 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassification under Nuisance Parameters and Generalized Label Shift in Likelihood-Free Inference
Feb 08, 2024



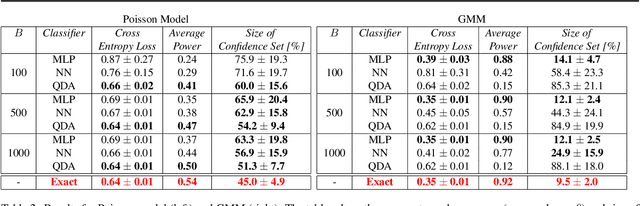
An open scientific challenge is how to classify events with reliable measures of uncertainty, when we have a mechanistic model of the data-generating process but the distribution over both labels and latent nuisance parameters is different between train and target data. We refer to this type of distributional shift as generalized label shift (GLS). Direct classification using observed data $\mathbf{X}$ as covariates leads to biased predictions and invalid uncertainty estimates of labels $Y$. We overcome these biases by proposing a new method for robust uncertainty quantification that casts classification as a hypothesis testing problem under nuisance parameters. The key idea is to estimate the classifier's receiver operating characteristic (ROC) across the entire nuisance parameter space, which allows us to devise cutoffs that are invariant under GLS. Our method effectively endows a pre-trained classifier with domain adaptation capabilities and returns valid prediction sets while maintaining high power. We demonstrate its performance on two challenging scientific problems in biology and astroparticle physics with data from realistic mechanistic models.
Simulation-Based Inference with WALDO: Perfectly Calibrated Confidence Regions Using Any Prediction or Posterior Estimation Algorithm
May 31, 2022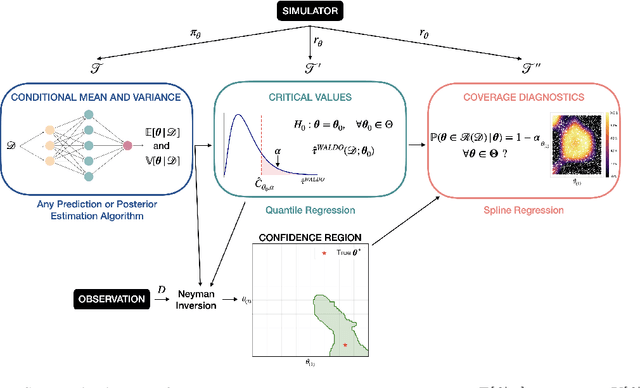
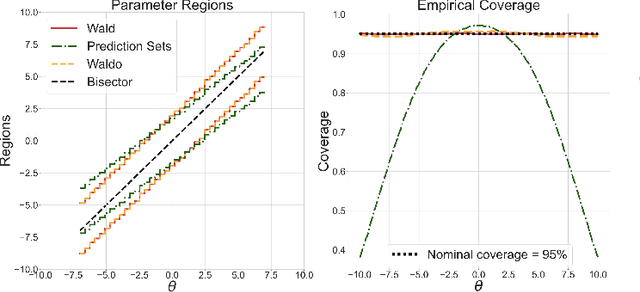
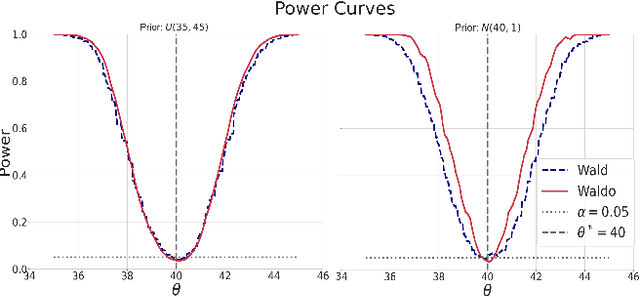
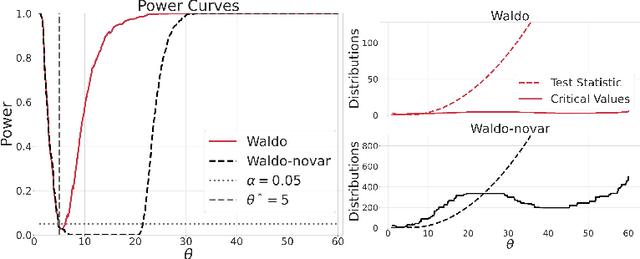
The vast majority of modern machine learning targets prediction problems, with algorithms such as Deep Neural Networks revolutionizing the accuracy of point predictions for high-dimensional complex data. Predictive approaches are now used in many domain sciences to directly estimate internal parameters of interest in theoretical simulator-based models. In parallel, common alternatives focus on estimating the full posterior using modern neural density estimators such as normalizing flows. However, an open problem in simulation-based inference (SBI) is how to construct properly calibrated confidence regions for internal parameters with nominal conditional coverage and high power. Many SBI methods are indeed known to produce overly confident posterior approximations, yielding misleading uncertainty estimates. Similarly, existing approaches for uncertainty quantification in deep learning provide no guarantees on conditional coverage. In this work, we present WALDO, a novel method for constructing correctly calibrated confidence regions in SBI. WALDO reframes the well-known Wald test and uses Neyman inversion to convert point predictions and posteriors from any prediction or posterior estimation algorithm to confidence sets with correct conditional coverage, even for finite sample sizes. As a concrete example, we demonstrate how a recently proposed deep learning prediction approach for particle energies in high-energy physics can be recalibrated using WALDO to produce confidence intervals with correct coverage and high power.
Calibrated Predictive Distributions via Diagnostics for Conditional Coverage
May 29, 2022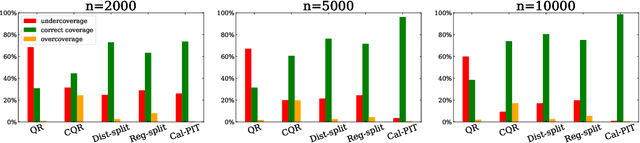

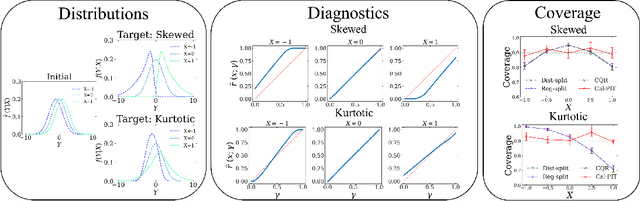
Uncertainty quantification is crucial for assessing the predictive ability of AI algorithms. A large body of work (including normalizing flows and Bayesian neural networks) has been devoted to describing the entire predictive distribution (PD) of a target variable Y given input features $\mathbf{X}$. However, off-the-shelf PDs are usually far from being conditionally calibrated; i.e., the probability of occurrence of an event given input $\mathbf{X}$ can be significantly different from the predicted probability. Most current research on predictive inference (such as conformal prediction) concerns constructing prediction sets, that do not only provide correct uncertainties on average over the entire population (that is, averaging over $\mathbf{X}$), but that are also approximately conditionally calibrated with accurate uncertainties for individual instances. It is often believed that the problem of obtaining and assessing entire conditionally calibrated PDs is too challenging to approach. In this work, we show that recalibration as well as validation are indeed attainable goals in practice. Our proposed method relies on the idea of regressing probability integral transform (PIT) scores against $\mathbf{X}$. This regression gives full diagnostics of conditional coverage across the entire feature space and can be used to recalibrate misspecified PDs. We benchmark our corrected prediction bands against oracle bands and state-of-the-art predictive inference algorithms for synthetic data, including settings with distributional shift and dependent high-dimensional sequence data. Finally, we demonstrate an application to the physical sciences in which we assess and produce calibrated PDs for measurements of galaxy distances using imaging data (i.e., photometric redshifts).
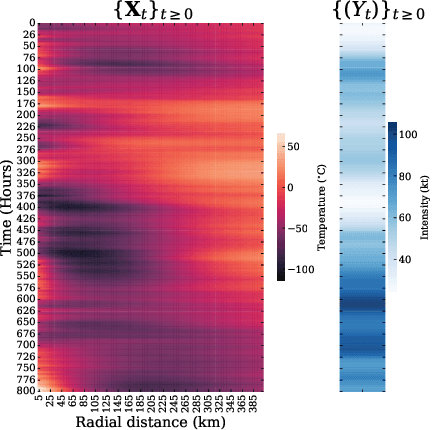
Detecting Distributional Differences in Labeled Sequence Data with Application to Tropical Cyclone Satellite Imagery
Feb 15, 2022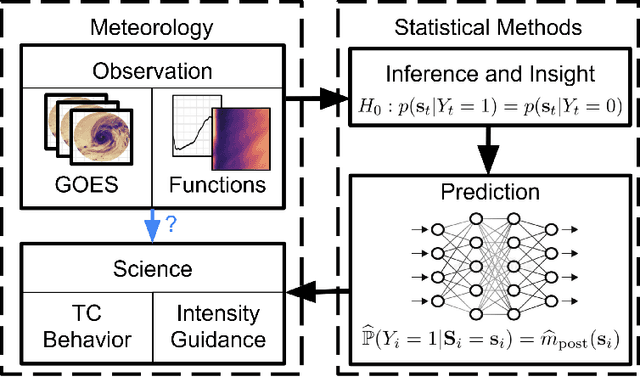
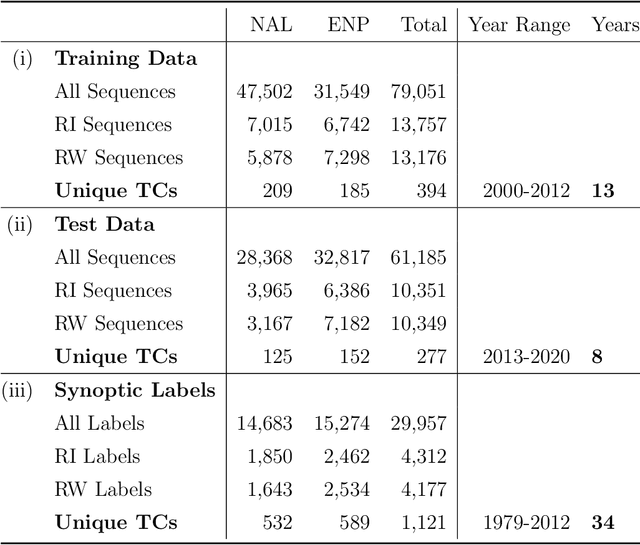
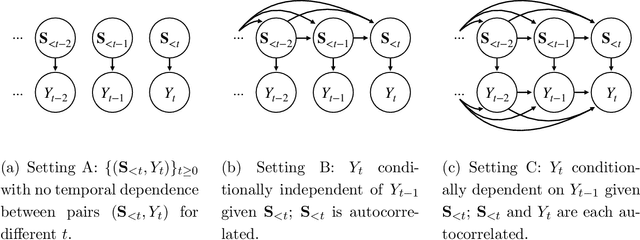
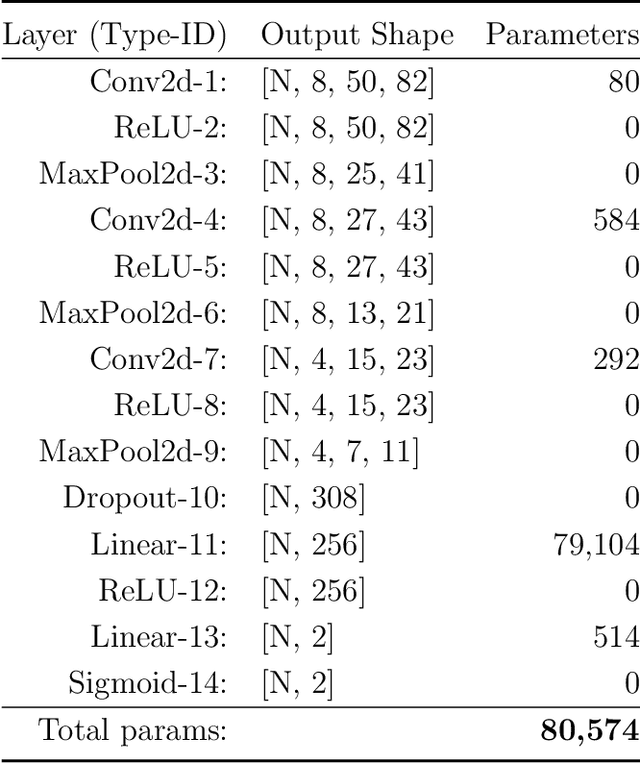
Our goal is to quantify whether, and if so how, spatio-temporal patterns in tropical cyclone (TC) satellite imagery signal an upcoming rapid intensity change event. To address this question, we propose a new nonparametric test of association between a time series of images and a series of binary event labels. We ask whether there is a difference in distribution between (dependent but identically distributed) 24-h sequences of images preceding an event versus a non-event. By rewriting the statistical test as a regression problem, we leverage neural networks to infer modes of structural evolution of TC convection that are representative of the lead-up to rapid intensity change events. Dependencies between nearby sequences are handled by a bootstrap procedure that estimates the marginal distribution of the label series. We prove that type I error control is guaranteed as long as the distribution of the label series is well-estimated, which is made easier by the extensive historical data for binary TC event labels. We show empirical evidence that our proposed method identifies archetypes of infrared imagery associated with elevated rapid intensification risk, typically marked by deep or deepening core convection over time. Such results provide a foundation for improved forecasts of rapid intensification.
Identifying Distributional Differences in Convective Evolution Prior to Rapid Intensification in Tropical Cyclones
Sep 24, 2021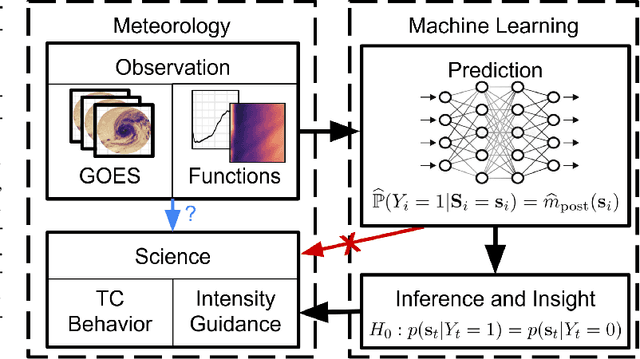
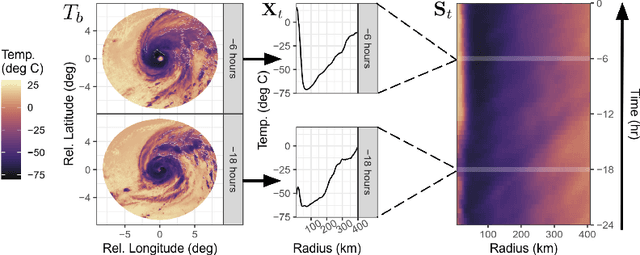
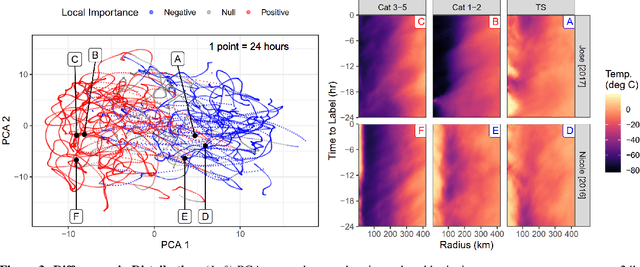
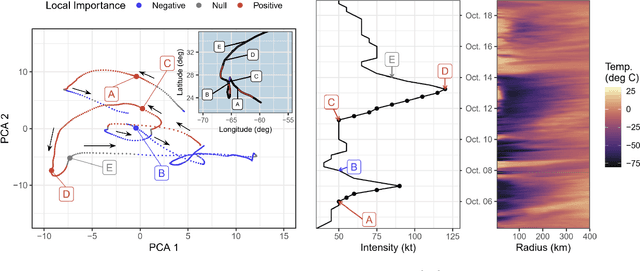
Tropical cyclone (TC) intensity forecasts are issued by human forecasters who evaluate spatio-temporal observations (e.g., satellite imagery) and model output (e.g., numerical weather prediction, statistical models) to produce forecasts every 6 hours. Within these time constraints, it can be challenging to draw insight from such data. While high-capacity machine learning methods are well suited for prediction problems with complex sequence data, extracting interpretable scientific information with such methods is difficult. Here we leverage powerful AI prediction algorithms and classical statistical inference to identify patterns in the evolution of TC convective structure leading up to the rapid intensification of a storm, hence providing forecasters and scientists with key insight into TC behavior.
Likelihood-Free Frequentist Inference: Bridging Classical Statistics and Machine Learning in Simulation and Uncertainty Quantification
Jul 19, 2021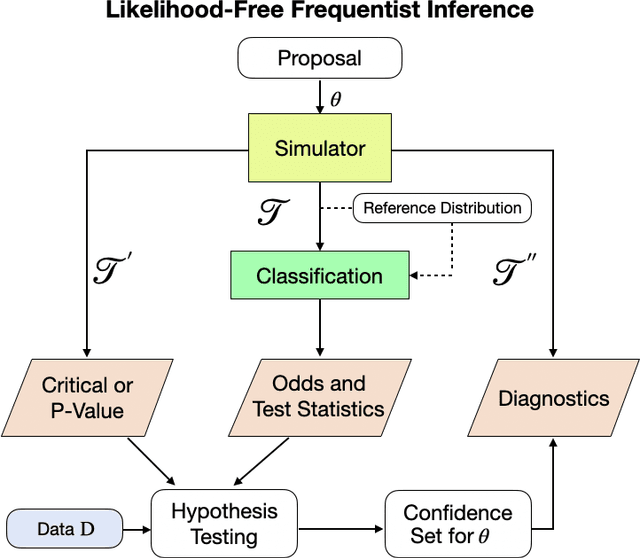
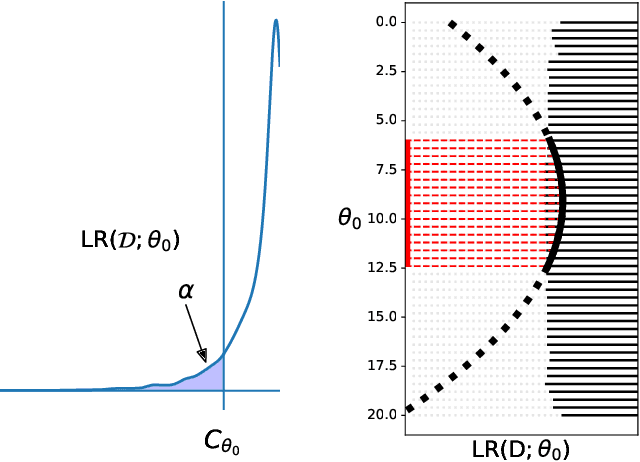
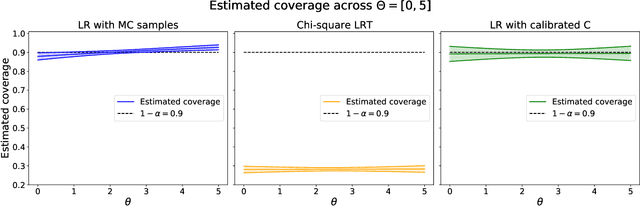
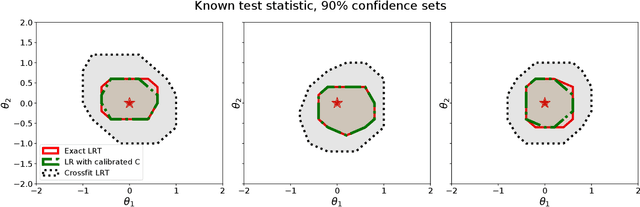
Many areas of science make extensive use of computer simulators that implicitly encode likelihood functions of complex systems. Classical statistical methods are poorly suited for these so-called likelihood-free inference (LFI) settings, outside the asymptotic and low-dimensional regimes. Although new machine learning methods, such as normalizing flows, have revolutionized the sample efficiency and capacity of LFI methods, it remains an open question whether they produce reliable measures of uncertainty. This paper presents a statistical framework for LFI that unifies classical statistics with modern machine learning to: (1) efficiently construct frequentist confidence sets and hypothesis tests with finite-sample guarantees of nominal coverage (type I error control) and power; (2) provide practical diagnostics for assessing empirical coverage over the entire parameter space. We refer to our framework as likelihood-free frequentist inference (LF2I). Any method that estimates a test statistic, like the likelihood ratio, can be plugged into our framework to create valid confidence sets and compute diagnostics, without costly Monte Carlo samples at fixed parameter settings. In this work, we specifically study the power of two test statistics (ACORE and BFF), which, respectively, maximize versus integrate an odds function over the parameter space. Our study offers multifaceted perspectives on the challenges in LF2I.
Structural Forecasting for Tropical Cyclone Intensity Prediction: Providing Insight with Deep Learning
Oct 15, 2020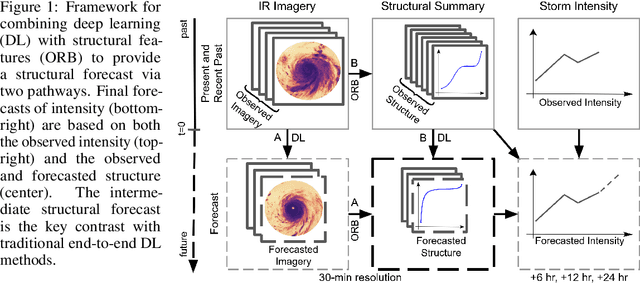
Tropical cyclone (TC) intensity forecasts are ultimately issued by human forecasters. The human in-the-loop pipeline requires that any forecasting guidance must be easily digestible by TC experts if it is to be adopted at operational centers like the National Hurricane Center. Our proposed framework leverages deep learning to provide forecasters with something neither end-to-end prediction models nor traditional intensity guidance does: a powerful tool for monitoring high-dimensional time series of key physically relevant predictors and the means to understand how the predictors relate to one another and to short-term intensity changes.
Wildfire Smoke and Air Quality: How Machine Learning Can Guide Forest Management
Oct 09, 2020
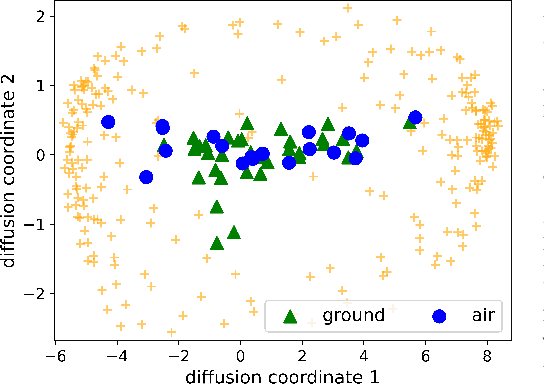
Prescribed burns are currently the most effective method of reducing the risk of widespread wildfires, but a largely missing component in forest management is knowing which fuels one can safely burn to minimize exposure to toxic smoke. Here we show how machine learning, such as spectral clustering and manifold learning, can provide interpretable representations and powerful tools for differentiating between smoke types, hence providing forest managers with vital information on effective strategies to reduce climate-induced wildfires while minimizing production of harmful smoke.
HECT: High-Dimensional Ensemble Consistency Testing for Climate Models
Oct 08, 2020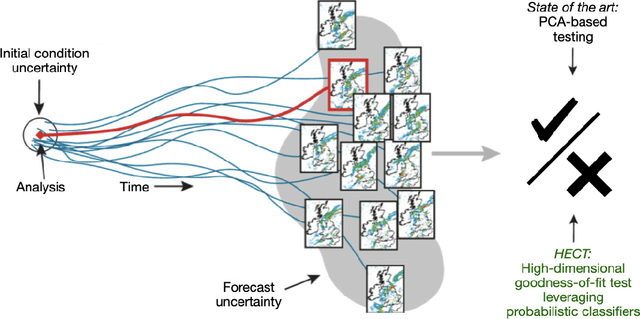
Climate models play a crucial role in understanding the effect of environmental and man-made changes on climate to help mitigate climate risks and inform governmental decisions. Large global climate models such as the Community Earth System Model (CESM), developed by the National Center for Atmospheric Research, are very complex with millions of lines of code describing interactions of the atmosphere, land, oceans, and ice, among other components. As development of the CESM is constantly ongoing, simulation outputs need to be continuously controlled for quality. To be able to distinguish a "climate-changing" modification of the code base from a true climate-changing physical process or intervention, there needs to be a principled way of assessing statistical reproducibility that can handle both spatial and temporal high-dimensional simulation outputs. Our proposed work uses probabilistic classifiers like tree-based algorithms and deep neural networks to perform a statistically rigorous goodness-of-fit test of high-dimensional spatio-temporal data.
Confidence Sets and Hypothesis Testing in a Likelihood-Free Inference Setting
Feb 24, 2020

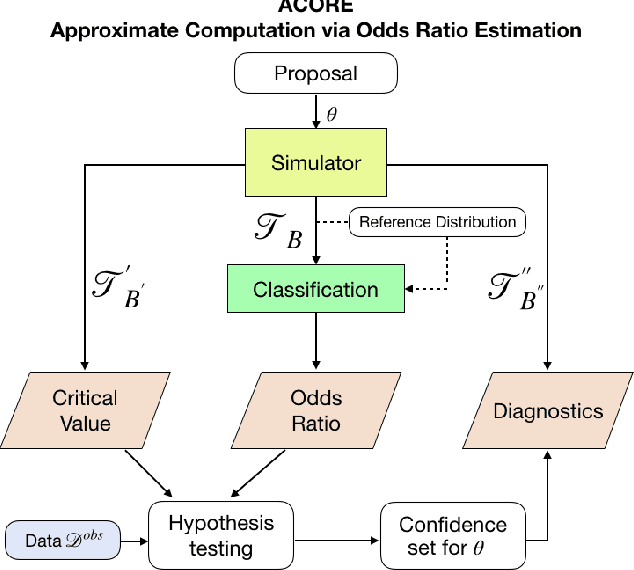
Parameter estimation, statistical tests and confidence sets are the cornerstones of classical statistics that allow scientists to make inferences about the underlying process that generated the observed data. A key question is whether one can still construct hypothesis tests and confidence sets with proper coverage and high power in a so-called likelihood-free inference (LFI) setting; that is, a setting where the likelihood is not explicitly known but one can forward-simulate observable data according to a stochastic model. In this paper, we present $\texttt{ACORE}$ (Approximate Computation via Odds Ratio Estimation), a frequentist approach to LFI that first formulates the classical likelihood ratio test (LRT) as a parametrized classification problem, and then uses the equivalence of tests and confidence sets to build confidence regions for parameters of interest. We also present a goodness-of-fit procedure for checking whether the constructed tests and confidence regions are valid. $\texttt{ACORE}$ is based on the key observation that the LRT statistic, the rejection probability of the test, and the coverage of the confidence set are conditional distribution functions which often vary smoothly as a function of the parameters of interest. Hence, instead of relying solely on samples simulated at fixed parameter settings (as is the convention in standard Monte Carlo solutions), one can leverage machine learning tools and data simulated in the neighborhood of a parameter to improve estimates of quantities of interest. We demonstrate the efficacy of $\texttt{ACORE}$ with both theoretical and empirical results. Our implementation is available on Github.