 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscretizing Numerical Attributes: An Analysis of Human Perceptions
Nov 06, 2023



Machine learning (ML) has employed various discretization methods to partition numerical attributes into intervals. However, an effective discretization technique remains elusive in many ML applications, such as association rule mining. Moreover, the existing discretization techniques do not reflect best the impact of the independent numerical factor on the dependent numerical target factor. This research aims to establish a benchmark approach for numerical attribute partitioning. We conduct an extensive analysis of human perceptions of partitioning a numerical attribute and compare these perceptions with the results obtained from our two proposed measures. We also examine the perceptions of experts in data science, statistics, and engineering by employing numerical data visualization techniques. The analysis of collected responses reveals that $68.7\%$ of human responses approximately closely align with the values generated by our proposed measures. Based on these findings, our proposed measures may be used as one of the methods for discretizing the numerical attributes.
Ranking LLM-Generated Loop Invariants for Program Verification
Oct 18, 2023Synthesizing inductive loop invariants is fundamental to automating program verification. In this work, we observe that Large Language Models (such as gpt-3.5 or gpt-4) are capable of synthesizing loop invariants for a class of programs in a 0-shot setting, yet require several samples to generate the correct invariants. This can lead to a large number of calls to a program verifier to establish an invariant. To address this issue, we propose a {\it re-ranking} approach for the generated results of LLMs. We have designed a ranker that can distinguish between correct inductive invariants and incorrect attempts based on the problem definition. The ranker is optimized as a contrastive ranker. Experimental results demonstrate that this re-ranking mechanism significantly improves the ranking of correct invariants among the generated candidates, leading to a notable reduction in the number of calls to a verifier.
Numerical Association Rule Mining: A Systematic Literature Review
Jul 02, 2023



Numerical association rule mining is a widely used variant of the association rule mining technique, and it has been extensively used in discovering patterns and relationships in numerical data. Initially, researchers and scientists integrated numerical attributes in association rule mining using various discretization approaches; however, over time, a plethora of alternative methods have emerged in this field. Unfortunately, the increase of alternative methods has resulted into a significant knowledge gap in understanding diverse techniques employed in numerical association rule mining -- this paper attempts to bridge this knowledge gap by conducting a comprehensive systematic literature review. We provide an in-depth study of diverse methods, algorithms, metrics, and datasets derived from 1,140 scholarly articles published from the inception of numerical association rule mining in the year 1996 to 2022. In compliance with the inclusion, exclusion, and quality evaluation criteria, 68 papers were chosen to be extensively evaluated. To the best of our knowledge, this systematic literature review is the first of its kind to provide an exhaustive analysis of the current literature and previous surveys on numerical association rule mining. The paper discusses important research issues, the current status, and future possibilities of numerical association rule mining. On the basis of this systematic review, the article also presents a novel discretization measure that contributes by providing a partitioning of numerical data that meets well human perception of partitions.
Training with Mixed-Precision Floating-Point Assignments
Jan 31, 2023When training deep neural networks, keeping all tensors in high precision (e.g., 32-bit or even 16-bit floats) is often wasteful. However, keeping all tensors in low precision (e.g., 8-bit floats) can lead to unacceptable accuracy loss. Hence, it is important to use a precision assignment -- a mapping from all tensors (arising in training) to precision levels (high or low) -- that keeps most of the tensors in low precision and leads to sufficiently accurate models. We provide a technique that explores this memory-accuracy tradeoff by generating precision assignments that (i) use less memory and (ii) lead to more accurate models at the same time, compared to the precision assignments considered by prior work in low-precision floating-point training. Our method typically provides > 2x memory reduction over a baseline precision assignment while preserving training accuracy, and gives further reductions by trading off accuracy. Compared to other baselines which sometimes cause training to diverge, our method provides similar or better memory reduction while avoiding divergence.
Machine learning techniques for the Schizophrenia diagnosis: A comprehensive review and future research directions
Jan 16, 2023Schizophrenia (SCZ) is a brain disorder where different people experience different symptoms, such as hallucination, delusion, flat-talk, disorganized thinking, etc. In the long term, this can cause severe effects and diminish life expectancy by more than ten years. Therefore, early and accurate diagnosis of SCZ is prevalent, and modalities like structural magnetic resonance imaging (sMRI), functional MRI (fMRI), diffusion tensor imaging (DTI), and electroencephalogram (EEG) assist in witnessing the brain abnormalities of the patients. Moreover, for accurate diagnosis of SCZ, researchers have used machine learning (ML) algorithms for the past decade to distinguish the brain patterns of healthy and SCZ brains using MRI and fMRI images. This paper seeks to acquaint SCZ researchers with ML and to discuss its recent applications to the field of SCZ study. This paper comprehensively reviews state-of-the-art techniques such as ML classifiers, artificial neural network (ANN), deep learning (DL) models, methodological fundamentals, and applications with previous studies. The motivation of this paper is to benefit from finding the research gaps that may lead to the development of a new model for accurate SCZ diagnosis. The paper concludes with the research finding, followed by the future scope that directly contributes to new research directions.
Audio-Visual Activity Guided Cross-Modal Identity Association for Active Speaker Detection
Dec 01, 2022



Active speaker detection in videos addresses associating a source face, visible in the video frames, with the underlying speech in the audio modality. The two primary sources of information to derive such a speech-face relationship are i) visual activity and its interaction with the speech signal and ii) co-occurrences of speakers' identities across modalities in the form of face and speech. The two approaches have their limitations: the audio-visual activity models get confused with other frequently occurring vocal activities, such as laughing and chewing, while the speakers' identity-based methods are limited to videos having enough disambiguating information to establish a speech-face association. Since the two approaches are independent, we investigate their complementary nature in this work. We propose a novel unsupervised framework to guide the speakers' cross-modal identity association with the audio-visual activity for active speaker detection. Through experiments on entertainment media videos from two benchmark datasets, the AVA active speaker (movies) and Visual Person Clustering Dataset (TV shows), we show that a simple late fusion of the two approaches enhances the active speaker detection performance.
MinUn: Accurate ML Inference on Microcontrollers
Oct 29, 2022



Running machine learning inference on tiny devices, known as TinyML, is an emerging research area. This task requires generating inference code that uses memory frugally, a task that standard ML frameworks are ill-suited for. A deployment framework for TinyML must be a) parametric in the number representation to take advantage of the emerging representations like posits, b) carefully assign high-precision to a few tensors so that most tensors can be kept in low-precision while still maintaining model accuracy, and c) avoid memory fragmentation. We describe MinUn, the first TinyML framework that holistically addresses these issues to generate efficient code for ARM microcontrollers (e.g., Arduino Uno, Due and STM32H747) that outperforms the prior TinyML frameworks.
Machine Learning for Optical Motion Capture-driven Musculoskeletal Modeling from Inertial Motion Capture Data
Sep 28, 2022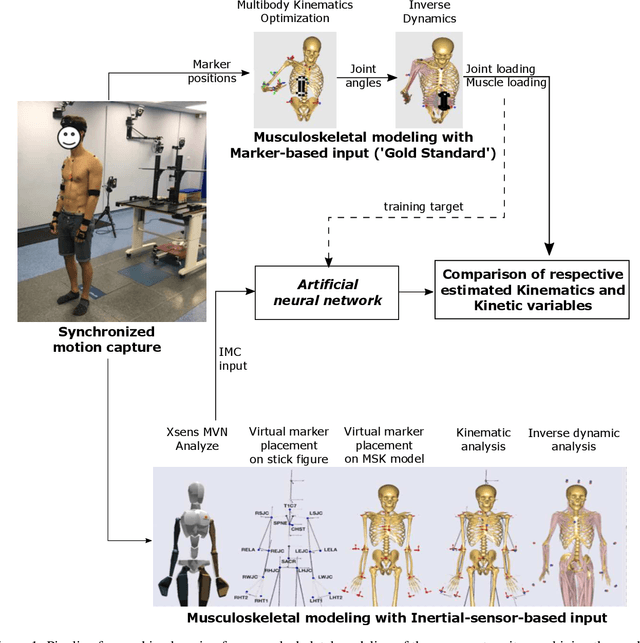
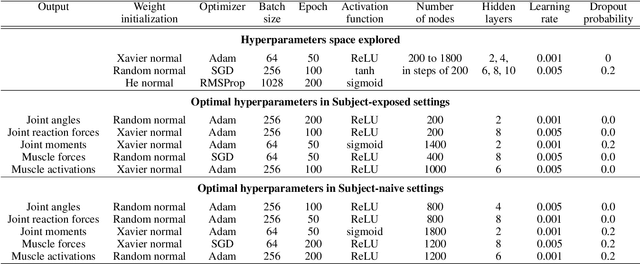
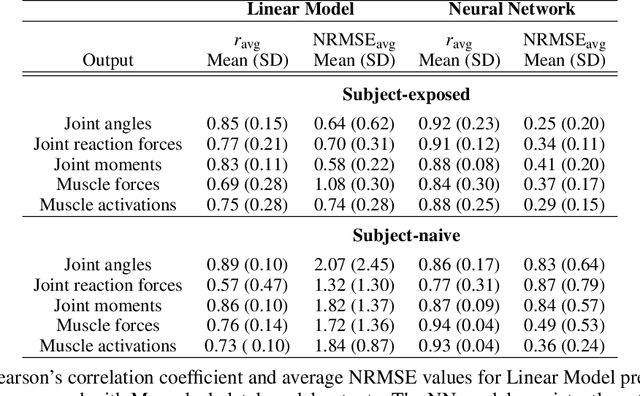
Marker-based Optical Motion Capture (OMC) systems and the associated musculoskeletal (MSK) modeling predictions have offered the ability to gain insights into in vivo joint and muscle loading non-invasively as well as aid clinical decision-making. However, an OMC system is lab-based, expensive, and requires a line of sight. A widely used alternative is the Inertial Motion Capture (IMC) system, which is portable, user-friendly, and relatively low cost, although it is not as accurate as an OMC system. Irrespective of the choice of motion capture technique, one needs to use an MSK model to obtain the kinematic and kinetic outputs, which is a computationally expensive tool increasingly well approximated by machine learning (ML) methods. Here, we present an ML approach to map IMC data to the human upper-extremity MSK outputs computed from OMC input data. Essentially, we attempt to predict high-quality MSK outputs from the relatively easier-to-obtain IMC data. We use OMC and IMC data simultaneously collected for the same subjects to train an ML (feed-forward multi-layer perceptron) model that predicts OMC-based MSK outputs from IMC measurements. We demonstrate that our ML predictions have a high degree of agreement with the desired OMC-based MSK estimates. Thus, this approach will be instrumental in getting the technology from 'lab to field' where OMC-based systems are infeasible.
Unsupervised active speaker detection in media content using cross-modal information
Sep 24, 2022

We present a cross-modal unsupervised framework for active speaker detection in media content such as TV shows and movies. Machine learning advances have enabled impressive performance in identifying individuals from speech and facial images. We leverage speaker identity information from speech and faces, and formulate active speaker detection as a speech-face assignment task such that the active speaker's face and the underlying speech identify the same person (character). We express the speech segments in terms of their associated speaker identity distances, from all other speech segments, to capture a relative identity structure for the video. Then we assign an active speaker's face to each speech segment from the concurrently appearing faces such that the obtained set of active speaker faces displays a similar relative identity structure. Furthermore, we propose a simple and effective approach to address speech segments where speakers are present off-screen. We evaluate the proposed system on three benchmark datasets -- Visual Person Clustering dataset, AVA-active speaker dataset, and Columbia dataset -- consisting of videos from entertainment and broadcast media, and show competitive performance to state-of-the-art fully supervised methods.
Federated Learning with Noisy User Feedback
May 06, 2022
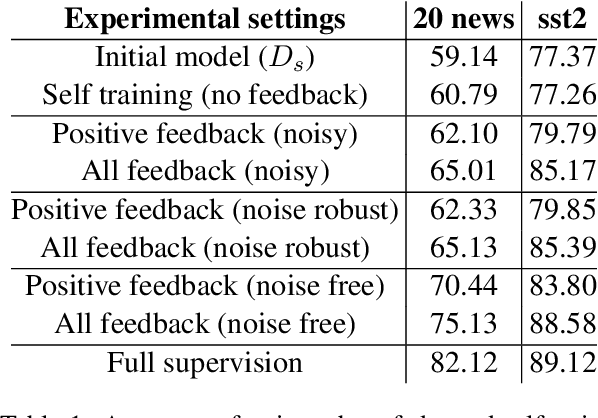
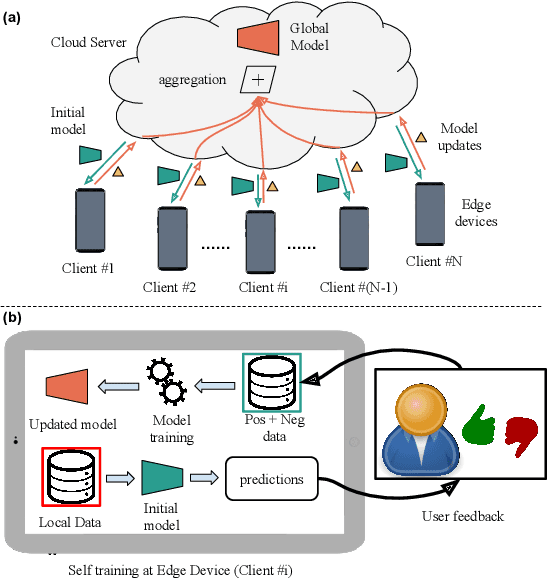
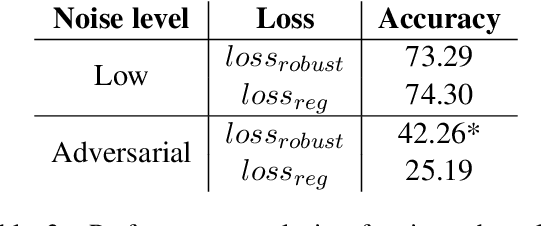
Machine Learning (ML) systems are getting increasingly popular, and drive more and more applications and services in our daily life. This has led to growing concerns over user privacy, since human interaction data typically needs to be transmitted to the cloud in order to train and improve such systems. Federated learning (FL) has recently emerged as a method for training ML models on edge devices using sensitive user data and is seen as a way to mitigate concerns over data privacy. However, since ML models are most commonly trained with label supervision, we need a way to extract labels on edge to make FL viable. In this work, we propose a strategy for training FL models using positive and negative user feedback. We also design a novel framework to study different noise patterns in user feedback, and explore how well standard noise-robust objectives can help mitigate this noise when training models in a federated setting. We evaluate our proposed training setup through detailed experiments on two text classification datasets and analyze the effects of varying levels of user reliability and feedback noise on model performance. We show that our method improves substantially over a self-training baseline, achieving performance closer to models trained with full supervision.