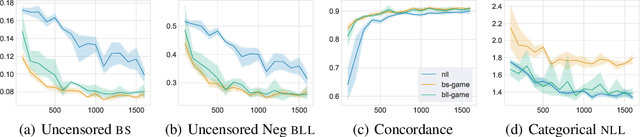
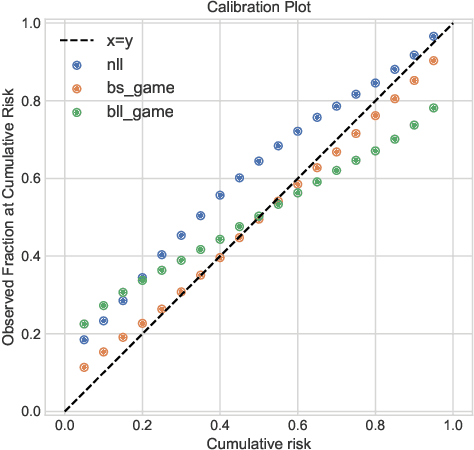
Deep models trained through maximum likelihood have achieved state-of-the-art results for survival analysis. Despite this training scheme, practitioners evaluate models under other criteria, such as binary classification losses at a chosen set of time horizons, e.g. Brier score (BS) and Bernoulli log likelihood (BLL). Models trained with maximum likelihood may have poor BS or BLL since maximum likelihood does not directly optimize these criteria. Directly optimizing criteria like BS requires inverse-weighting by the censoring distribution, estimation of which itself also requires inverse-weighted by the failure distribution. But neither are known. To resolve this dilemma, we introduce Inverse-Weighted Survival Games to train both failure and censoring models with respect to criteria such as BS or BLL. In these games, objectives for each model are built from re-weighted estimates featuring the other model, where the re-weighting model is held fixed during training. When the loss is proper, we show that the games always have the true failure and censoring distributions as a stationary point. This means models in the game do not leave the correct distributions once reached. We construct one case where this stationary point is unique. We show that these games optimize BS on simulations and then apply these principles on real world cancer and critically-ill patient data.
Understanding Failures in Out-of-Distribution Detection with Deep Generative Models
Jul 16, 2021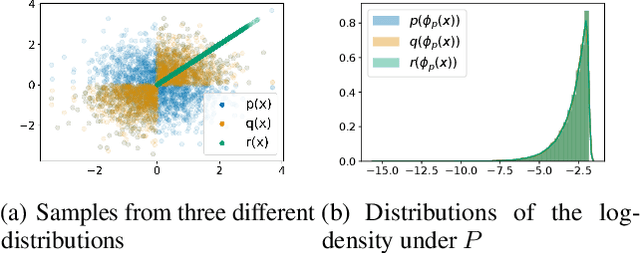

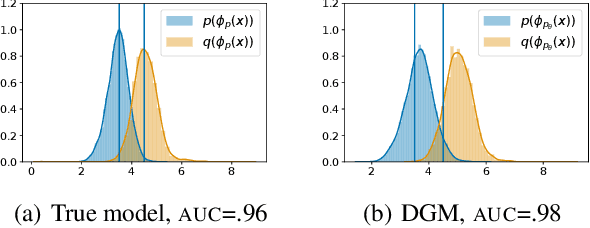
Deep generative models (DGMs) seem a natural fit for detecting out-of-distribution (OOD) inputs, but such models have been shown to assign higher probabilities or densities to OOD images than images from the training distribution. In this work, we explain why this behavior should be attributed to model misestimation. We first prove that no method can guarantee performance beyond random chance without assumptions on which out-distributions are relevant. We then interrogate the typical set hypothesis, the claim that relevant out-distributions can lie in high likelihood regions of the data distribution, and that OOD detection should be defined based on the data distribution's typical set. We highlight the consequences implied by assuming support overlap between in- and out-distributions, as well as the arbitrariness of the typical set for OOD detection. Our results suggest that estimation error is a more plausible explanation than the misalignment between likelihood-based OOD detection and out-distributions of interest, and we illustrate how even minimal estimation error can lead to OOD detection failures, yielding implications for future work in deep generative modeling and OOD detection.
FastSHAP: Real-Time Shapley Value Estimation
Jul 15, 2021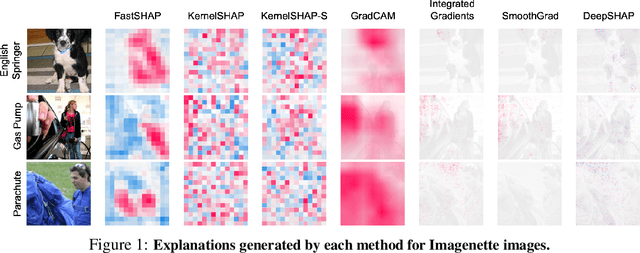
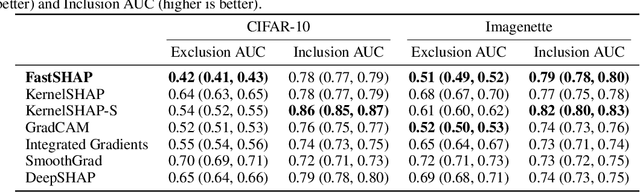
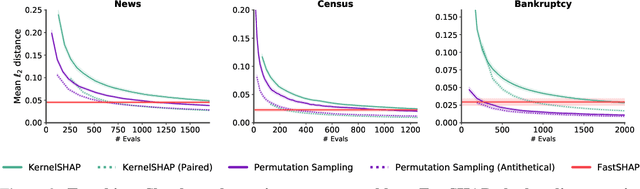
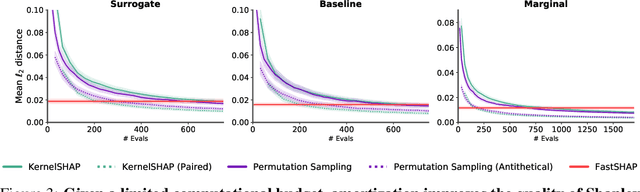
Shapley values are widely used to explain black-box models, but they are costly to calculate because they require many model evaluations. We introduce FastSHAP, a method for estimating Shapley values in a single forward pass using a learned explainer model. FastSHAP amortizes the cost of explaining many inputs via a learning approach inspired by the Shapley value's weighted least squares characterization, and it can be trained using standard stochastic gradient optimization. We compare FastSHAP to existing estimation approaches, revealing that it generates high-quality explanations with orders of magnitude speedup.
Predictive Modeling in the Presence of Nuisance-Induced Spurious Correlations
Jul 06, 2021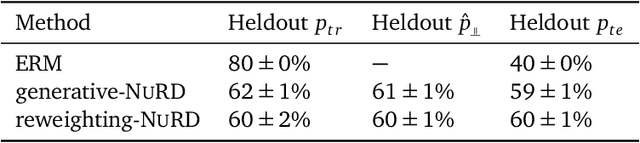
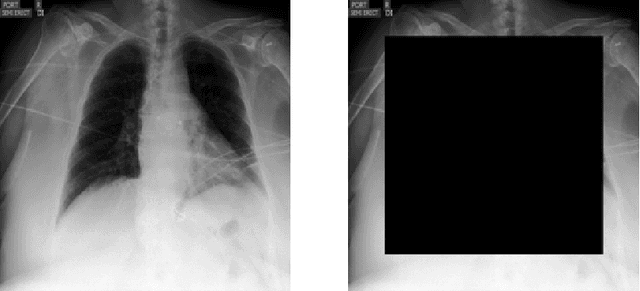
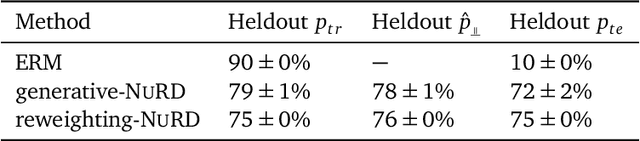
Deep predictive models often make use of spurious correlations between the label and the covariates that differ between training and test distributions. In many classification tasks, spurious correlations are induced by a changing relationship between the label and some nuisance variables correlated with the covariates. For example, in classifying animals in natural images, the background, which is the nuisance, can predict the type of animal. This nuisance-label relationship does not always hold. We formalize a family of distributions that only differ in the nuisance-label relationship and introduce a distribution where this relationship is broken called the nuisance-randomized distribution. We introduce a set of predictive models built from the nuisance-randomized distribution with representations, that when conditioned on, do not correlate the label and the nuisance. For models in this set, we lower bound the performance for any member of the family with the mutual information between the representation and the label under the nuisance-randomized distribution. To build predictive models that maximize the performance lower bound, we develop Nuisance-Randomized Distillation (NURD). We evaluate NURD on a synthetic example, colored-MNIST, and classifying chest X-rays. When using non-lung patches as the nuisance in classifying chest X-rays, NURD produces models that predict pneumonia under strong spurious correlations.
Offline RL Without Off-Policy Evaluation
Jun 16, 2021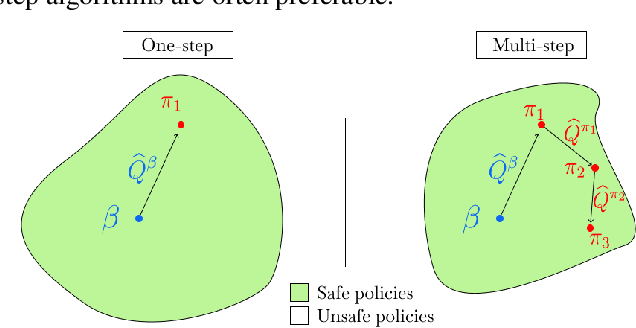
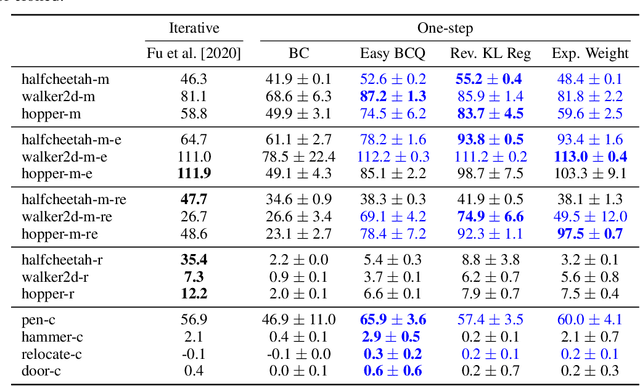

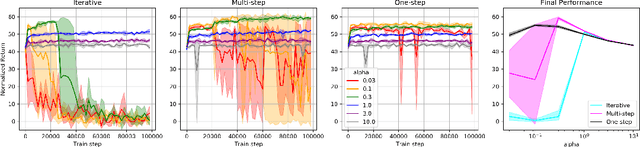
Most prior approaches to offline reinforcement learning (RL) have taken an iterative actor-critic approach involving off-policy evaluation. In this paper we show that simply doing one step of constrained/regularized policy improvement using an on-policy Q estimate of the behavior policy performs surprisingly well. This one-step algorithm beats the previously reported results of iterative algorithms on a large portion of the D4RL benchmark. The simple one-step baseline achieves this strong performance without many of the tricks used by previously proposed iterative algorithms and is more robust to hyperparameters. We argue that the relatively poor performance of iterative approaches is a result of the high variance inherent in doing off-policy evaluation and magnified by the repeated optimization of policies against those high-variance estimates. In addition, we hypothesize that the strong performance of the one-step algorithm is due to a combination of favorable structure in the environment and behavior policy.