 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Sampling for Heterogeneous Rank Aggregation from Noisy Pairwise Comparisons
Oct 08, 2021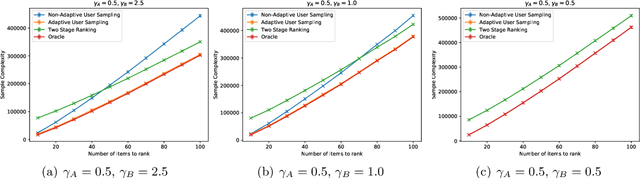
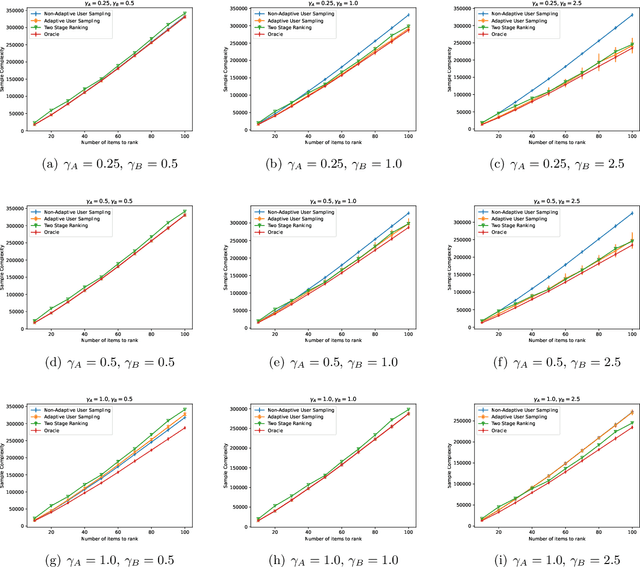
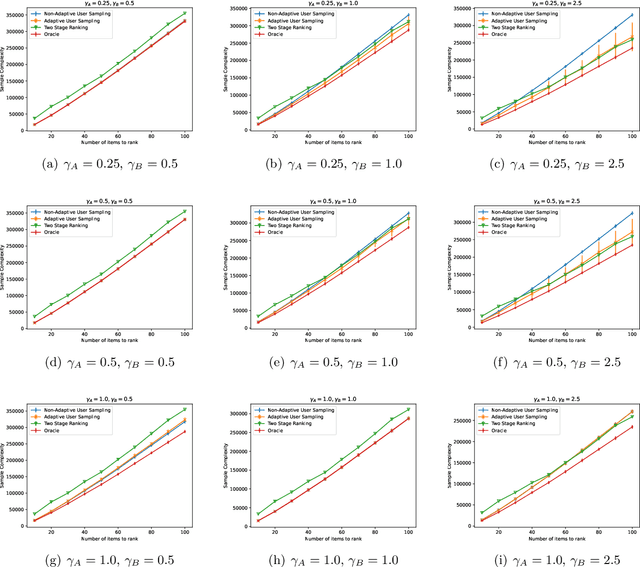
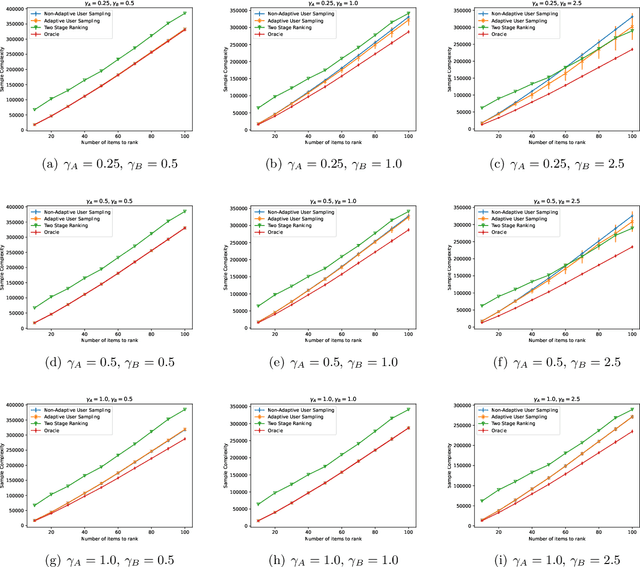
In heterogeneous rank aggregation problems, users often exhibit various accuracy levels when comparing pairs of items. Thus a uniform querying strategy over users may not be optimal. To address this issue, we propose an elimination-based active sampling strategy, which estimates the ranking of items via noisy pairwise comparisons from users and improves the users' average accuracy by maintaining an active set of users. We prove that our algorithm can return the true ranking of items with high probability. We also provide a sample complexity bound for the proposed algorithm which is better than that of non-active strategies in the literature. Experiments are provided to show the empirical advantage of the proposed methods over the state-of-the-art baselines.
Understanding the Generalization of Adam in Learning Neural Networks with Proper Regularization
Aug 25, 2021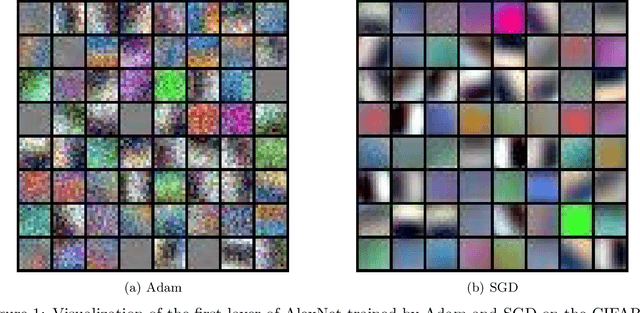
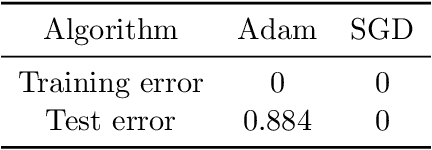
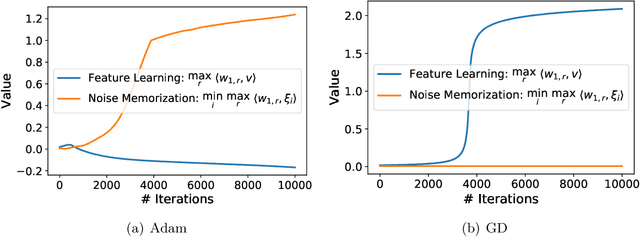
Adaptive gradient methods such as Adam have gained increasing popularity in deep learning optimization. However, it has been observed that compared with (stochastic) gradient descent, Adam can converge to a different solution with a significantly worse test error in many deep learning applications such as image classification, even with a fine-tuned regularization. In this paper, we provide a theoretical explanation for this phenomenon: we show that in the nonconvex setting of learning over-parameterized two-layer convolutional neural networks starting from the same random initialization, for a class of data distributions (inspired from image data), Adam and gradient descent (GD) can converge to different global solutions of the training objective with provably different generalization errors, even with weight decay regularization. In contrast, we show that if the training objective is convex, and the weight decay regularization is employed, any optimization algorithms including Adam and GD will converge to the same solution if the training is successful. This suggests that the inferior generalization performance of Adam is fundamentally tied to the nonconvex landscape of deep learning optimization.
The Benefits of Implicit Regularization from SGD in Least Squares Problems
Aug 10, 2021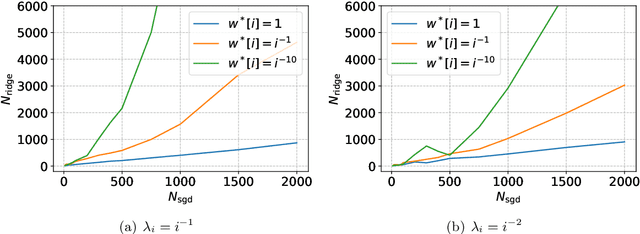
Stochastic gradient descent (SGD) exhibits strong algorithmic regularization effects in practice, which has been hypothesized to play an important role in the generalization of modern machine learning approaches. In this work, we seek to understand these issues in the simpler setting of linear regression (including both underparameterized and overparameterized regimes), where our goal is to make sharp instance-based comparisons of the implicit regularization afforded by (unregularized) average SGD with the explicit regularization of ridge regression. For a broad class of least squares problem instances (that are natural in high-dimensional settings), we show: (1) for every problem instance and for every ridge parameter, (unregularized) SGD, when provided with logarithmically more samples than that provided to the ridge algorithm, generalizes no worse than the ridge solution (provided SGD uses a tuned constant stepsize); (2) conversely, there exist instances (in this wide problem class) where optimally-tuned ridge regression requires quadratically more samples than SGD in order to have the same generalization performance. Taken together, our results show that, up to the logarithmic factors, the generalization performance of SGD is always no worse than that of ridge regression in a wide range of overparameterized problems, and, in fact, could be much better for some problem instances. More generally, our results show how algorithmic regularization has important consequences even in simpler (overparameterized) convex settings.
Proxy Convexity: A Unified Framework for the Analysis of Neural Networks Trained by Gradient Descent
Jul 20, 2021Although the optimization objectives for learning neural networks are highly non-convex, gradient-based methods have been wildly successful at learning neural networks in practice. This juxtaposition has led to a number of recent studies on provable guarantees for neural networks trained by gradient descent. Unfortunately, the techniques in these works are often highly specific to the problem studied in each setting, relying on different assumptions on the distribution, optimization parameters, and network architectures, making it difficult to generalize across different settings. In this work, we propose a unified non-convex optimization framework for the analysis of neural network training. We introduce the notions of proxy convexity and proxy Polyak-Lojasiewicz (PL) inequalities, which are satisfied if the original objective function induces a proxy objective function that is implicitly minimized when using gradient methods. We show that stochastic gradient descent (SGD) on objectives satisfying proxy convexity or the proxy PL inequality leads to efficient guarantees for proxy objective functions. We further show that many existing guarantees for neural networks trained by gradient descent can be unified through proxy convexity and proxy PL inequalities.
Self-training Converts Weak Learners to Strong Learners in Mixture Models
Jul 16, 2021We consider a binary classification problem when the data comes from a mixture of two isotropic distributions satisfying concentration and anti-concentration properties enjoyed by log-concave distributions among others. We show that there exists a universal constant $C_{\mathrm{err}}>0$ such that if a pseudolabeler $\boldsymbol{\beta}_{\mathrm{pl}}$ can achieve classification error at most $C_{\mathrm{err}}$, then for any $\varepsilon>0$, an iterative self-training algorithm initialized at $\boldsymbol{\beta}_0 := \boldsymbol{\beta}_{\mathrm{pl}}$ using pseudolabels $\hat y = \mathrm{sgn}(\langle \boldsymbol{\beta}_t, \mathbf{x}\rangle)$ and using at most $\tilde O(d/\varepsilon^2)$ unlabeled examples suffices to learn the Bayes-optimal classifier up to $\varepsilon$ error, where $d$ is the ambient dimension. That is, self-training converts weak learners to strong learners using only unlabeled examples. We additionally show that by running gradient descent on the logistic loss one can obtain a pseudolabeler $\boldsymbol{\beta}_{\mathrm{pl}}$ with classification error $C_{\mathrm{err}}$ using only $O(d)$ labeled examples (i.e., independent of $\varepsilon$). Together our results imply that mixture models can be learned to within $\varepsilon$ of the Bayes-optimal accuracy using at most $O(d)$ labeled examples and $\tilde O(d/\varepsilon^2)$ unlabeled examples by way of a semi-supervised self-training algorithm.
Pure Exploration in Kernel and Neural Bandits
Jun 22, 2021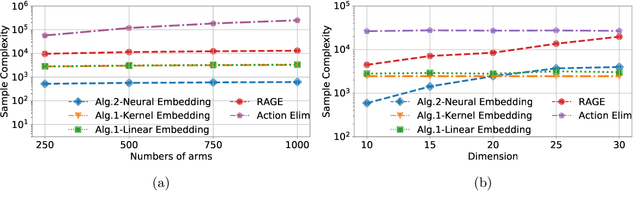

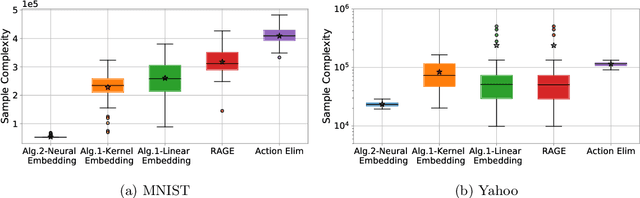
We study pure exploration in bandits, where the dimension of the feature representation can be much larger than the number of arms. To overcome the curse of dimensionality, we propose to adaptively embed the feature representation of each arm into a lower-dimensional space and carefully deal with the induced model misspecifications. Our approach is conceptually very different from existing works that can either only handle low-dimensional linear bandits or passively deal with model misspecifications. We showcase the application of our approach to two pure exploration settings that were previously under-studied: (1) the reward function belongs to a possibly infinite-dimensional Reproducing Kernel Hilbert Space, and (2) the reward function is nonlinear and can be approximated by neural networks. Our main results provide sample complexity guarantees that only depend on the effective dimension of the feature spaces in the kernel or neural representations. Extensive experiments conducted on both synthetic and real-world datasets demonstrate the efficacy of our methods.
Variance-Aware Off-Policy Evaluation with Linear Function Approximation
Jun 22, 2021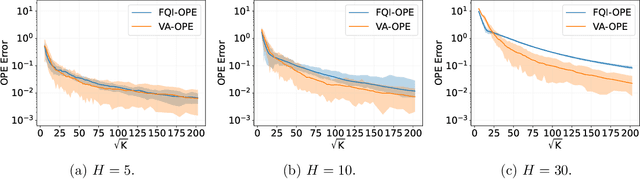
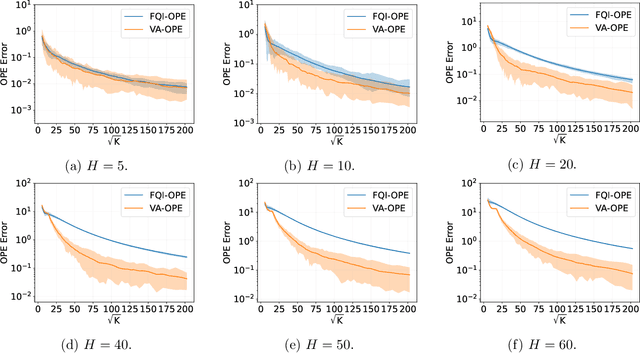
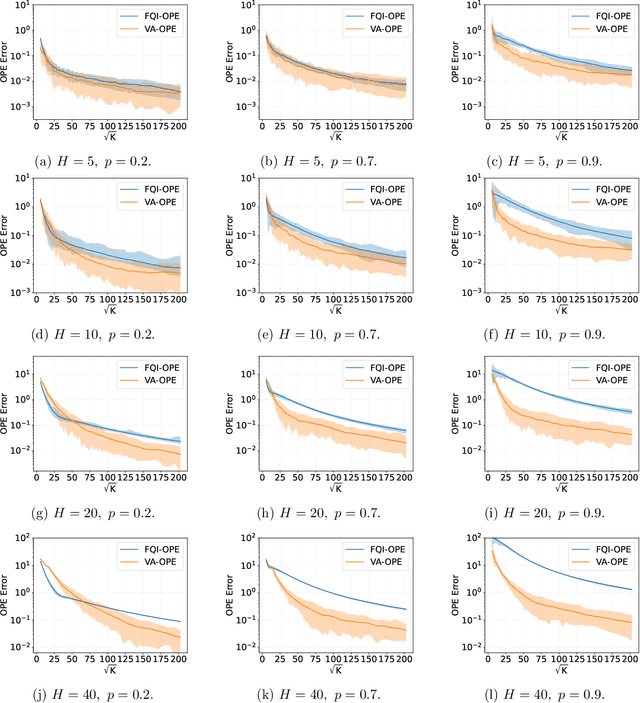
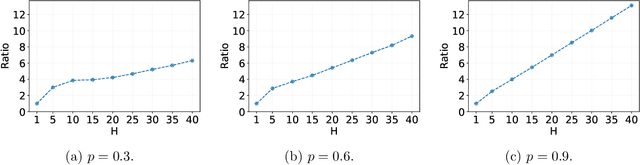
We study the off-policy evaluation (OPE) problem in reinforcement learning with linear function approximation, which aims to estimate the value function of a target policy based on the offline data collected by a behavior policy. We propose to incorporate the variance information of the value function to improve the sample efficiency of OPE. More specifically, for time-inhomogeneous episodic linear Markov decision processes (MDPs), we propose an algorithm, VA-OPE, which uses the estimated variance of the value function to reweight the Bellman residual in Fitted Q-Iteration. We show that our algorithm achieves a tighter error bound than the best-known result. We also provide a fine-grained characterization of the distribution shift between the behavior policy and the target policy. Extensive numerical experiments corroborate our theory.
Provably Efficient Representation Learning in Low-rank Markov Decision Processes
Jun 22, 2021The success of deep reinforcement learning (DRL) is due to the power of learning a representation that is suitable for the underlying exploration and exploitation task. However, existing provable reinforcement learning algorithms with linear function approximation often assume the feature representation is known and fixed. In order to understand how representation learning can improve the efficiency of RL, we study representation learning for a class of low-rank Markov Decision Processes (MDPs) where the transition kernel can be represented in a bilinear form. We propose a provably efficient algorithm called ReLEX that can simultaneously learn the representation and perform exploration. We show that ReLEX always performs no worse than a state-of-the-art algorithm without representation learning, and will be strictly better in terms of sample efficiency if the function class of representations enjoys a certain mild "coverage'' property over the whole state-action space.
Uniform-PAC Bounds for Reinforcement Learning with Linear Function Approximation
Jun 22, 2021We study reinforcement learning (RL) with linear function approximation. Existing algorithms for this problem only have high-probability regret and/or Probably Approximately Correct (PAC) sample complexity guarantees, which cannot guarantee the convergence to the optimal policy. In this paper, in order to overcome the limitation of existing algorithms, we propose a new algorithm called FLUTE, which enjoys uniform-PAC convergence to the optimal policy with high probability. The uniform-PAC guarantee is the strongest possible guarantee for reinforcement learning in the literature, which can directly imply both PAC and high probability regret bounds, making our algorithm superior to all existing algorithms with linear function approximation. At the core of our algorithm is a novel minimax value function estimator and a multi-level partition scheme to select the training samples from historical observations. Both of these techniques are new and of independent interest.
Risk Bounds for Over-parameterized Maximum Margin Classification on Sub-Gaussian Mixtures
Apr 28, 2021
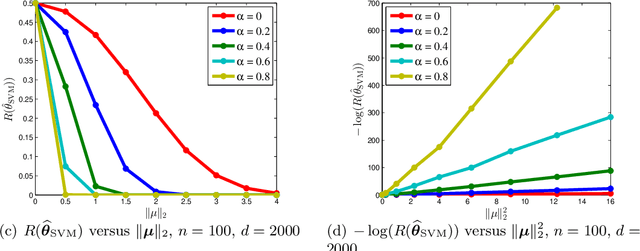
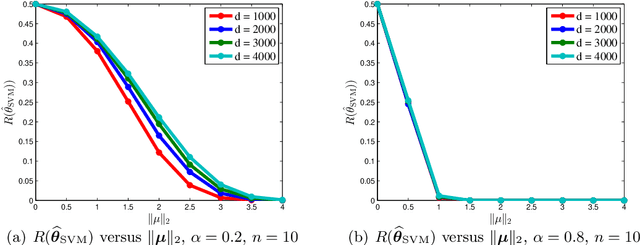
Modern machine learning systems such as deep neural networks are often highly over-parameterized so that they can fit the noisy training data exactly, yet they can still achieve small test errors in practice. In this paper, we study this "benign overfitting" (Bartlett et al. (2020)) phenomenon of the maximum margin classifier for linear classification problems. Specifically, we consider data generated from sub-Gaussian mixtures, and provide a tight risk bound for the maximum margin linear classifier in the over-parameterized setting. Our results precisely characterize the condition under which benign overfitting can occur in linear classification problems, and improve on previous work. They also have direct implications for over-parameterized logistic regression.