 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHunyuanVideo-Foley: Multimodal Diffusion with Representation Alignment for High-Fidelity Foley Audio Generation
Aug 23, 2025Recent advances in video generation produce visually realistic content, yet the absence of synchronized audio severely compromises immersion. To address key challenges in video-to-audio generation, including multimodal data scarcity, modality imbalance and limited audio quality in existing methods, we propose HunyuanVideo-Foley, an end-to-end text-video-to-audio framework that synthesizes high-fidelity audio precisely aligned with visual dynamics and semantic context. Our approach incorporates three core innovations: (1) a scalable data pipeline curating 100k-hour multimodal datasets through automated annotation; (2) a representation alignment strategy using self-supervised audio features to guide latent diffusion training, efficiently improving audio quality and generation stability; (3) a novel multimodal diffusion transformer resolving modal competition, containing dual-stream audio-video fusion through joint attention, and textual semantic injection via cross-attention. Comprehensive evaluations demonstrate that HunyuanVideo-Foley achieves new state-of-the-art performance across audio fidelity, visual-semantic alignment, temporal alignment and distribution matching. The demo page is available at: https://szczesnys.github.io/hunyuanvideo-foley/.
MPE-TTS: Customized Emotion Zero-Shot Text-To-Speech Using Multi-Modal Prompt
May 24, 2025Most existing Zero-Shot Text-To-Speech(ZS-TTS) systems generate the unseen speech based on single prompt, such as reference speech or text descriptions, which limits their flexibility. We propose a customized emotion ZS-TTS system based on multi-modal prompt. The system disentangles speech into the content, timbre, emotion and prosody, allowing emotion prompts to be provided as text, image or speech. To extract emotion information from different prompts, we propose a multi-modal prompt emotion encoder. Additionally, we introduce an prosody predictor to fit the distribution of prosody and propose an emotion consistency loss to preserve emotion information in the predicted prosody. A diffusion-based acoustic model is employed to generate the target mel-spectrogram. Both objective and subjective experiments demonstrate that our system outperforms existing systems in terms of naturalness and similarity. The samples are available at https://mpetts-demo.github.io/mpetts_demo/.
LLMind: Orchestrating AI and IoT with LLMs for Complex Task Execution
Dec 14, 2023



In this article, we introduce LLMind, an innovative AI framework that utilizes large language models (LLMs) as a central orchestrator. The framework integrates LLMs with domain-specific AI modules, enabling IoT devices to collaborate effectively in executing complex tasks. The LLM performs planning and generates control scripts using a reliable and precise language-code transformation approach based on finite state machines (FSMs). The LLM engages in natural conversations with users, employing role-playing techniques to generate contextually appropriate responses. Additionally, users can interact easily with the AI agent via a user-friendly social media platform. The framework also incorporates semantic analysis and response optimization techniques to enhance speed and effectiveness. Ultimately, this framework is designed not only to innovate IoT device control and enrich user experiences but also to foster an intelligent and integrated IoT device ecosystem that evolves and becomes more sophisticated through continuing user and machine interactions.
DCTTS: Discrete Diffusion Model with Contrastive Learning for Text-to-speech Generation
Sep 13, 2023



In the Text-to-speech(TTS) task, the latent diffusion model has excellent fidelity and generalization, but its expensive resource consumption and slow inference speed have always been a challenging. This paper proposes Discrete Diffusion Model with Contrastive Learning for Text-to-Speech Generation(DCTTS). The following contributions are made by DCTTS: 1) The TTS diffusion model based on discrete space significantly lowers the computational consumption of the diffusion model and improves sampling speed; 2) The contrastive learning method based on discrete space is used to enhance the alignment connection between speech and text and improve sampling quality; and 3) It uses an efficient text encoder to simplify the model's parameters and increase computational efficiency. The experimental results demonstrate that the approach proposed in this paper has outstanding speech synthesis quality and sampling speed while significantly reducing the resource consumption of diffusion model. The synthesized samples are available at https://github.com/lawtherWu/DCTTS.
A Method for Expressing and Displaying the Vehicle Behavior Distribution in Maintenance Work Zones
Apr 25, 2019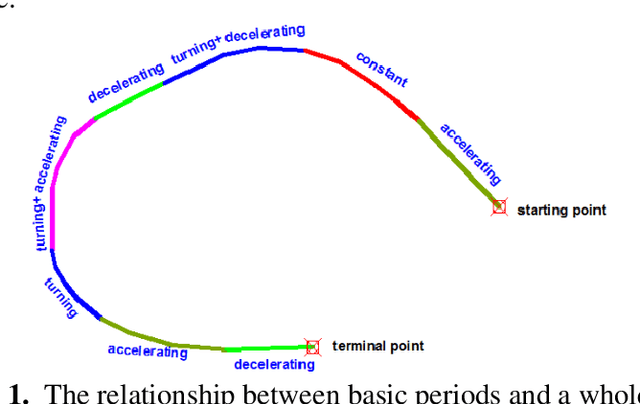

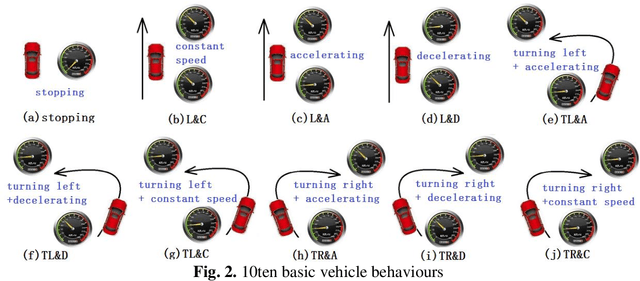

Maintenance work zones on the road network have impacts on the normal travelling of vehicles, which increase the risk of traffic accidents. The traffic characteristic analysis in maintenance work zones is a basis for maintenance work zone related research such as layout design, traffic control and safety assessment. Due to the difficulty in vehicle microscopic behaviour data acquisition, traditional traffic characteristic analysis mainly focuses on macroscopic characteristics. With the development of data acquisition technology, it becomes much easier to obtain a large amount of microscopic behaviour data nowadays, which lays a good foundation for analysing the traffic characteristics from a new point of view. This paper puts forward a method for expressing and displaying the vehicle behaviour distribution in maintenance work zones. Using portable vehicle microscopic behaviour data acquisition devices, lots of data can be obtained. Based on this data, an endpoint detection technology is used to automatically extract the segments in behaviour data with violent fluctuations, which are segments where vehicles take behaviours such as acceleration or turning. Using the support vector machine classification method, the specific types of behaviours of the segments extracted can be identified, and together with a data combination method, a total of ten types of behaviours can be identified. Then the kernel density analysis is used to cluster different types of behaviours of all passing vehicles to show the distribution on maps. By this method, how vehicles travel through maintenance work zones, and how different vehicle behaviours distribute in maintenance work zones can be displayed intuitively on maps, which is a novel traffic characteristic and can shed light to maintenance work zone related researches such as safety assessment and design method.