 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntroduction to deep learning
Feb 29, 2020
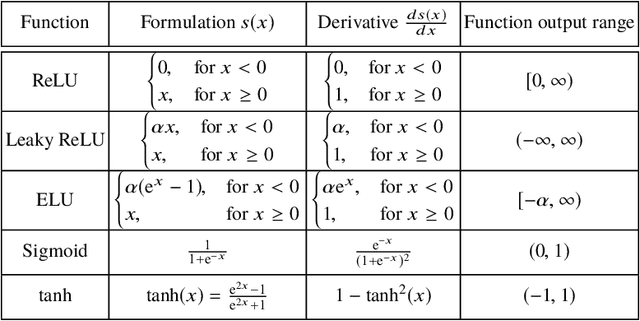
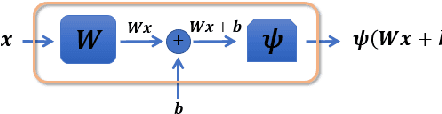

Deep Learning (DL) has made a major impact on data science in the last decade. This chapter introduces the basic concepts of this field. It includes both the basic structures used to design deep neural networks and a brief survey of some of its popular use cases.
Motion Deblurring using Spatiotemporal Phase Aperture Coding
Feb 18, 2020
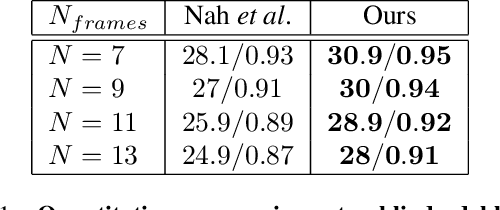

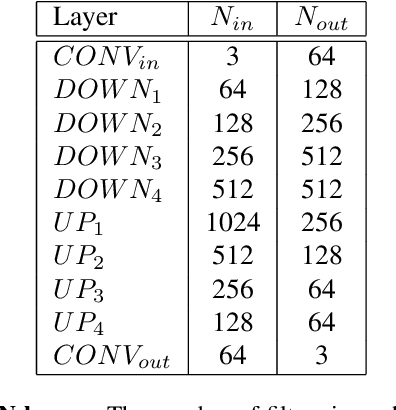
Motion blur is a known issue in photography, as it limits the exposure time while capturing moving objects. Extensive research has been carried to compensate for it. In this work, a computational imaging approach for motion deblurring is proposed and demonstrated. Using dynamic phase-coding in the lens aperture during the image acquisition, the trajectory of the motion is encoded in an intermediate optical image. This encoding embeds both the motion direction and extent by coloring the spatial blur of each object. The color cues serve as prior information for a blind deblurring process, implemented using a convolutional neural network (CNN) trained to utilize such coding for image restoration. We demonstrate the advantage of the proposed approach over blind-deblurring with no coding and other solutions that use coded acquisition, both in simulation and real-world experiments.
Supervised and Unsupervised Learning of Parameterized Color Enhancement
Dec 30, 2019
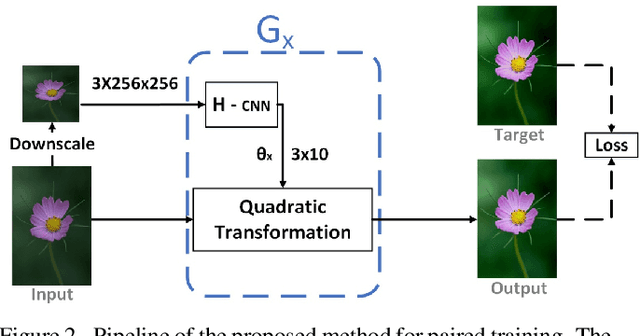

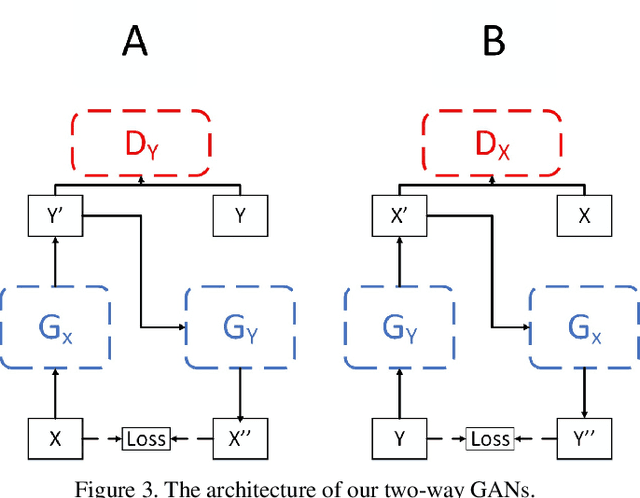
We treat the problem of color enhancement as an image translation task, which we tackle using both supervised and unsupervised learning. Unlike traditional image to image generators, our translation is performed using a global parameterized color transformation instead of learning to directly map image information. In the supervised case, every training image is paired with a desired target image and a convolutional neural network (CNN) learns from the expert retouched images the parameters of the transformation. In the unpaired case, we employ two-way generative adversarial networks (GANs) to learn these parameters and apply a circularity constraint. We achieve state-of-the-art results compared to both supervised (paired data) and unsupervised (unpaired data) image enhancement methods on the MIT-Adobe FiveK benchmark. Moreover, we show the generalization capability of our method, by applying it on photos from the early 20th century and to dark video frames.
DEGAS: Differentiable Efficient Generator Search
Dec 18, 2019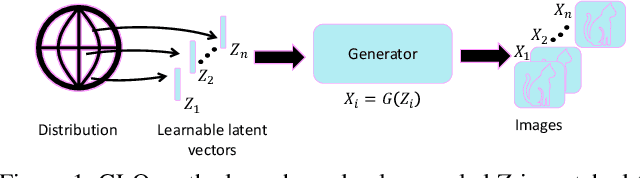
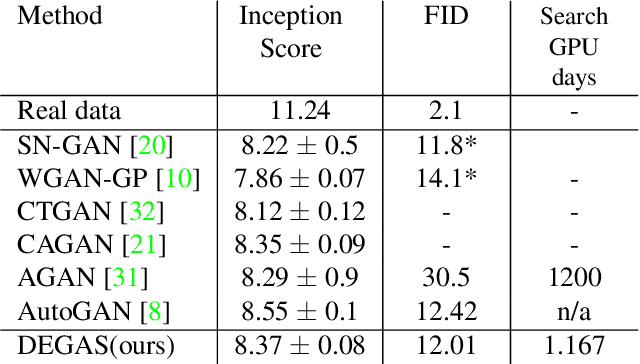
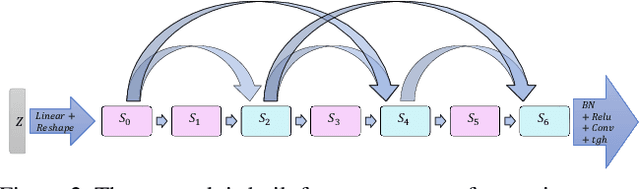
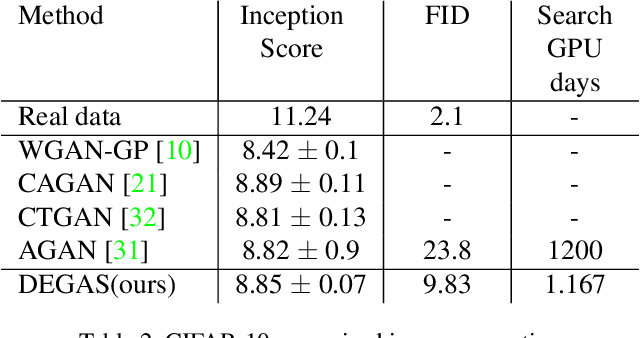
Network architecture search (NAS) achieves state-of-the-art results in various tasks such as classification and semantic segmentation. Recently, a reinforcement learning-based approach has been proposed for Generative Adversarial Networks (GANs) search. In this work, we propose an alternative strategy for GAN search by using a method called DEGAS (Differentiable Efficient GenerAtor Search), which focuses on efficiently finding the generator in the GAN. Our search algorithm is inspired by the differential architecture search strategy and the Global Latent Optimization (GLO) procedure. This leads to both an efficient and stable GAN search. After the generator architecture is found, it can be plugged into any existing framework for GAN training. For CTGAN, which we use in this work, the new model outperforms the original inception score results by 0.25 for CIFAR-10 and 0.77 for STL. It also gets better results than the RL based GAN search methods in shorter search time.
MetAdapt: Meta-Learned Task-Adaptive Architecture for Few-Shot Classification
Dec 03, 2019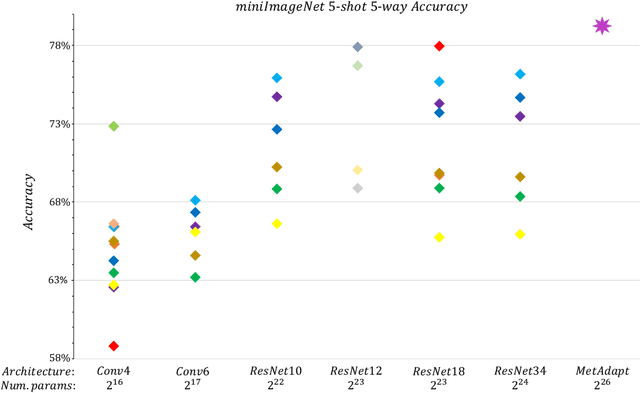

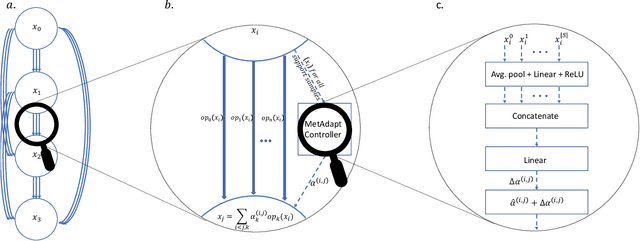
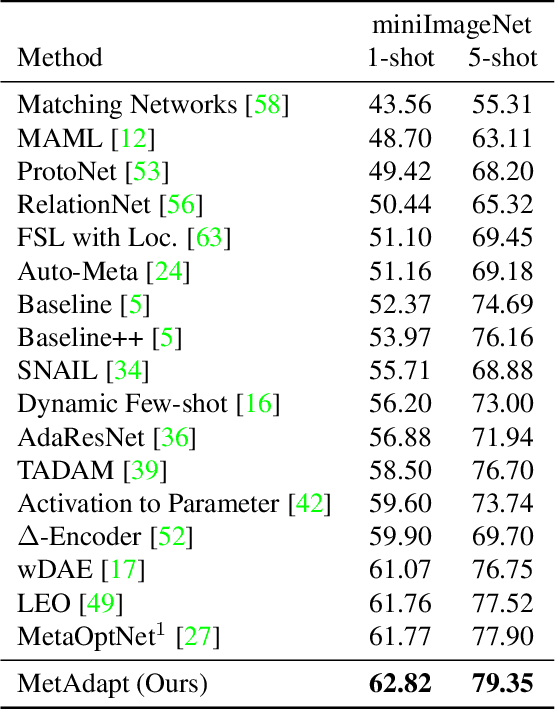
Few-Shot Learning (FSL) is a topic of rapidly growing interest. Typically, in FSL a model is trained on a dataset consisting of many small tasks (meta-tasks) and learns to adapt to novel tasks that it will encounter during test time. This is also referred to as meta-learning. So far, meta-learning FSL methods have focused on optimizing parameters of pre-defined network architectures, in order to make them easily adaptable to novel tasks. Moreover, it was observed that, in general, larger architectures perform better than smaller ones up to a certain saturation point (and even degrade due to over-fitting). However, little attention has been given to explicitly optimizing the architectures for FSL, nor to an adaptation of the architecture at test time to particular novel tasks. In this work, we propose to employ tools borrowed from the Differentiable Neural Architecture Search (D-NAS) literature in order to optimize the architecture for FSL without over-fitting. Additionally, to make the architecture task adaptive, we propose the concept of `MetAdapt Controller' modules. These modules are added to the model and are meta-trained to predict the optimal network connections for a given novel task. Using the proposed approach we observe state-of-the-art results on two popular few-shot benchmarks: miniImageNet and FC100.
Correction Filter for Single Image Super-Resolution: Robustifying Off-the-Shelf Deep Super-Resolvers
Nov 30, 2019
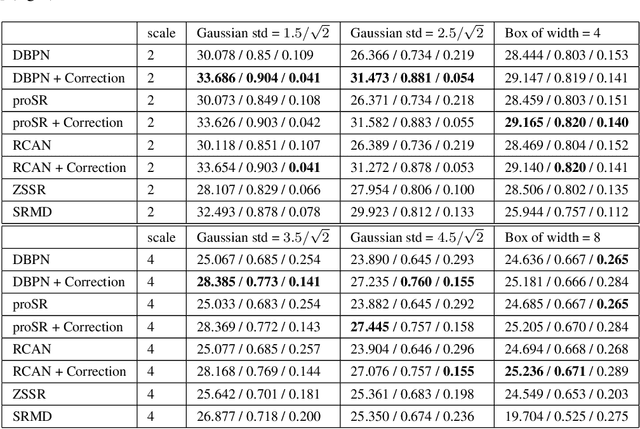

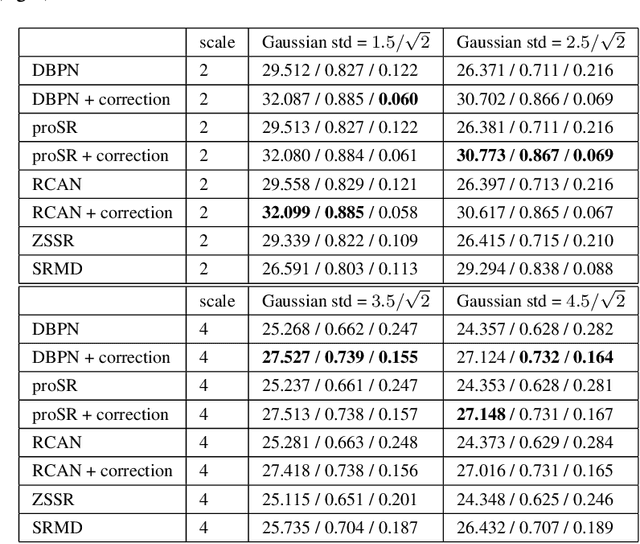
The single image super-resolution task is one of the most examined inverse problems in the past decade. In the recent years, Deep Neural Networks (DNNs) have shown superior performance over alternative methods when the acquisition process uses a fixed known downsampling kernel-typically a bicubic kernel. However, several recent works have shown that in practical scenarios, where the test data mismatch the training data (e.g. when the downsampling kernel is not the bicubic kernel or is not available at training), the leading DNN methods suffer from a huge performance drop. Inspired by the literature on generalized sampling, in this work we propose a method for improving the performance of DNNs that have been trained with a fixed kernel on observations acquired by other kernels. For a known kernel, we design a closed-form correction filter that modifies the low-resolution image to match one which is obtained by another kernel (e.g. bicubic), and thus improves the results of existing pre-trained DNNs. For an unknown kernel, we extend this idea and propose an algorithm for blind estimation of the required correction filter. We show that our approach outperforms other super-resolution methods, which are designed for general downsampling kernels.
MonSter: Awakening the Mono in Stereo
Oct 30, 2019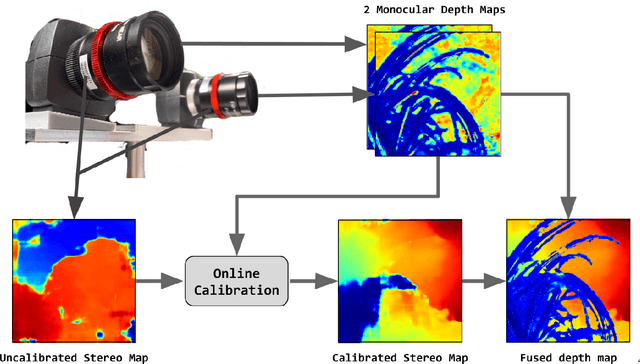
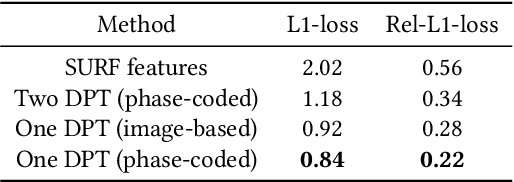
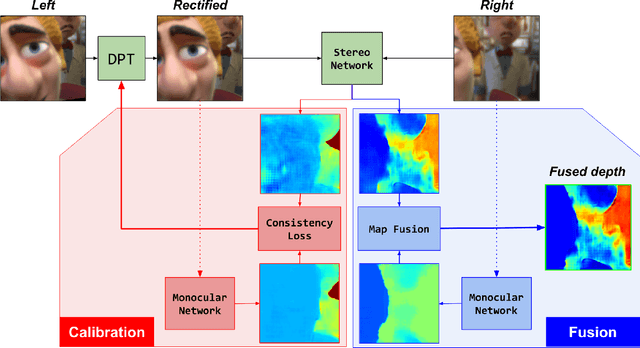

Passive depth estimation is among the most long-studied fields in computer vision. The most common methods for passive depth estimation are either a stereo or a monocular system. Using the former requires an accurate calibration process, and has a limited effective range. The latter, which does not require extrinsic calibration but generally achieves inferior depth accuracy, can be tuned to achieve better results in part of the depth range. In this work, we suggest combining the two frameworks. We propose a two-camera system, in which the cameras are used jointly to extract a stereo depth and individually to provide a monocular depth from each camera. The combination of these depth maps leads to more accurate depth estimation. Moreover, enforcing consistency between the extracted maps leads to a novel online self-calibration strategy. We present a prototype camera that demonstrates the benefits of the proposed combination, for both self-calibration and depth reconstruction in real-world scenes.
Detecting Adversarial Samples Using Influence Functions and Nearest Neighbors
Sep 15, 2019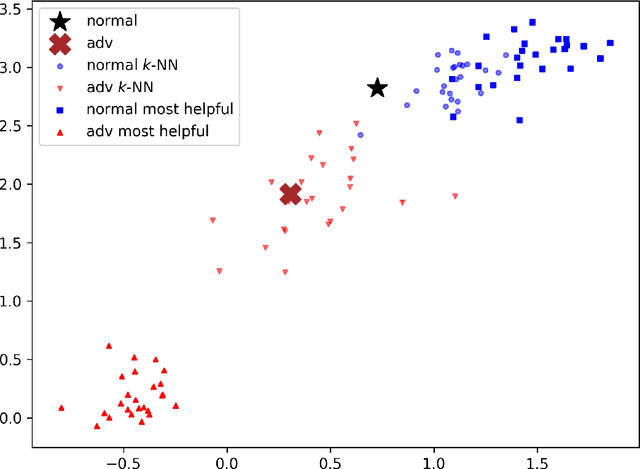
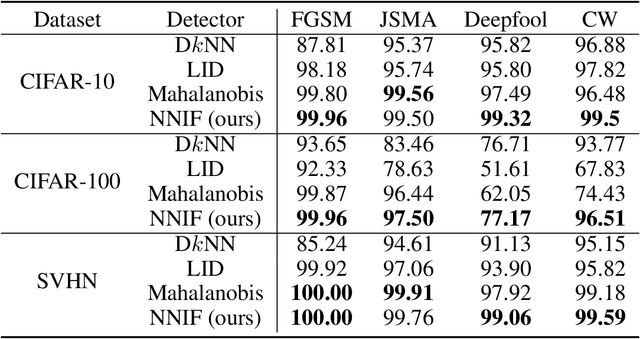
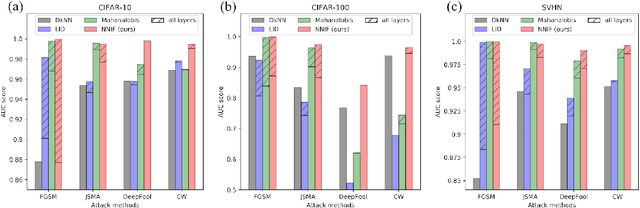
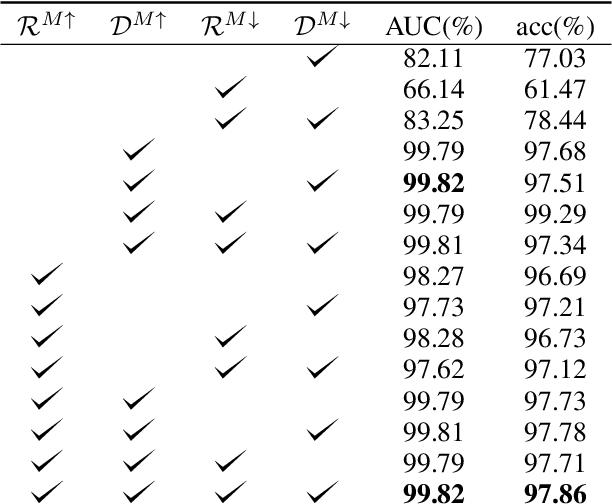
Deep neural networks (DNNs) are notorious for their vulnerability to adversarial attacks, which are small perturbations added to their input images to mislead their prediction. Detection of adversarial examples is, therefore, a fundamental requirement for robust classification frameworks. In this work, we present a method for detecting such adversarial attacks, which is suitable for any pre-trained neural network classifier. We use influence functions to measure the impact of every training sample on the validation set data. From the influence scores, we find the most supportive training samples for any given validation example. A k-nearest neighbor (k-NN) model fitted on the DNN's activation layers is employed to search for the ranking of these supporting training samples. We observe that these samples are highly correlated with the nearest neighbors of the normal inputs, while this correlation is much weaker for adversarial inputs. We train an adversarial detector using the k-NN ranks and distances and show that it successfully distinguishes adversarial examples, getting state-of-the-art results on four attack methods with three datasets.
Deep Radar Detector
Jun 26, 2019
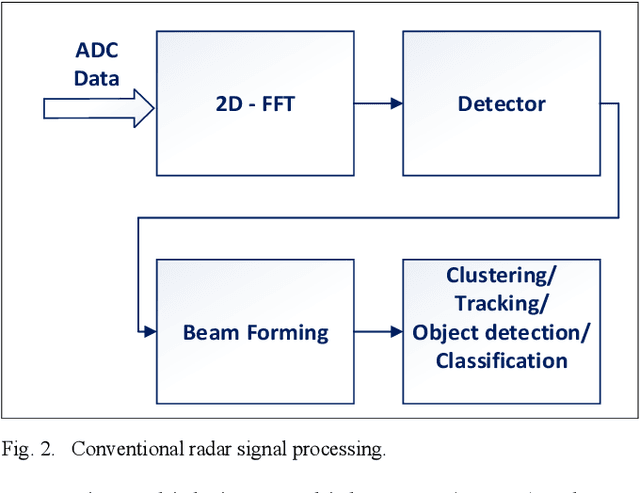
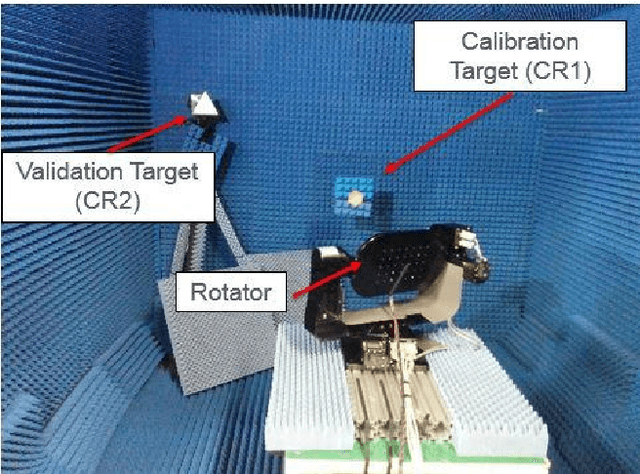
While camera and LiDAR processing have been revolutionized since the introduction of deep learning, radar processing still relies on classical tools. In this paper, we introduce a deep learning approach for radar processing, working directly with the radar complex data. To overcome the lack of radar labeled data, we rely in training only on the radar calibration data and introduce new radar augmentation techniques. We evaluate our method on the radar 4D detection task and demonstrate superior performance compared to the classical approaches while keeping real-time performance. Applying deep learning on radar data has several advantages such as eliminating the need for an expensive radar calibration process each time and enabling classification of the detected objects with almost zero-overhead.
Back-Projection based Fidelity Term for Ill-Posed Linear Inverse Problems
Jun 16, 2019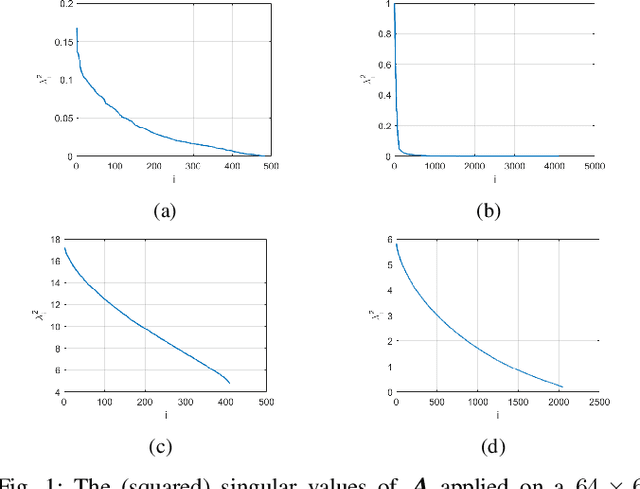
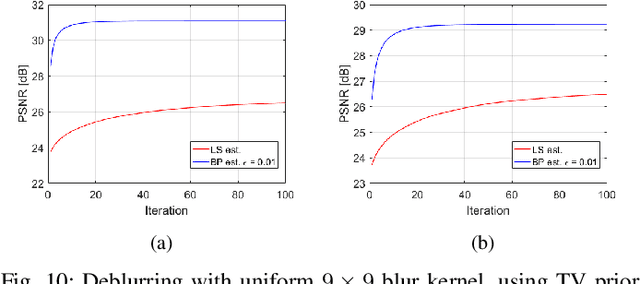
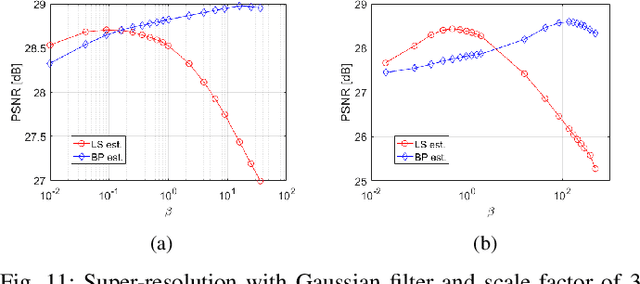
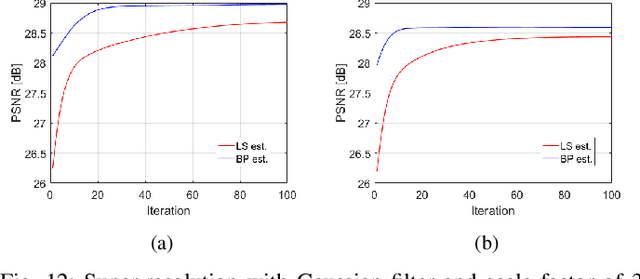
Ill-posed linear inverse problems appear in many image processing applications, such as deblurring, super-resolution and compressed sensing. Many restoration strategies involve minimizing a cost function, which is composed of fidelity and prior terms, balanced by a regularization parameter. While a vast amount of research has been focused on different prior models, the fidelity term is almost always chosen to be the least squares (LS) objective, that encourages fitting the linearly transformed optimization variable to the observations. In this work, we examine a different fidelity term, which has been implicitly used by the recently proposed iterative denoising and backward projections (IDBP) framework. This term encourages agreement between the projection of the optimization variable onto the row space of the linear operator and the pseudo-inverse of the linear operator ("back-projection") applied on the observations. We analytically examine the difference between the two fidelity terms for Tikhonov regularization and identify cases where the new term has an advantage over the standard LS one. Moreover, we demonstrate empirically that the behavior of the two induced cost functions for sophisticated convex and non-convex priors, such as total-variation, BM3D, and deep generative models, correlates with the obtained theoretical analysis.