 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA quantum-classical reinforcement learning model to play Atari games
Dec 11, 2024Recent advances in reinforcement learning have demonstrated the potential of quantum learning models based on parametrized quantum circuits as an alternative to deep learning models. On the one hand, these findings have shown the ultimate exponential speed-ups in learning that full-blown quantum models can offer in certain -- artificially constructed -- environments. On the other hand, they have demonstrated the ability of experimentally accessible PQCs to solve OpenAI Gym benchmarking tasks. However, it remains an open question whether these near-term QRL techniques can be successfully applied to more complex problems exhibiting high-dimensional observation spaces. In this work, we bridge this gap and present a hybrid model combining a PQC with classical feature encoding and post-processing layers that is capable of tackling Atari games. A classical model, subjected to architectural restrictions similar to those present in the hybrid model is constructed to serve as a reference. Our numerical investigation demonstrates that the proposed hybrid model is capable of solving the Pong environment and achieving scores comparable to the classical reference in Breakout. Furthermore, our findings shed light on important hyperparameter settings and design choices that impact the interplay of the quantum and classical components. This work contributes to the understanding of near-term quantum learning models and makes an important step towards their deployment in real-world RL scenarios.
Neuromorphic IoT Architecture for Efficient Water Management: A Smart Village Case Study
Oct 25, 2024The exponential growth of IoT networks necessitates a paradigm shift towards architectures that offer high flexibility and learning capabilities while maintaining low energy consumption, minimal communication overhead, and low latency. Traditional IoT systems, particularly when integrated with machine learning approaches, often suffer from high communication overhead and significant energy consumption. This work addresses these challenges by proposing a neuromorphic architecture inspired by biological systems. To illustrate the practical application of our proposed architecture, we present a case study focusing on water management in the Carinthian community of Neuhaus. Preliminary results regarding water consumption prediction and anomaly detection in this community are presented. We also introduce a novel neuromorphic IoT architecture that integrates biological principles into the design of IoT systems. This architecture is specifically tailored for edge computing scenarios, where low power and high efficiency are crucial. Our approach leverages the inherent advantages of neuromorphic computing, such as asynchronous processing and event-driven communication, to create an IoT framework that is both energy-efficient and responsive. This case study demonstrates how the neuromorphic IoT architecture can be deployed in a real-world scenario, highlighting its benefits in terms of energy savings, reduced communication overhead, and improved system responsiveness.
Scalable Offline Reinforcement Learning for Mean Field Games
Oct 23, 2024



Reinforcement learning algorithms for mean-field games offer a scalable framework for optimizing policies in large populations of interacting agents. Existing methods often depend on online interactions or access to system dynamics, limiting their practicality in real-world scenarios where such interactions are infeasible or difficult to model. In this paper, we present Offline Munchausen Mirror Descent (Off-MMD), a novel mean-field RL algorithm that approximates equilibrium policies in mean-field games using purely offline data. By leveraging iterative mirror descent and importance sampling techniques, Off-MMD estimates the mean-field distribution from static datasets without relying on simulation or environment dynamics. Additionally, we incorporate techniques from offline reinforcement learning to address common issues like Q-value overestimation, ensuring robust policy learning even with limited data coverage. Our algorithm scales to complex environments and demonstrates strong performance on benchmark tasks like crowd exploration or navigation, highlighting its applicability to real-world multi-agent systems where online experimentation is infeasible. We empirically demonstrate the robustness of Off-MMD to low-quality datasets and conduct experiments to investigate its sensitivity to hyperparameter choices.
MMDVS-LF: A Multi-Modal Dynamic-Vision-Sensor Line Following Dataset
Sep 26, 2024



Dynamic Vision Sensors (DVS), offer a unique advantage in control applications, due to their high temporal resolution, and asynchronous event-based data. Still, their adoption in machine learning algorithms remains limited. To address this gap, and promote the development of models that leverage the specific characteristics of DVS data, we introduce the Multi-Modal Dynamic-Vision-Sensor Line Following dataset (MMDVS-LF). This comprehensive dataset, is the first to integrate multiple sensor modalities, including DVS recordings, RGB video, odometry, and Inertial Measurement Unit (IMU) data, from a small-scale standardized vehicle. Additionally, the dataset includes eye-tracking and demographic data of drivers performing a Line Following task on a track. With its diverse range of data, MMDVS-LF opens new opportunities for developing deep learning algorithms, and conducting data science projects across various domains, supporting innovation in autonomous systems and control applications.
Segmentation of Prostate Tumour Volumes from PET Images is a Different Ball Game
Jul 15, 2024



Accurate segmentation of prostate tumours from PET images presents a formidable challenge in medical image analysis. Despite considerable work and improvement in delineating organs from CT and MR modalities, the existing standards do not transfer well and produce quality results in PET related tasks. Particularly, contemporary methods fail to accurately consider the intensity-based scaling applied by the physicians during manual annotation of tumour contours. In this paper, we observe that the prostate-localised uptake threshold ranges are beneficial for suppressing outliers. Therefore, we utilize the intensity threshold values, to implement a new custom-feature-clipping normalisation technique. We evaluate multiple, established U-Net variants under different normalisation schemes, using the nnU-Net framework. All models were trained and tested on multiple datasets, obtained with two radioactive tracers: [68-Ga]Ga-PSMA-11 and [18-F]PSMA-1007. Our results show that the U-Net models achieve much better performance when the PET scans are preprocessed with our novel clipping technique.
Automated Immunophenotyping Assessment for Diagnosing Childhood Acute Leukemia using Set-Transformers
Jun 26, 2024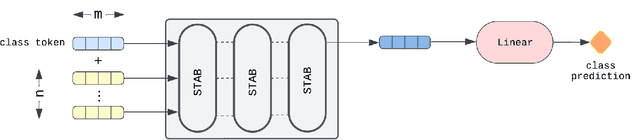
Acute Leukemia is the most common hematologic malignancy in children and adolescents. A key methodology in the diagnostic evaluation of this malignancy is immunophenotyping based on Multiparameter Flow Cytometry (FCM). However, this approach is manual, and thus time-consuming and subjective. To alleviate this situation, we propose in this paper the FCM-Former, a machine learning, self-attention based FCM-diagnostic tool, automating the immunophenotyping assessment in Childhood Acute Leukemia. The FCM-Former is trained in a supervised manner, by directly using flow cytometric data. Our FCM-Former achieves an accuracy of 96.5% assigning lineage to each sample among 960 cases of either acute B-cell, T-cell lymphoblastic, and acute myeloid leukemia (B-ALL, T-ALL, AML). To the best of our knowledge, the FCM-Former is the first work that automates the immunophenotyping assessment with FCM data in diagnosing pediatric Acute Leukemia.
Scenario-Based Curriculum Generation for Multi-Agent Autonomous Driving
Mar 26, 2024The automated generation of diverse and complex training scenarios has been an important ingredient in many complex learning tasks. Especially in real-world application domains, such as autonomous driving, auto-curriculum generation is considered vital for obtaining robust and general policies. However, crafting traffic scenarios with multiple, heterogeneous agents is typically considered as a tedious and time-consuming task, especially in more complex simulation environments. In our work, we introduce MATS-Gym, a Multi-Agent Traffic Scenario framework to train agents in CARLA, a high-fidelity driving simulator. MATS-Gym is a multi-agent training framework for autonomous driving that uses partial scenario specifications to generate traffic scenarios with variable numbers of agents. This paper unifies various existing approaches to traffic scenario description into a single training framework and demonstrates how it can be integrated with techniques from unsupervised environment design to automate the generation of adaptive auto-curricula. The code is available at https://github.com/AutonomousDrivingExaminer/mats-gym.
Unveiling the Unseen: Identifiable Clusters in Trained Depthwise Convolutional Kernels
Jan 25, 2024



Recent advances in depthwise-separable convolutional neural networks (DS-CNNs) have led to novel architectures, that surpass the performance of classical CNNs, by a considerable scalability and accuracy margin. This paper reveals another striking property of DS-CNN architectures: discernible and explainable patterns emerge in their trained depthwise convolutional kernels in all layers. Through an extensive analysis of millions of trained filters, with different sizes and from various models, we employed unsupervised clustering with autoencoders, to categorize these filters. Astonishingly, the patterns converged into a few main clusters, each resembling the difference of Gaussian (DoG) functions, and their first and second-order derivatives. Notably, we were able to classify over 95\% and 90\% of the filters from state-of-the-art ConvNextV2 and ConvNeXt models, respectively. This finding is not merely a technological curiosity; it echoes the foundational models neuroscientists have long proposed for the vision systems of mammals. Our results thus deepen our understanding of the emergent properties of trained DS-CNNs and provide a bridge between artificial and biological visual processing systems. More broadly, they pave the way for more interpretable and biologically-inspired neural network designs in the future.
Neural Echos: Depthwise Convolutional Filters Replicate Biological Receptive Fields
Jan 18, 2024



In this study, we present evidence suggesting that depthwise convolutional kernels are effectively replicating the structural intricacies of the biological receptive fields observed in the mammalian retina. We provide analytics of trained kernels from various state-of-the-art models substantiating this evidence. Inspired by this intriguing discovery, we propose an initialization scheme that draws inspiration from the biological receptive fields. Experimental analysis of the ImageNet dataset with multiple CNN architectures featuring depthwise convolutions reveals a marked enhancement in the accuracy of the learned model when initialized with biologically derived weights. This underlies the potential for biologically inspired computational models to further our understanding of vision processing systems and to improve the efficacy of convolutional networks.
Real-Time Recurrent Reinforcement Learning
Nov 08, 2023



Recent advances in reinforcement learning, for partially-observable Markov decision processes (POMDPs), rely on the biologically implausible backpropagation through time algorithm (BPTT) to perform gradient-descent optimisation. In this paper we propose a novel reinforcement learning algorithm that makes use of random feedback local online learning (RFLO), a biologically plausible approximation of realtime recurrent learning (RTRL) to compute the gradients of the parameters of a recurrent neural network in an online manner. By combining it with TD($\lambda$), a variant of temporaldifference reinforcement learning with eligibility traces, we create a biologically plausible, recurrent actor-critic algorithm, capable of solving discrete and continuous control tasks in POMDPs. We compare BPTT, RTRL and RFLO as well as different network architectures, and find that RFLO can perform just as well as RTRL while exceeding even BPTT in terms of complexity. The proposed method, called real-time recurrent reinforcement learning (RTRRL), serves as a model of learning in biological neural networks mimicking reward pathways in the mammalian brain.