 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInverse-Weighted Survival Games
Nov 16, 2021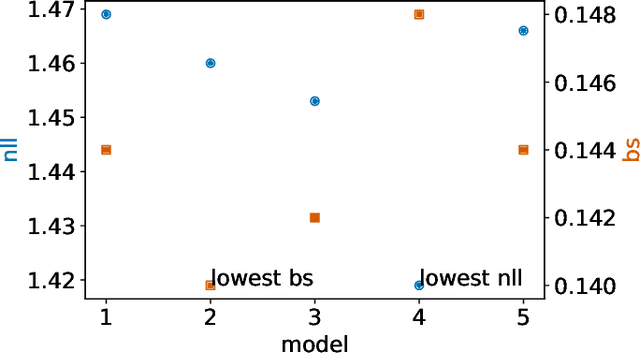
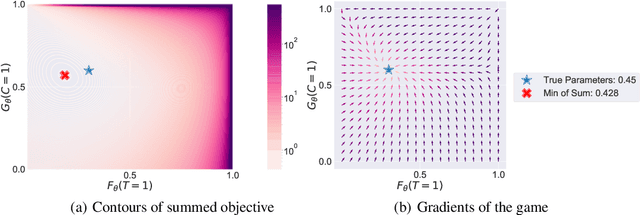
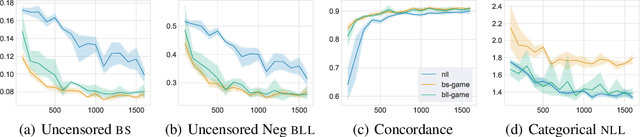
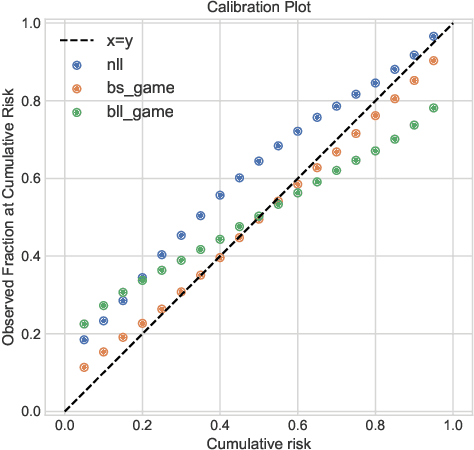
Deep models trained through maximum likelihood have achieved state-of-the-art results for survival analysis. Despite this training scheme, practitioners evaluate models under other criteria, such as binary classification losses at a chosen set of time horizons, e.g. Brier score (BS) and Bernoulli log likelihood (BLL). Models trained with maximum likelihood may have poor BS or BLL since maximum likelihood does not directly optimize these criteria. Directly optimizing criteria like BS requires inverse-weighting by the censoring distribution, estimation of which itself also requires inverse-weighted by the failure distribution. But neither are known. To resolve this dilemma, we introduce Inverse-Weighted Survival Games to train both failure and censoring models with respect to criteria such as BS or BLL. In these games, objectives for each model are built from re-weighted estimates featuring the other model, where the re-weighting model is held fixed during training. When the loss is proper, we show that the games always have the true failure and censoring distributions as a stationary point. This means models in the game do not leave the correct distributions once reached. We construct one case where this stationary point is unique. We show that these games optimize BS on simulations and then apply these principles on real world cancer and critically-ill patient data.
Beyond The Text: Analysis of Privacy Statements through Syntactic and Semantic Role Labeling
Oct 01, 2020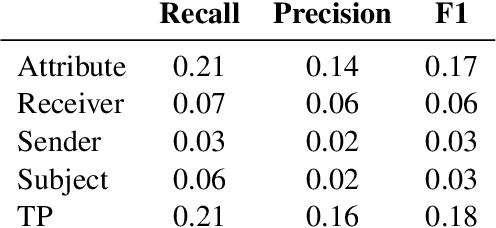
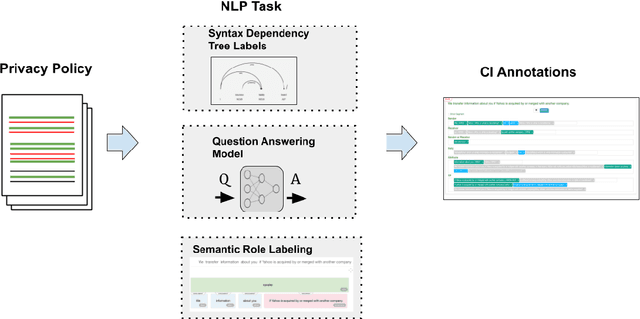
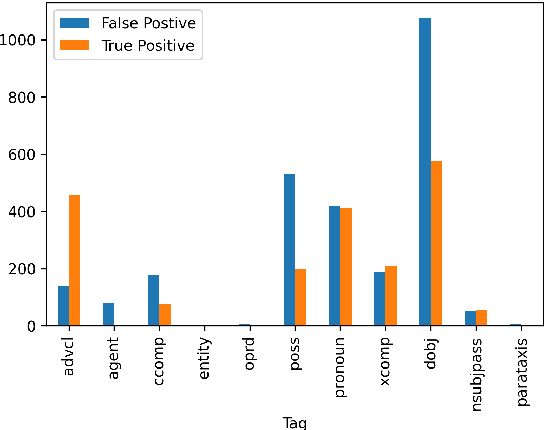

This paper formulates a new task of extracting privacy parameters from a privacy policy, through the lens of Contextual Integrity, an established social theory framework for reasoning about privacy norms. Privacy policies, written by lawyers, are lengthy and often comprise incomplete and vague statements. In this paper, we show that traditional NLP tasks, including the recently proposed Question-Answering based solutions, are insufficient to address the privacy parameter extraction problem and provide poor precision and recall. We describe 4 different types of conventional methods that can be partially adapted to address the parameter extraction task with varying degrees of success: Hidden Markov Models, BERT fine-tuned models, Dependency Type Parsing (DP) and Semantic Role Labeling (SRL). Based on a detailed evaluation across 36 real-world privacy policies of major enterprises, we demonstrate that a solution combining syntactic DP coupled with type-specific SRL tasks provides the highest accuracy for retrieving contextual privacy parameters from privacy statements. We also observe that incorporating domain-specific knowledge is critical to achieving high precision and recall, thus inspiring new NLP research to address this important problem in the privacy domain.
Learning Invariants using Decision Trees
Jan 20, 2015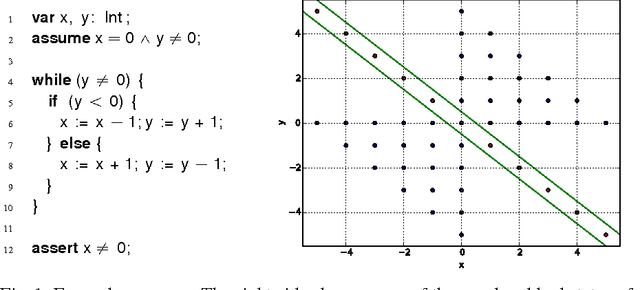
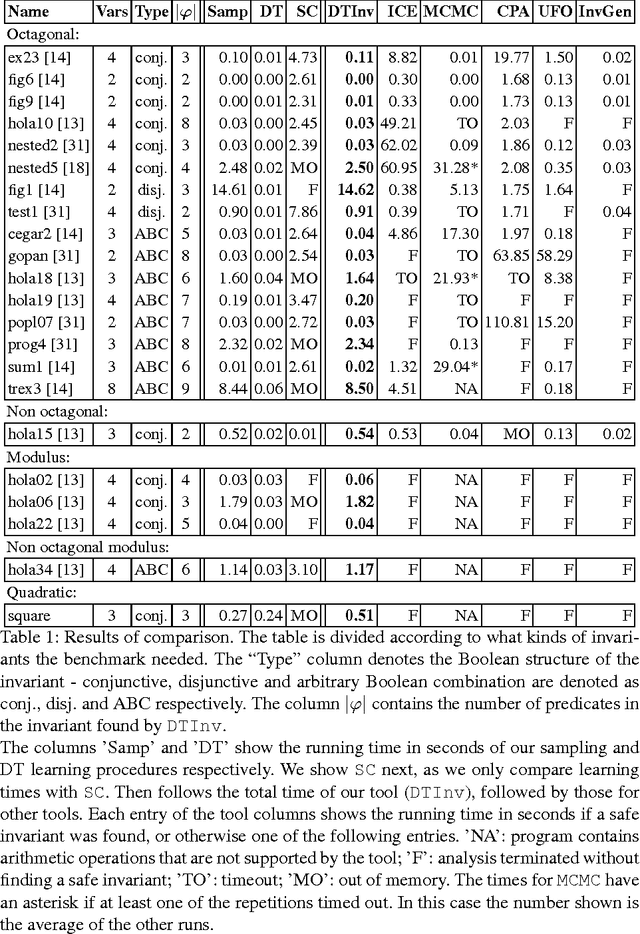
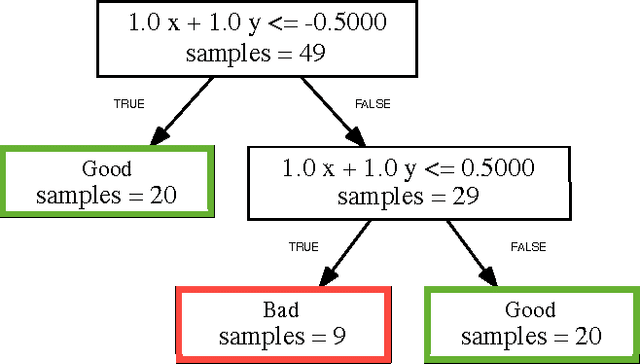
The problem of inferring an inductive invariant for verifying program safety can be formulated in terms of binary classification. This is a standard problem in machine learning: given a sample of good and bad points, one is asked to find a classifier that generalizes from the sample and separates the two sets. Here, the good points are the reachable states of the program, and the bad points are those that reach a safety property violation. Thus, a learned classifier is a candidate invariant. In this paper, we propose a new algorithm that uses decision trees to learn candidate invariants in the form of arbitrary Boolean combinations of numerical inequalities. We have used our algorithm to verify C programs taken from the literature. The algorithm is able to infer safe invariants for a range of challenging benchmarks and compares favorably to other ML-based invariant inference techniques. In particular, it scales well to large sample sets.