 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParadox of De-identification: A Critique of HIPAA Safe Harbour in the Age of LLMs
Feb 09, 2026Privacy is a human right that sustains patient-provider trust. Clinical notes capture a patient's private vulnerability and individuality, which are used for care coordination and research. Under HIPAA Safe Harbor, these notes are de-identified to protect patient privacy. However, Safe Harbor was designed for an era of categorical tabular data, focusing on the removal of explicit identifiers while ignoring the latent information found in correlations between identity and quasi-identifiers, which can be captured by modern LLMs. We first formalize these correlations using a causal graph, then validate it empirically through individual re-identification of patients from scrubbed notes. The paradox of de-identification is further shown through a diagnosis ablation: even when all other information is removed, the model can predict the patient's neighborhood based on diagnosis alone. This position paper raises the question of how we can act as a community to uphold patient-provider trust when de-identification is inherently imperfect. We aim to raise awareness and discuss actionable recommendations.
Gateformer: Advancing Multivariate Time Series Forecasting through Temporal and Variate-Wise Attention with Gated Representations
May 01, 2025



There has been a recent surge of interest in time series modeling using the Transformer architecture. However, forecasting multivariate time series with Transformer presents a unique challenge as it requires modeling both temporal (cross-time) and variate (cross-variate) dependencies. While Transformer-based models have gained popularity for their flexibility in capturing both sequential and cross-variate relationships, it is unclear how to best integrate these two sources of information in the context of the Transformer architecture while optimizing for both performance and efficiency. We re-purpose the Transformer architecture to effectively model both cross-time and cross-variate dependencies. Our approach begins by embedding each variate independently into a variate-wise representation that captures its cross-time dynamics, and then models cross-variate dependencies through attention mechanisms on these learned embeddings. Gating operations in both cross-time and cross-variate modeling phases regulate information flow, allowing the model to focus on the most relevant features for accurate predictions. Our method achieves state-of-the-art performance across 13 real-world datasets and can be seamlessly integrated into other Transformer-based and LLM-based forecasters, delivering performance improvements up to 20.7\% over original models. Code is available at this repository: https://github.com/nyuolab/Gateformer.
Language Model Classifier Aligns Better with Physician Word Sensitivity than XGBoost on Readmission Prediction
Nov 15, 2022



Traditional evaluation metrics for classification in natural language processing such as accuracy and area under the curve fail to differentiate between models with different predictive behaviors despite their similar performance metrics. We introduce sensitivity score, a metric that scrutinizes models' behaviors at the vocabulary level to provide insights into disparities in their decision-making logic. We assess the sensitivity score on a set of representative words in the test set using two classifiers trained for hospital readmission classification with similar performance statistics. Our experiments compare the decision-making logic of clinicians and classifiers based on rank correlations of sensitivity scores. The results indicate that the language model's sensitivity score aligns better with the professionals than the xgboost classifier on tf-idf embeddings, which suggests that xgboost uses some spurious features. Overall, this metric offers a novel perspective on assessing models' robustness by quantifying their discrepancy with professional opinions. Our code is available on GitHub (https://github.com/nyuolab/Model_Sensitivity).
Predictive Modeling in the Presence of Nuisance-Induced Spurious Correlations
Jul 06, 2021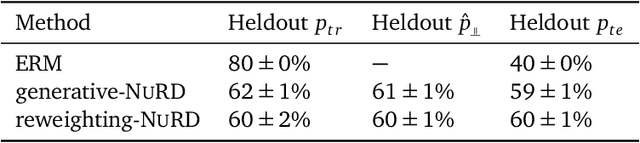
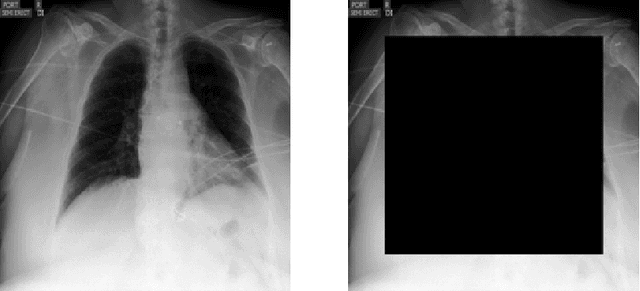
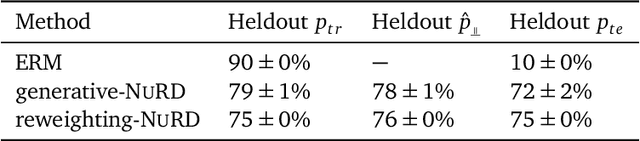
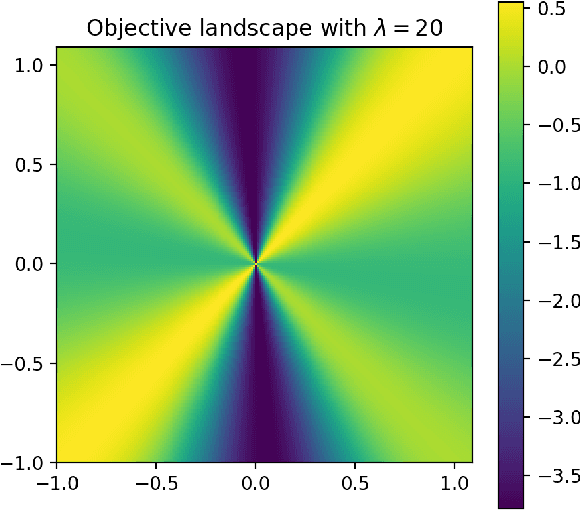
Deep predictive models often make use of spurious correlations between the label and the covariates that differ between training and test distributions. In many classification tasks, spurious correlations are induced by a changing relationship between the label and some nuisance variables correlated with the covariates. For example, in classifying animals in natural images, the background, which is the nuisance, can predict the type of animal. This nuisance-label relationship does not always hold. We formalize a family of distributions that only differ in the nuisance-label relationship and introduce a distribution where this relationship is broken called the nuisance-randomized distribution. We introduce a set of predictive models built from the nuisance-randomized distribution with representations, that when conditioned on, do not correlate the label and the nuisance. For models in this set, we lower bound the performance for any member of the family with the mutual information between the representation and the label under the nuisance-randomized distribution. To build predictive models that maximize the performance lower bound, we develop Nuisance-Randomized Distillation (NURD). We evaluate NURD on a synthetic example, colored-MNIST, and classifying chest X-rays. When using non-lung patches as the nuisance in classifying chest X-rays, NURD produces models that predict pneumonia under strong spurious correlations.
Confounding variables can degrade generalization performance of radiological deep learning models
Jul 13, 2018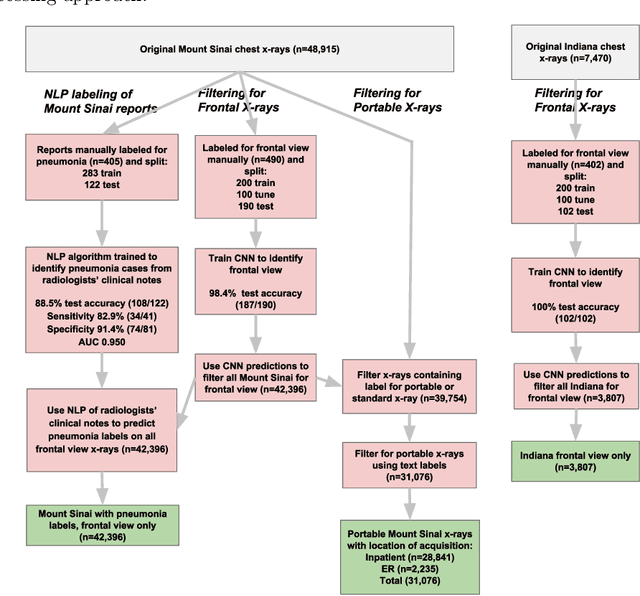
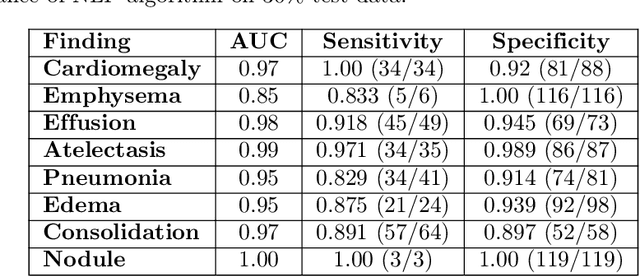
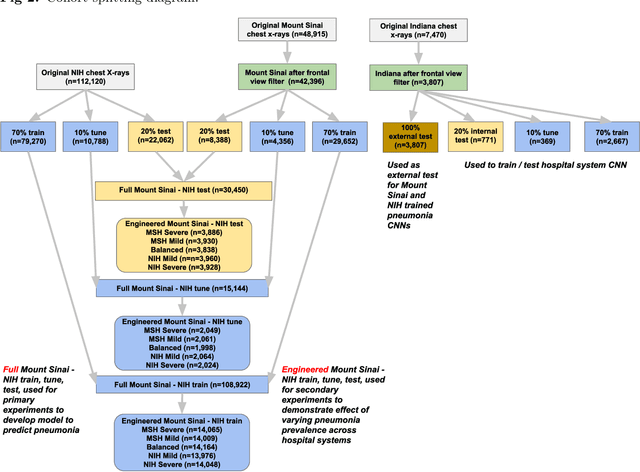
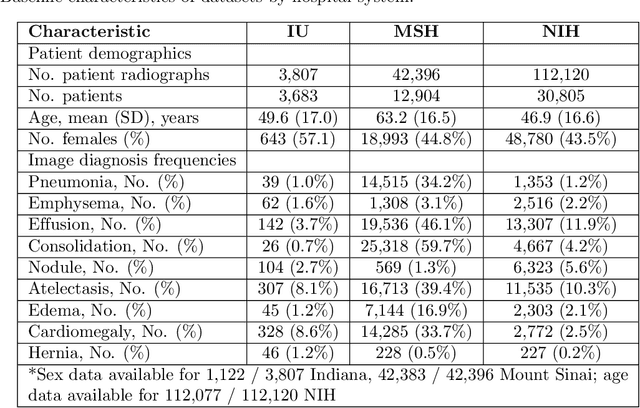
Early results in using convolutional neural networks (CNNs) on x-rays to diagnose disease have been promising, but it has not yet been shown that models trained on x-rays from one hospital or one group of hospitals will work equally well at different hospitals. Before these tools are used for computer-aided diagnosis in real-world clinical settings, we must verify their ability to generalize across a variety of hospital systems. A cross-sectional design was used to train and evaluate pneumonia screening CNNs on 158,323 chest x-rays from NIH (n=112,120 from 30,805 patients), Mount Sinai (42,396 from 12,904 patients), and Indiana (n=3,807 from 3,683 patients). In 3 / 5 natural comparisons, performance on chest x-rays from outside hospitals was significantly lower than on held-out x-rays from the original hospital systems. CNNs were able to detect where an x-ray was acquired (hospital system, hospital department) with extremely high accuracy and calibrate predictions accordingly. The performance of CNNs in diagnosing diseases on x-rays may reflect not only their ability to identify disease-specific imaging findings on x-rays, but also their ability to exploit confounding information. Estimates of CNN performance based on test data from hospital systems used for model training may overstate their likely real-world performance.