 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGI-Bench: A Panoramic Benchmark Revealing the Knowledge-Experience Dissociation of Multimodal Large Language Models in Gastrointestinal Endoscopy Against Clinical Standards
Jan 13, 2026Multimodal Large Language Models (MLLMs) show promise in gastroenterology, yet their performance against comprehensive clinical workflows and human benchmarks remains unverified. To systematically evaluate state-of-the-art MLLMs across a panoramic gastrointestinal endoscopy workflow and determine their clinical utility compared with human endoscopists. We constructed GI-Bench, a benchmark encompassing 20 fine-grained lesion categories. Twelve MLLMs were evaluated across a five-stage clinical workflow: anatomical localization, lesion identification, diagnosis, findings description, and management. Model performance was benchmarked against three junior endoscopists and three residency trainees using Macro-F1, mean Intersection-over-Union (mIoU), and multi-dimensional Likert scale. Gemini-3-Pro achieved state-of-the-art performance. In diagnostic reasoning, top-tier models (Macro-F1 0.641) outperformed trainees (0.492) and rivaled junior endoscopists (0.727; p>0.05). However, a critical "spatial grounding bottleneck" persisted; human lesion localization (mIoU >0.506) significantly outperformed the best model (0.345; p<0.05). Furthermore, qualitative analysis revealed a "fluency-accuracy paradox": models generated reports with superior linguistic readability compared with humans (p<0.05) but exhibited significantly lower factual correctness (p<0.05) due to "over-interpretation" and hallucination of visual features.GI-Bench maintains a dynamic leaderboard that tracks the evolving performance of MLLMs in clinical endoscopy. The current rankings and benchmark results are available at https://roterdl.github.io/GIBench/.
Performance Evaluation, Optimization and Dynamic Decision in Blockchain Systems: A Recent Overview
Nov 29, 2022With rapid development of blockchain technology as well as integration of various application areas, performance evaluation, performance optimization, and dynamic decision in blockchain systems are playing an increasingly important role in developing new blockchain technology. This paper provides a recent systematic overview of this class of research, and especially, developing mathematical modeling and basic theory of blockchain systems. Important examples include (a) performance evaluation: Markov processes, queuing theory, Markov reward processes, random walks, fluid and diffusion approximations, and martingale theory; (b) performance optimization: Linear programming, nonlinear programming, integer programming, and multi-objective programming; (c) optimal control and dynamic decision: Markov decision processes, and stochastic optimal control; and (d) artificial intelligence: Machine learning, deep reinforcement learning, and federated learning. So far, a little research has focused on these research lines. We believe that the basic theory with mathematical methods, algorithms and simulations of blockchain systems discussed in this paper will strongly support future development and continuous innovation of blockchain technology.
Matched Queues with Matching Batch Pair (m, n)
Sep 06, 2020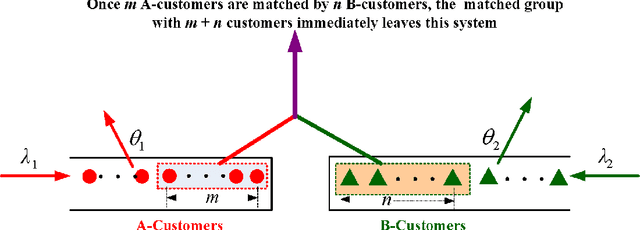
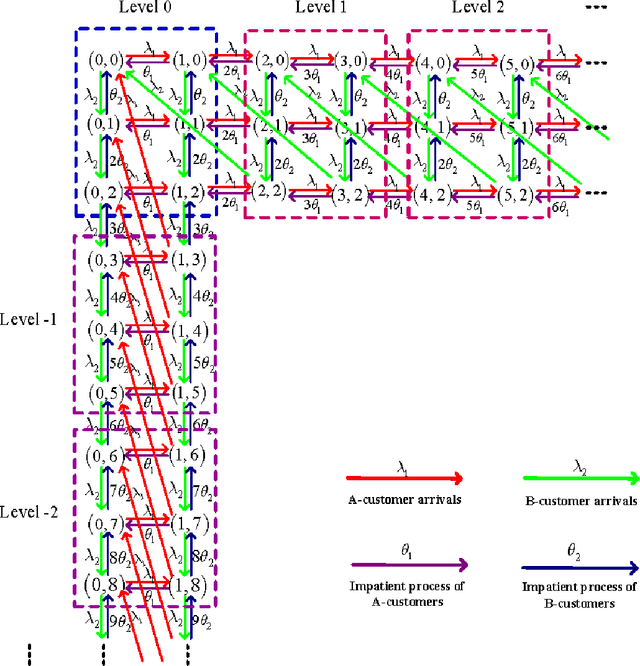
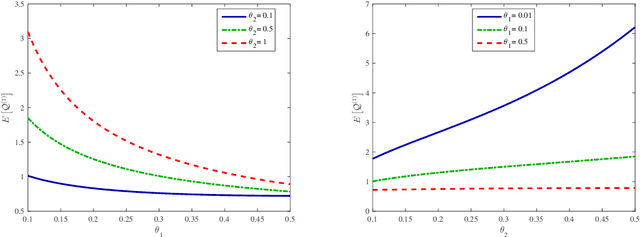
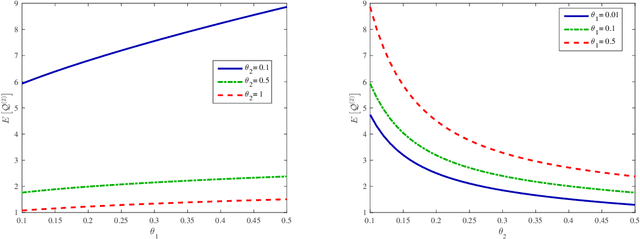
In this paper, we discuss an interesting but challenging bilateral stochastically matching problem: A more general matched queue with matching batch pair (m, n) and two types (i.e., types A and B) of impatient customers, where the arrivals of A- and B-customers are both Poisson processes, m A-customers and n B-customers are matched as a group which leaves the system immediately, and the customers' impatient behavior is to guarantee the stability of the system. We show that this matched queue can be expressed as a novel bidirectional level-dependent quasi-birth-and-death (QBD) process. Based on this, we provide a detailed analysis for this matched queue, including the system stability, the average stationary queue lengthes, and the average sojourn time of any A-customer or B-customer. We believe that the methodology and results developed in this paper can be applicable to dealing with more general matched queueing systems, which are widely encountered in various practical areas, for example, sharing economy, ridesharing platform, bilateral market, organ transplantation, taxi services, assembly systems, and so on.